
在現代可觀測性世界中,告警事件管理是確保服務穩定運行的關鍵,無論是雲端、地端以及各種分佈式系統中,精準即時的告警能夠幫助我們快速發相問題,接著進行故障排除,從而加強我們的服務品質。
在前幾篇文章中,我們深入了介紹有關於告警事件管理和 Prometheus AlertManager 在其監控領域中的各種關鍵概念。然而,隨著雲原生世界的日益複雜和業務規模成長,僅僅依賴 Prometheus AlertManager 還不足以滿足現在系統的多樣化告警管理需求。所以,這時 Grafana 作為一個強大的可視化和監控工具,近幾年來在告警領域中有了長足的進步,接下來就讓我們從各種角度深入探索 Grafana 的告警估能,看看他如何在現代化系統中提供強大的告警管理能力。
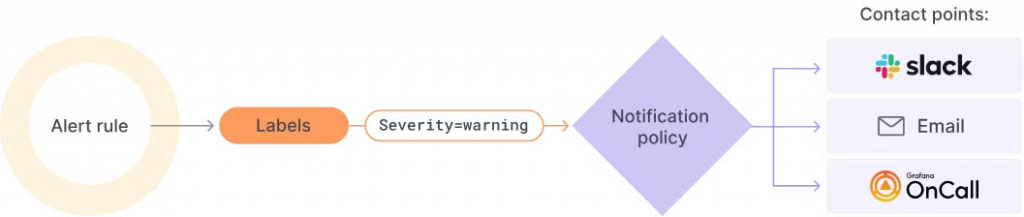
Grafana Alerting 是一套完整且彈性具備的告警系統,現今的 Grafana 11 的 Alerting 系統最早已經在 Grafaan 8 版本中發佈為完全重構版本,作為一個全新功能進行增強原本 Alerting 的不足,提供了一個集中化的告警管理界面,允許我們設定、編輯、查看和管理所有告警規則。無論是監控單一指標還是跨多個資料來源的複雜查詢,Grafana Alerting 都能滿足需求。其主要優勢包括:
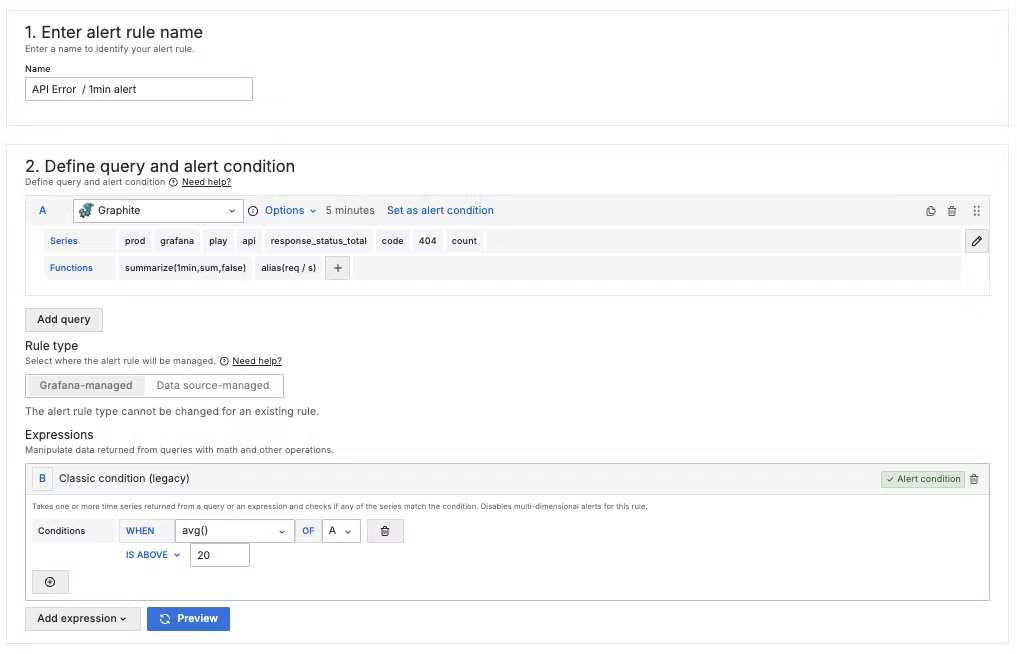
告警規則是 Grafana Alerting 的核心,它們定義了在何種條件下應觸發告警。每個告警規則通常包含以下幾個關鍵部分:
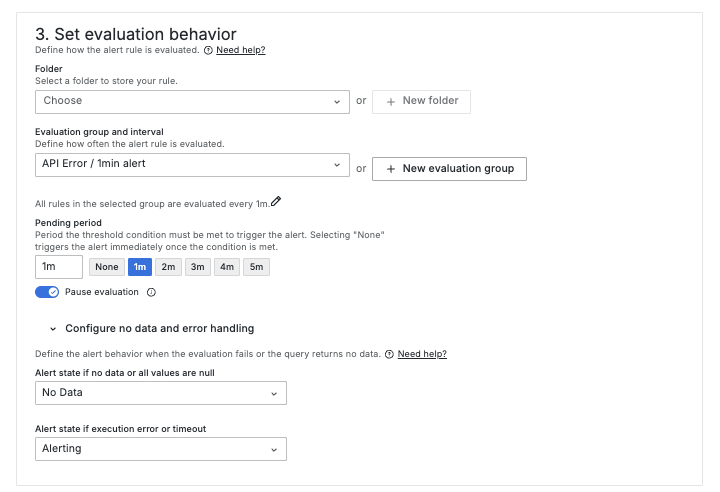
