
我們今天將幾個關鍵功能補齊,重點如下:
程式碼:https://github.com/class83108/DocuMind/tree/celery
因為有閱讀到這裡篇章的讀者應該都對Django有了比較熟悉的認知,有些步驟我就不展示程式碼出來避免篇幅過長
我們先創建超級用戶以進入後台,並且將article透過admin.py註冊在後台中
# articles.admin.py
@admin.register(Article)
class ArticleAdmin(admin.ModelAdmin):
list_display = ("title", "author", "created_at", "updated_at")
search_fields = ("title", "content")
list_filter = ("author", "created_at")
此時我們已經能夠新增文章
但是我們需要自定義一個文章新增頁,因為我們會希望該頁能在上傳PDF檔案的同時:
而在我們自定義這個頁面到admin後台前,我們先來處理第一步:建立API與其功能
poetry add "pdfminer.six[image]"
poetry add djangorestframework
# documind.urls.py
urlpatterns = [
path("admin/", admin.site.urls),
path("articles/", include(("articles.urls", "articles"), namespace="articles")),
path("api/", include(("api.urls", "api"), namespace="api")),
]
# api.urls.py
urlpatterns = [path("upload-pdf/", PDFUploadView.as_view(), name="upload-pdf")]
from django.http import HttpResponse
from pdfminer.high_level import extract_text
from rest_framework import views, response, status
import io
import re
class PDFUploadView(views.APIView):
def post(self, request):
pdf_file = request.data.get("pdf_file")
if not pdf_file:
return response.Response(
{"error": "No PDF file provided"}, status=status.HTTP_400_BAD_REQUEST
)
try:
pdf_content = pdf_file.read()
text = extract_text(io.BytesIO(pdf_content))
# 清理文本
text = self.clean_text(text)
# 直接返回文本内容,而不是字典
return HttpResponse(text, content_type="text/plain")
except Exception as e:
return response.Response(
{"error": "Error processing PDF file"},
status=status.HTTP_400_BAD_REQUEST,
)
def clean_text(self, text):
# 删除特殊字符
text = re.sub(r"[^\w\s\.\,\?\!]", "", text)
# 將連續的換行符替換為單個換行符
text = re.sub(r"\n+", "\n", text)
# 删除行首和行尾的空白字符
text = "\n".join(line.strip() for line in text.split("\n"))
return text
首先我們拿到了上傳的pdf檔案後:
pdf_file.read():讀取文檔中的內容,轉成Bytes返回io.BytesIO(pdf_content):創建一個像文件一樣操作的記憶體緩衝區,可以在不需要儲存文件的狀況下進行像文件操作的方式處理extract_tex:接收檔案路徑或是類檔案對象,最後返回解析後的字符串clean_text:因為我們暫時沒有想要處理特別複雜內容的PDF,為了能簡單呈現內容,因此只是進行簡單處理,如果想要做出更實際的應用,例如能處理圖表等,這邊是需要著重優化的部分
既然有API了,我們就需要在後台中註冊這個自訂義方法
# articles.admin.py
@admin.register(Article)
class ArticleAdmin(admin.ModelAdmin):
list_display = ("title", "author", "created_at", "updated_at")
search_fields = ("title", "content")
list_filter = ("author", "created_at")
def get_urls(self):
urls = super().get_urls()
custom_urls = [
path(
"create-with-pdf/",
self.admin_site.admin_view(self.create_with_pdf_view),
name="article_create_with_pdf",
),
]
return custom_urls + urls
def create_with_pdf_view(self, request):
context = dict(
self.admin_site.each_context(request),
title="Create Article with PDF Upload",
)
if request.method == "GET":
return render(request, "admin/article_create_with_pdf.html", context)
def changelist_view(self, request, extra_context=None):