告警評估是 Grafana 監控告警規則的過程。它會按照預設的評估頻率(例如每 1 分鐘)運行我們設置的告警規則,以確定當前系統狀態是否滿足觸發條件。評估的結果將決定告警的狀態,Grafana Alerting 中的告警狀態主要包括:
告警評估還包括評估頻率(Evaluation Interval)等重要概念:
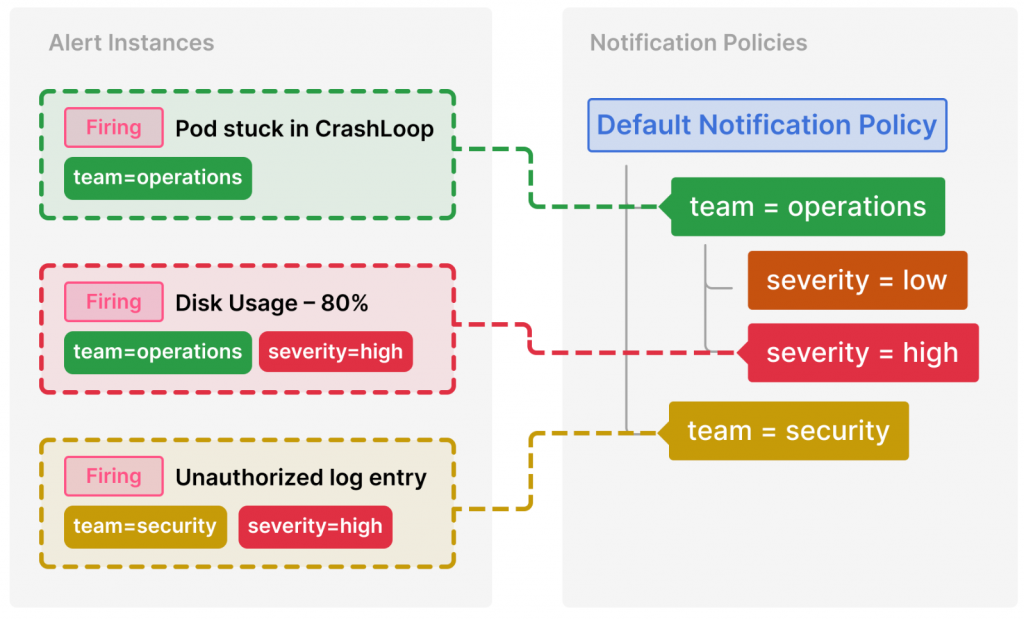
告警通知是將觸發的告警事件傳遞給相關人員或系統的部分。Grafana 提供了靈活的通知管道和分組策略:
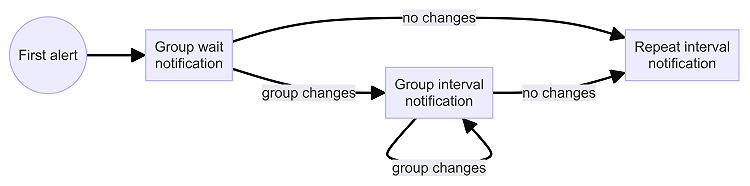
Note: 關於 Grfana Alerting 分組設定的 group 設定,我們已經在先前 Prometheus AlertManager 進階設定中詳細介紹,有興趣的讀者可以參考一下。
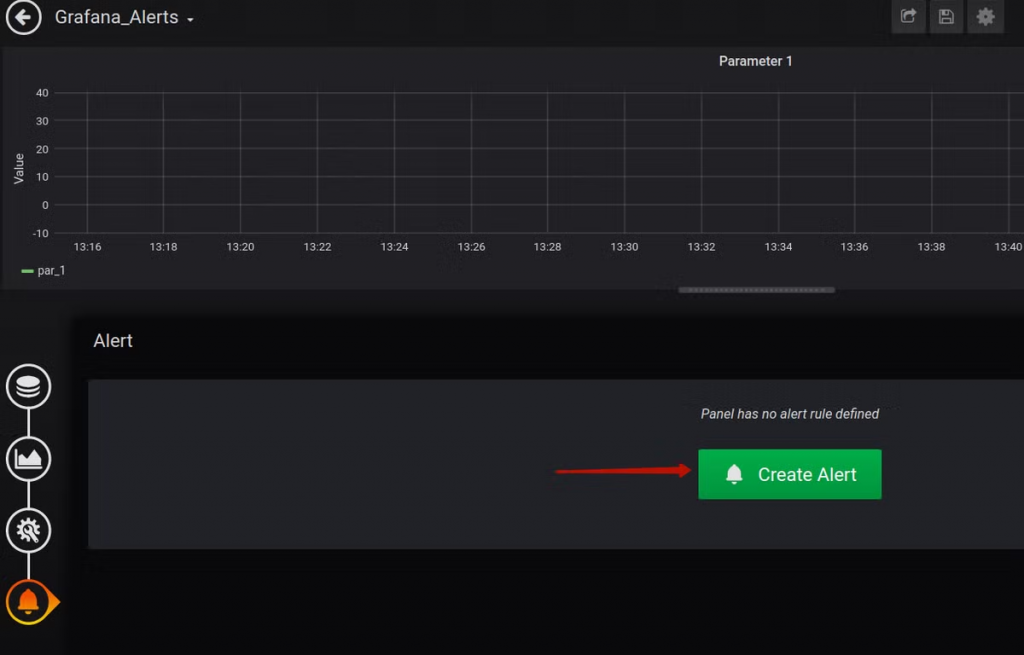
在 Grafana 8 之前,Grafana 的告警系統存在著諸多限制,最明顯的問題是:告警規則必須與 Panel 呈現一對一對應。舉個例子:當我們有上百台主機需要監控時,我們就必須建立上百個 Panel 來設定告警。
這種設計導致告警規則的靈活性和可管理性大打折扣,因為每次想為新的監控指標設置告警時,都必須先創建或編輯對應的面板。這不僅增加了設定的複雜度,還導致告警規則難以統一管理。這個限制一直是社群上被詬病的熱門問題,特別是當監控需求不斷增長、需要更動態和集中化的告警配置時。
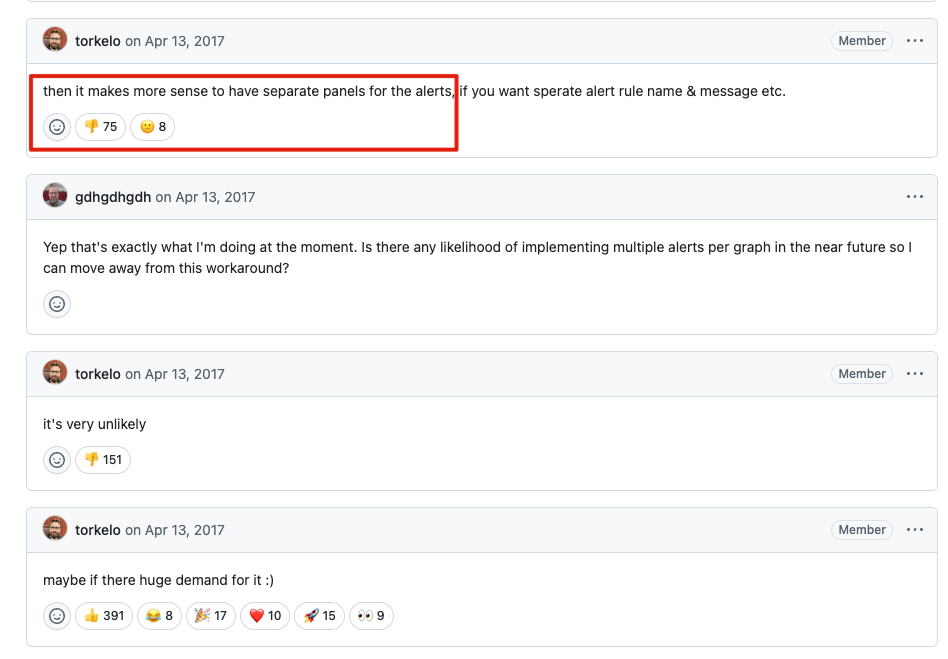
可以看到 Grafana 創世神本神,早在 2017 年就已經收到社群中許多使用者的聲音。