extra_context = extra_context or {}
extra_context["show_create_with_pdf"] = True
return super().changelist_view(request, extra_context=extra_context)
changelist_view:這個方法是要讓我們之後重寫change_list模板時,能夠透過show_create_with_pdf這個上下文,來只讓文章列表會出現我們自定義連結的連結。如果看不懂這邊在幹嘛的話,請回去看Django in 2024: Django Admin二次開發,打造屬於你的後台。雖然用的方法不同,但是邏輯是相同的get_urls:獲取模板中所有連結,也因此我們能把我們的自定義連結與視圖放入。情可以看官方文檔
create_with_pdf_view:首先添加自定義的變數供模板渲染
context = dict(
self.admin_site.each_context(request),
title="Create Article with PDF Upload",
)
提供我們自定義的模板路徑
if request.method == "GET":
return render(request, "admin/article_create_with_pdf.html", context)
接著建立相關的模板
跟show_create_with_pdf變數來決定是否顯示我們自定義的頁面
# templates/admin/change_list.html
{% extends "admin/change_list.html" %}
{% load i18n admin_urls %}
{% block object-tools-items %}
{% if show_create_with_pdf %}
<li>
<a href="{% url 'admin:article_create_with_pdf' %}" class="addlink">
{% translate "Create with PDF" %}
</a>
</li>
{% endif %}
{{ block.super }}
{% endblock %}
{% extends "admin/base_site.html" %}
{% load static %}
{% block extrahead %}
{{ block.super }}
<link rel="stylesheet" href="/static/css/article_form.css">
<script src="https://unpkg.com/htmx.org@2.0.3"></script>
{% endblock %}
{% block content %}
<form method="POST" enctype="multipart/form-data">
{% csrf_token %}
<div class="container">
<div class="row">
<div class="form-label"><label for="title">Title:</label></div>
<div class="form-content"><input type="text" id="title" name="title" required></div>
</div>
<div class="row">
<div class="form-label">
<label for="pdf_file">Upload PDF:</label>
</div>
<div class="form-content"><input type="file" id="pdf_file" name="pdf_file" accept="application/pdf"
hx-post="{% url 'api:upload-pdf' %}"
hx-trigger="change"
hx-target="#article_content"
hx-swap="innerHTML"
hx-encoding="multipart/form-data"></div>
</div>
<div class="row">
<div class="form-label"><label for="article_content">Content:</label></div>
<div class="form-content"><textarea id="article_content" name="content" rows="10" cols="50"></textarea></div>
</div>
</div>
<button class="submit_btn" type="submit">Create Article</button>
</form>
<div id="result"></div>
{% endblock %}
這邊因為我們想要點擊上傳Upload PDF這個input後,能夠直接使用我們剛剛寫的API:PDFUploadView
這邊用htmx的方式來處理AJAX的部分,詳細的使用方法可以直接去看官方文檔
使用htmx可以在不寫JavaScript的方式下,直接透過定義html元素的attributes來做出AJAX與CSS轉場或是WebSockets的功能
hx-post:定義了AJAX的POST請求路徑
hx-trigger:設定了監聽元素的觸發事件
hx-target:我們最後拿到API資料後希望渲染的元素,這邊選擇content元素
hx-swap:我們是希望改寫目標內部的innerHTML而不是整個取代目標元素的HTML結構
hx-encoding:因為我們是上傳檔案,所以需要設定multipart/form-data
當我們上傳PDF檔案後,就會發出API請求,經過解析後渲染到內容上
既然拿到內容了,就需要儲存文章
@admin.register(Article)
class ArticleAdmin(admin.ModelAdmin):
...
def create_with_pdf_view(self, request):
...