當時,社群上為了解決 Legacy Alerting 的問題,提出了一項呼聲相當高的解決方案,那就是從讓一個 Panel 對應的那一個 Alert 的條件判斷可以套用到 Dashboard 的模版變數,這樣一來,我們就可以透過 Dashboard 的模版變數來動態的套用告警規則,而不需要為每一台主機都建立一個 Panel 和告警規則。
而在社群敲碗了好幾年後,Grafana 團隊終於開始重視這個問題,最終並沒有採用上述的解決方案,而是決定從根本重新設計整個告警系統,實現了告警規則與面板的解耦,進而解決上述的問題。這裡也不得不讚嘆 Grafana 團隊為了解決根本問題不惜重構的決心。

直到 2021 年的 Grafana 8 推出,Next Generation Alerting(當時簡稱 NG Alerting)面世,這成為了現在 Grafana Alerting 系統的前身。這個新系統實現了更加貼近 Prometheus AlertManager 的告警管理方式,以一個告警可以擁有多個告警實例(Alert Instances)的設計,徹底解決了過去告警規則必須與面板一對一的問題。新的告警系統允許告警規則獨立存在,可以針對多個查詢、條件和指標進行統一設置,讓告警配置變得更加靈活和強大。
接著,在 Grafana 9 中,官方宣布全面棄用 Legacy Alerting,鼓勵使用者轉向使用新一代的告警系統。最終,到了 Grafana 11,Legacy Alerting 與舊版的 Angular 元件一起,徹底從 Grafana 的代碼庫中移除。這標誌著 Grafana Alerting 系統的一次巨大轉變,從原本面板綁定的告警方式,進化為現代化、集中化、且高度可擴展的告警管理框架。
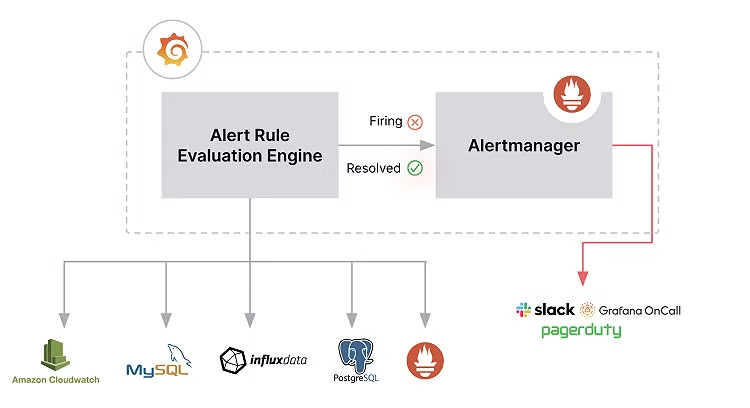
在認識 Grafana Alerting 之前,我們必須要有個明確的概念,那就是 Grafana Alerting 的設計理念是建立在 Prometheus AlertManager 的基礎之上。所以我們可以從 Prometheus AlertManager 的認知中,去理解 Grafana Alerting 的運作方式,並且從多方面的比較細節差異,來進一步加深對他們的認識。
需要再次強調,Grafana Alerting 的架構設計借鑒了 Prometheus AlertManager 的設計。所以,我們可以先將原先 Prometheus 與 AlertManager 的角色分為兩者:
而到了 Grafana Alerting 中,我們可以將其角色分為:
Note: 有些人可能在一開始會對於 Grafana Alerting 同時擔任告警生產者和告警接收者感到困惑,但經過上述的說明後,我們可以知道,Grafana Alerting 的告警生產者是基於 Prometheus 的告警規則進行評估,而告警接收者則是將評估後的告警事件推送給 Grafana AlertManager 進行處理。
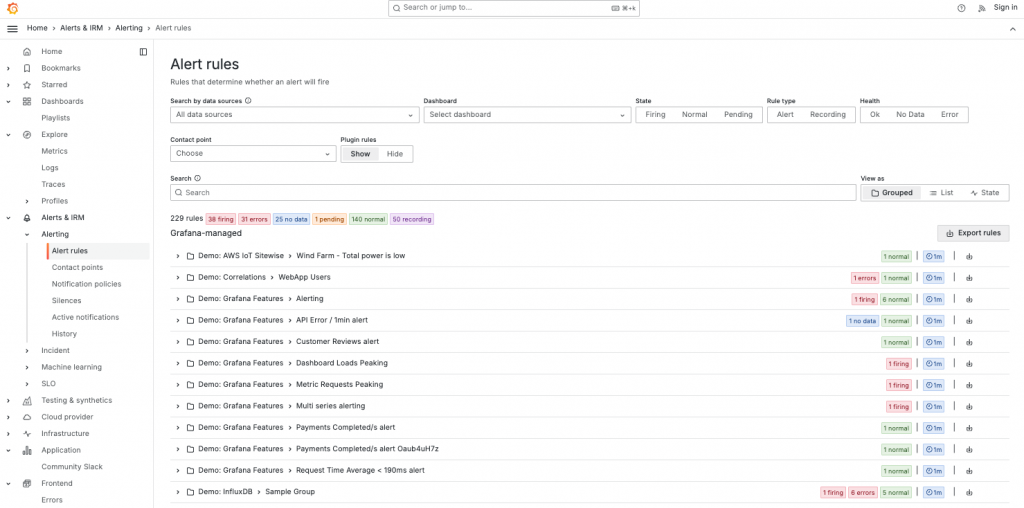
Prometheus AlertManager 沒有內建的完整告警管理使用界面,通常需要與 Prometheus 和其他工具(如 Grafana、Alertmanager UI)配合使用來進行可視化配置和監控。使用者必須通過編寫 YAML 文件來定義和管理告警規則,這對於初學者來說有一定的門檻。