if request.method == "GET":
return render(request, "admin/article_create_with_pdf.html", context)
if request.method == "POST":
title = request.POST.get("title")
content = request.POST.get("content")
author = request.user
article = Article.objects.create(
title=title, content=content, author=author
)
return redirect("admin:articles_article_changelist")
可以拿專案目錄的資料來進行上傳
https://github.com/class83108/DocuMind/tree/celery/documind/pdf_files
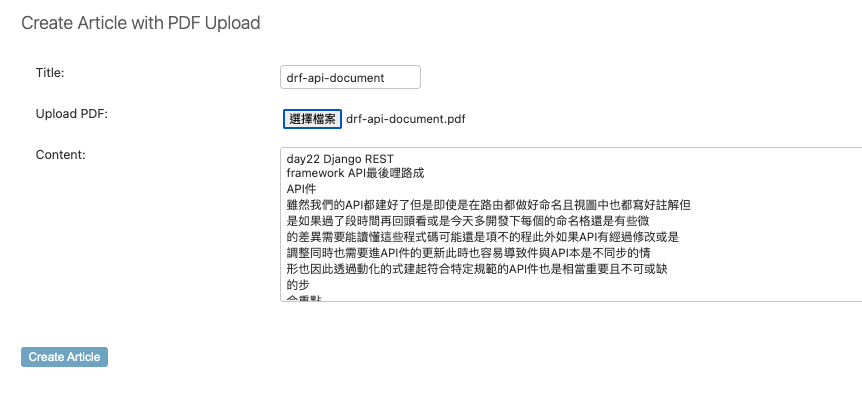
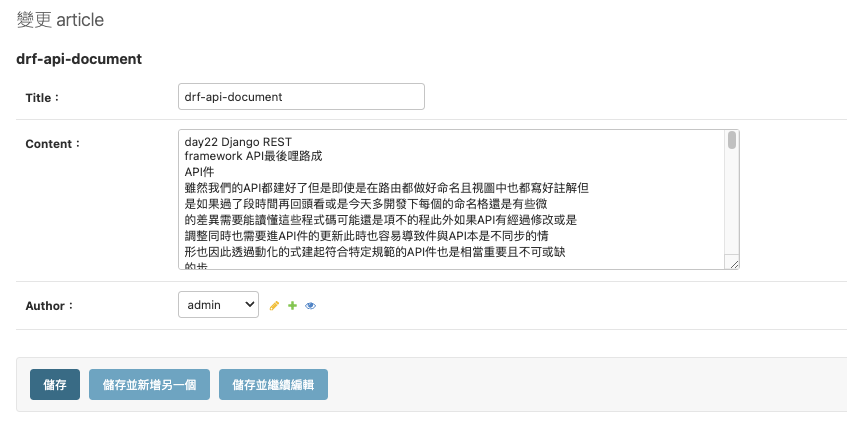
至此確認了PDF能夠轉成字符串,並且能夠順利的儲存文章
因為LangChain改版的速度真的蠻快的,幸好相關文件也是持續有在更新
並且在使用一些要被棄用的方法時,系統也會進行提醒與警告
poetry add langchain
poetry add langchain-chroma
poetry add langchain-openai
poetry add langchain_community
在上一篇Django Channels、Async 和 Celery 的協同之舞: 認識向量資料與Celery有提到轉換成向量資料有不同的算法。我們打算配置OpenAI的GPT來進行計算,因此我們需要配置OpenAI的API key。網路上應該有很多資料可以知道如何拿到API key,因此就不展開說明
# settings.py
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
我們在documind目錄下建立vectorsore.py
# vectorstore.py
from django.conf import settings
from langchain_openai import OpenAIEmbeddings
from langchain_chroma import Chroma
import os
# 初始化 OpenAI embeddings
embeddings = OpenAIEmbeddings(
api_key=settings.OPENAI_API_KEY, model="text-embedding-3-large"
)
persist_directory = os.path.join(settings.BASE_DIR, "chroma_db")
vector_store = Chroma(
persist_directory=persist_directory, embedding_function=embeddings
)
def get_vectorstore():
return vector_store
我們先建立出轉換資料變成向量資料,並且儲存到chroma的流程
from celery import shared_task
from django.conf import settings
from langchain.schema import Document
from langchain.text_splitter import RecursiveCharacterTextSplitter
from documind.vectorstore import get_vectorstore
from .models import Article
import uuid
@shared_task
def process_and_store_article(article_id: int) -> None:
try:
article = Article.objects.get(id=article_id)
# 獲取全局 Chroma 客戶端
vectorstore = get_vectorstore()
# 獲取該文章的所有現有文檔 ID
all_docs = vectorstore.get(where={"article_id": article.id})
if all_docs and all_docs.get("ids"):
vectorstore.delete(ids=all_docs["ids"])
# 文本準備
text = article.content
# 文本分割
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=100,
length_function=len,
)
chunks = text_splitter.split_text(text)
# 轉換article.update_at為字符串
updated_at = article.updated_at.strftime("%Y-%m-%d %H:%M:%S")
# 創建 Document 對象列表
documents = [
Document(
page_content=chunk,
metadata={
"article_id": article.id,
"title": article.title,
"chunk_index": i,
"updated_at": updated_at,
},
)
for i, chunk in enumerate(chunks)
]
# 生成唯一 ID
uuids = [str(uuid.uuid4()) for _ in range(len(documents))]
# 將文章添加到現有的向量存儲中
vectorstore.add_documents(documents=documents, ids=uuids)
except Exception as e:
print(f"Error processing article: {str(e)}")
raise e
既然我們想要請Celery操作的任務完成了,就把它納入admin中的視圖中
# articles.admin.py
@admin.register(Article)
class ArticleAdmin(admin.ModelAdmin):
...
def create_with_pdf_view(self, request):
context = dict(
self.admin_site.each_context(request),
title="Create Article with PDF Upload",
)
if request.method == "GET":
return render(request, "admin/article_create_with_pdf.html", context)
if request.method == "POST":
title = request.POST.get("title")
content = request.POST.get("content")
author = request.user
article = Article.objects.create(
title=title, content=content, author=author
)
try:
process_and_store_article.apply_async((article.id,))
except Exception as e:
article.delete()
context["error"] = str(e)
return render(request, "admin/article_create_with_pdf.html", context)
return redirect("admin:articles_article_changelist")
def save_model(self, request, obj, form, change):
super().save_model(request, obj, form, change)
try:
process_and_store_article.apply_async((obj.id,))
except Exception as e:
print(f"Error processing article: {str(e)}")
obj.delete()
self.message_user(request, f"Error processing article: {str(e)}")
但是如果運行後遇到sqlite3.OperationalError: attempt to write a readonly database
可以修改資料夾與chroma的權限
chmod 775 chroma_db
chmod 664 *.sqlite3
並且因為我們沒有在settings.py中配置線程提高併發能力,有兩種方式:
CELERY_WORKER_CONCURRENCY = xx
celery -A documind worker --pool=threads -l info
我們可以再重新上傳一篇,或是點擊剛剛建立好的文章重新進行儲存
我們能看到任務卻時被執行成功
[2024-10-11 22:13:39,817: INFO/MainProcess] Task articles.tasks.process_and_store_article[7e1b5b09-6749-4136-819c-4e44637432f5] received
[2024-10-11 22:13:40,484: INFO/MainProcess] HTTP Request: POST https://api.openai.com/v1/embeddings "HTTP/1.1 200 OK"
[2024-10-11 22:13:41,359: INFO/MainProcess] Task articles.tasks.process_and_store_article[7e1b5b09-6749-4136-819c-4e44637432f5] succeeded in 1.5363231670344248s: None
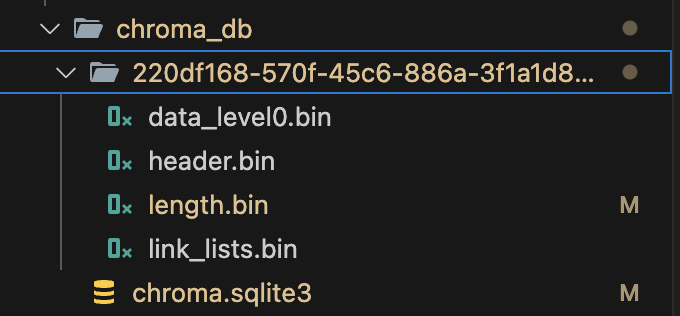
並且去看chroma確實有載入資料
目前的需求是:
用戶輸入他想知道有關於文檔的問題,最後拿到相對應的答案
因此流程如下:
因此我們可以知道這一個流程一樣得讓Celery完成,並且我們知道第一次拿到會是任務id而不會是真的答案。所以我們需要做另一個視圖來讓客戶端用這個id去拿到最終的結果
# articles.tasks.py
from celery import shared_task
from django.conf import settings
from langchain.prompts import PromptTemplate
from langchain.schema import StrOutputParser