而 Grafana 利用了自身的強項替 Grafana Alerting 提供了一個強大的圖形化界面。使用者可以直接在 Grafana 的 UI 中設置、查看和編輯告警規則,甚至可以在同一界面下查看告警的觸發歷史。這種直觀的界面不僅降低了配置的難度,還讓使用者可以更快速地理解和調整告警策略。此外,Grafana 的告警界面還支援即時預覽功能,讓我們在設置規則時能夠即時查看查詢結果,方便調整告警條件。
在 Prometheus AlertManager 中,告警主要分為「告警中(firing)」和「已解決(resolved)」兩種狀態。這種設計相對簡單,主要用於管理告警的啟動和解除。
然而,在 Grafana Alerting 中,狀態分類變得更加細緻。除了「告警(Alerting)」和「正常(OK)」之外,Grafana 還引入了「暫停(Paused)」、「無資料(No Data)」和「錯誤(Error)」等狀態。這種細緻的狀態劃分讓使用者能夠更精確地監控告警規則的執行情況,並提供更強大的錯誤診斷能力。例如,「無資料」狀態讓使用者在指標缺失時能夠快速反應,而「錯誤」狀態則提示查詢或配置出現問題。
此外,我們可以透過查看告警狀態的 Reason 來了解是哪個原因導致告警失敗。處於這兩個狀態的告警規則會被額外標記以下的 label:
最後,我們可以將這些告警規則當作一般的告警規則來處理,例如設定通知規則和靜默。
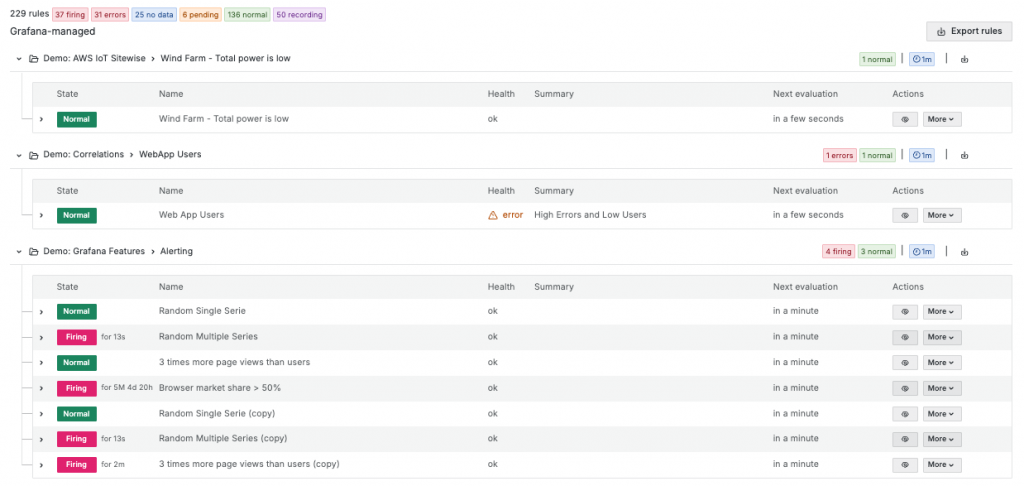
Prometheus AlertManager 的分組概念主要是基於告警的 Label 來實現,這種方式靈活且強大,允許使用者根據 label 的組合將相似的告警歸類,以減少通知噪音。
在這一點上,Grafana Alerting 進一步擴展並簡化了分組的方式。除了繼承 Prometheus 使用 Label 分組的精神外,Grafana 還利用了其原生的 Folder 來進行分組。Grafana 為每個告警規則自動添加了一個名為 grafana_folder 的 Label,這使得告警規則可以根據它所屬的 Folder 進行分類和管理。
這種設計不僅繼承了 Label 分組的靈活性,還使告警與 Folder 結構之間產生了直觀的關聯。這意味著,我們可以在 Grafana 中按照組織 Dashboard 的方式來組織告警規則,並且能更容易地從理解整體告警的分佈情況。
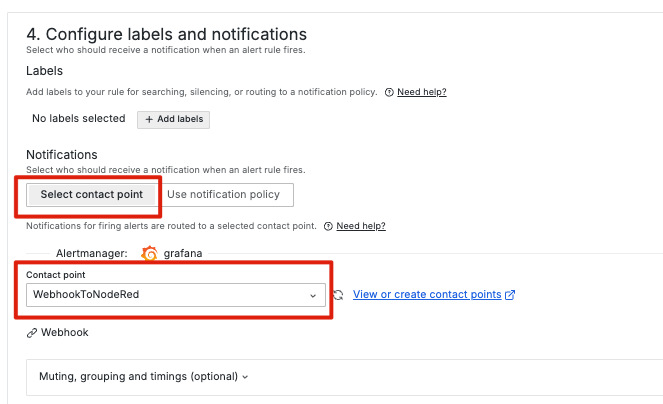
在 Prometheus AlertManager 中,通知策略主要基於通知策略樹(Notification Policy Tree)來構建。這是一種強大但相對複雜的通知策略配置方式,允許使用者通過多層級的標籤匹配和分組來控制告警的發送路徑。這種方法提供了極大的靈活性,但對初學者而言,往往需要花時間去理解如何設置合適的路由樹。
Grafana Alerting 不僅繼承了 Prometheus 的這種通知策略樹的概念,還提供了一個簡化路由(Simplified Routing)功能。這個功能讓使用者可以在 UI 中以更直觀的方式將告警發送到期望的目的地,而不必深入理解複雜的通知策略樹。我們可以直接在告警規則中選擇通知管道,並根據告警的類型、嚴重程度等條件,設置簡單的路由規則。這種方式使得告警通知配置變得更加容易,特別適合於多資料來源、多團隊協作的環境ƒ。
這種 Simplified Routing 讓使用者能夠快速配置並將告警準確地送達至合適的通知管道(Contact Point),大幅降低了配置通知策略的門檻,使 Grafana 在管理和傳達告警時更加直觀和便捷。