from langchain_openai import OpenAI
from documind.vectorstore import get_vectorstore
@shared_task
def search_documents_and_answer(query: str, num_results: int = 5) -> dict:
vectorstore = get_vectorstore()
# 執行相似性搜索
results = vectorstore.similarity_search_with_score(query, k=num_results)
print(f"Found {len(results)} results")
if len(results) == 0:
return {"query": query, "answer": "No results found", "results": []}
# 格式化結果
formatted_results = []
context = ""
for doc, score in results:
formatted_results.append(
{"content": doc.page_content, "metadata": doc.metadata, "score": score}
)
context += doc.page_content + "\n\n"
# 初始化語言模型
llm = OpenAI(temperature=0, openai_api_key=settings.OPENAI_API_KEY)
# 創建提示模板
prompt = PromptTemplate(
input_variables=["context", "query"],
template="根據以下信息回答問題:\n\n{context}\n\n問題: {query}\n\n答案:",
)
# 建立鏈 - 輸入提示,語言模型,輸出解析器
chain = prompt | llm | StrOutputParser()
# 調用鏈 - 將上下文和查詢作為輸入取代得答案
answer = chain.invoke({"context": context, "query": query})
return {
"query": query,
"answer": answer,
"results": formatted_results,
}
接著去建立視圖
# articles.views.py
@method_decorator(csrf_exempt, name="dispatch")
class VectorSearchView(View):
def post(self, request):
# 解析請求數據
query = request.POST.get("query")
num_results = request.POST.get("num_results", 5)
# 調用 Celery 任務
task_result = search_documents_and_answer.apply_async((query, int(num_results)))
# 不能直接返回 task_result,因為使用apply_async所以它是一個 AsyncResult 對象
return JsonResponse({"task_id": task_result.id})
@method_decorator(csrf_exempt, name="dispatch")
class TaskResultView(View):
def get(self, request, task_id):
task_result = AsyncResult(task_id)
if task_result.ready():
result = task_result.result
return JsonResponse({"status": "completed", "result": result})
else:
return JsonResponse({"status": "pending"})
並且建立路由
# articles.urls.py
urlpatterns = [
path("search/", VectorSearchView.as_view(), name="article-search"),
path("task-result/<str:task_id>/", TaskResultView.as_view(), name="task_result"),
]
最後我們在Postman進行測試,先使用問句以及我們想要看與問題相似的文檔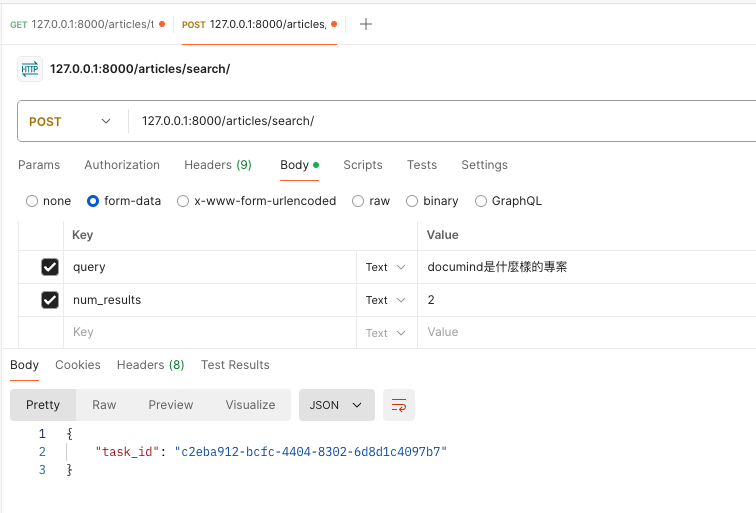