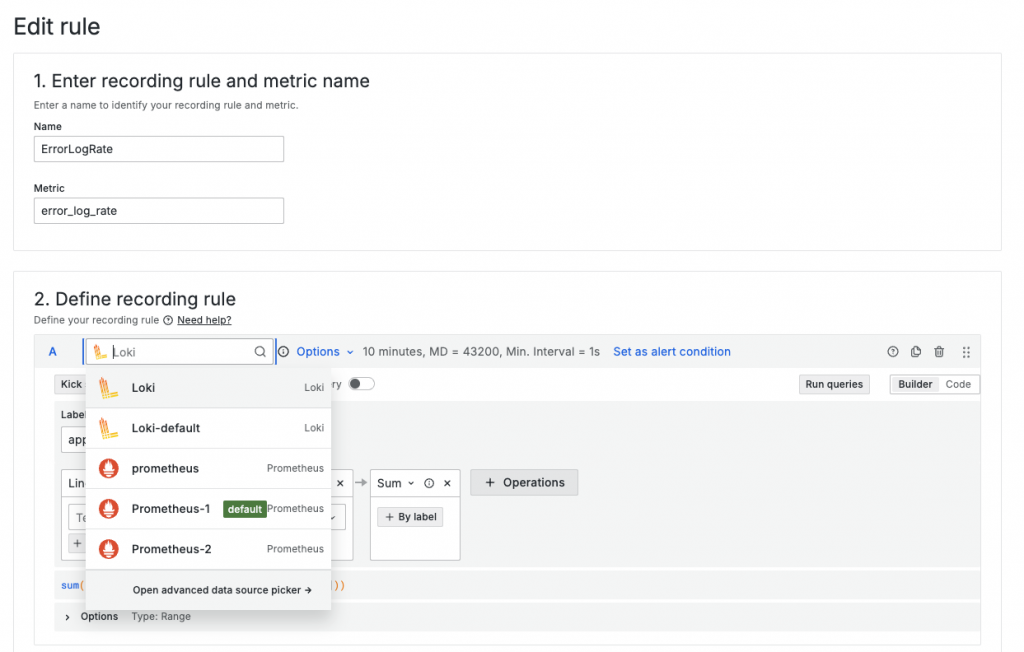
Recording Rules 在 Prometheus 中是一種提前計算和存儲指標的方式,用於減少查詢的計算負荷,特別是在處理大量數據時。Prometheus 支援直接在 YAML 文件中定義 Recording Rules,並以此為基礎設置告警規則。
相比之下,Grafana Alerting 雖然支援 Prometheus 的 Recording Rules,但並不局限於此。由於 Grafana 可以使用多種資料來源(如 InfluxDB、Loki、Elasticsearch 等),它的告警機制並不依賴 Prometheus 的 Recording Rules。這讓 Grafana 能夠在多元化的監控場景中靈活運作,將不同資料來源的查詢結果統一用於告警設置。此外,Grafana 支援即時查詢,無需提前計算指標,這為即時監控提供了更大的靈活性。
關於告警事件系統的觀念其實是相當複雜的,尤其是像是 Grafana Alerting 這種結合了多種資料來源的告警系統,更是需要對 Prometheus 有相當程度的理解才能夠完整的發揮其功能。
不過,還好我們在先前的文章已經透過了解 Prometheus AlertManager 的設定,對於告警事件系統有了基本的認識,這對我們認識 Grafana Alerting 的設定有很大的幫助,並且我們更進一步了解了 Grafana Alerting 的強大之處。
接下來,我們將會進入實戰部分,我們將會介紹如何透過 Grafana Alerting 來探討怎麼樣才算是一個「好的」告警設定。