拿到任務id後來確認任務的結果
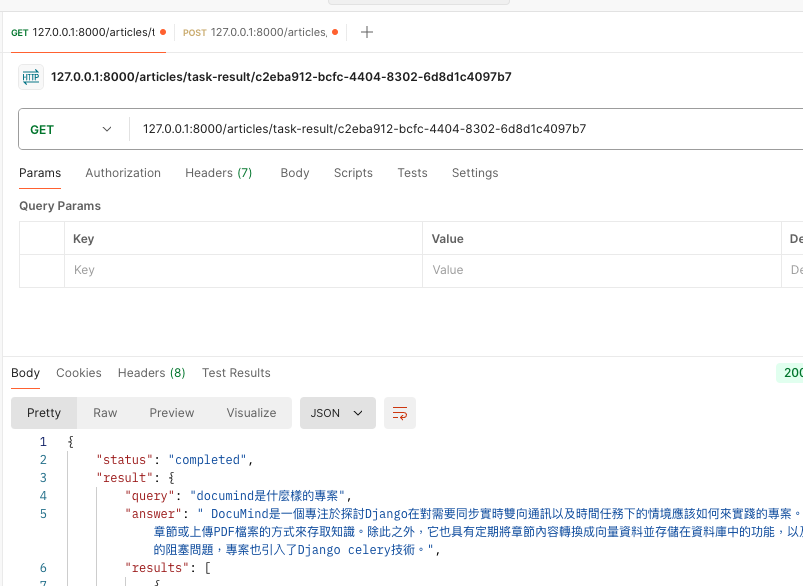
理論上ChatGPT是不會知道這個專案內容,但是可以看到結果有返回我們想要的答案!這個專案的核心功能確認沒有問題。並且我們也能從結果中看到從向量資料庫拿到的文檔
{
"status": "completed",
"result": {
"query": "documind是什麼樣的專案",
"answer": " DocuMind是一個專注於探討Django在對需要同步實時雙向通訊以及時間任務下的情境應該如何來實踐的專案。它的主要功能是建立一個知識庫,讓用戶可以通過輸入相關的章節或上傳PDF檔案的方式來存取知識。除此之外,它也具有定期將章節內容轉換成向量資料並存儲在資料庫中的功能,以及提供實時通訊和維持通訊機制的能力。為了克服時間任務處理的阻塞問題,專案也引入了Django celery技術。",
"results": [
{
"content": "適場景\r\n建專案\r\n專案介紹DocuMind\r\n來為家介紹這個章系列的主DocuMind取名Document與Mind的結合\r\n這個專案最主要的功能就是個的知識庫具有以下功能\r\nday23 Django ChannelsAsync 和 Celery 的協同之舞 DocuMind專案介紹1\f戶能夠輸相關的章或是透過上傳PDF檔案的式到知識庫中\r\n知識庫除了會將檔存在資料庫之外也會定期將章內容傳到向量資料庫中轉換\r\n成向量資料\r\n戶能傳訊息給知識庫知識庫根據訊息來從向量資料庫返回接近的答案返回給客戶\r\n端\r\n撇除轉換成向量資料跟判斷戶訊息與庫的相關程度之外我們需要來看下我們需\r\n要克服哪些技術的需求\r\n定期將資料庫資料轉換成向量資料除了需要安排排程處理之外這種時間的任務\r\n勢必會期阻塞我們的服務\r\n戶跟服務端這樣來回交互訊息勢必要有實時通訊以及維持通訊的機制\r\n服務端收到訊息經過些業務處理最後返回相關資料給客戶端如果只單純的\r\n同步處理流程除了造成阻塞之外耗時也會更可能需要些同步的段\r\n綜上所述我們勢必要引些新技術了\r\n使Django celery來幫助我們處理時間任務",
"metadata": {
"article_id": 5,
"chunk_index": 1,
"title": "documind intro",
"updated_at": "2024-10-11 14:13:39"
},
"score": 0.855492222983097
},
{
"content": "day23 Django ChannelsAsync\r\n和 Celery 的協同之舞 DocuMind\r\n專案介紹\r\n先前章的重點放在Django對於資料庫的ORMObject Relational Mapping後台應\r\n還有Django REST frameworkDRF等API操作這些主要都是單純的數據更\r\n新單向的服務器推送需求但是如果想要Django進其他的Web應我們需要更\r\n好的解決案與應\r\n在這個系列章中我們會透過DocuMind這個專案來探討Django在對需要同步\r\n實時雙向通訊以及時間任務下的情境應該如何來進實踐\r\n今重點\r\n專案介紹DocuMind\r\n探討啟動Django專案的不同起式\r\nDjango runserver\r\nWSGI Web Server Gateway Interface啟動Django\r\nASGI Asynchronous Server Gateway Interface啟動Django\r\n適場景\r\n建專案\r\n專案介紹DocuMind\r\n來為家介紹這個章系列的主DocuMind取名Document與Mind的結合",
"metadata": {
"article_id": 5,
"chunk_index": 0,
"title": "documind intro",
"updated_at": "2024-10-11 14:13:39"
},
"score": 1.1823237889579223
}
]
}
}
我們雖然沒有在prompt的部分下功夫,來讓LLM能夠更完美的成任務
但是我們先確認向量資料庫有找到幾筆資料後再進行問答,避免LLM可能有出現幻覺的狀況
如果在AI應用上想要進一步優化有幾個面向:
但是因為畢竟主角是在Django身上,這部分的優化就留給未來去處理了
我們把整個專案的核心功能完成了!
不過這樣使用API操作的用戶體驗實在說不上好,用戶應該更希望直接拿到返回的資料
因此在下一個篇章中,我們會納入channels,來提升整體用戶體驗
