
📝 TL;DR > 本文示範如何在 M3 本機完成 LoRA 微調(訓練 30 分鐘),採用 CPU 示範確保通用性,M3 可用 MPS/MLX 加速。
適合「資料不能上雲」的離線場景。
💡 術語說明:
本文使用「微調(Fine-tuning)」指在預訓練模型基礎上進行 LoRA 調整。
部分段落為了語感順暢,可能會混用「訓練」一詞(如「訓練腳本」「訓練時間」),
但實際上指的都是「微調」流程,並非從零開始訓練模型。
在 Day23 - 讓 LLM 應用與時俱進:RAG 增量 × Fine-tuning 部署與治理指南 我們談到「讓 LLM 應用與時俱進」的三大策略:
讓我們重溫 Day23 的核心概念:什麼時候需要本地微調?
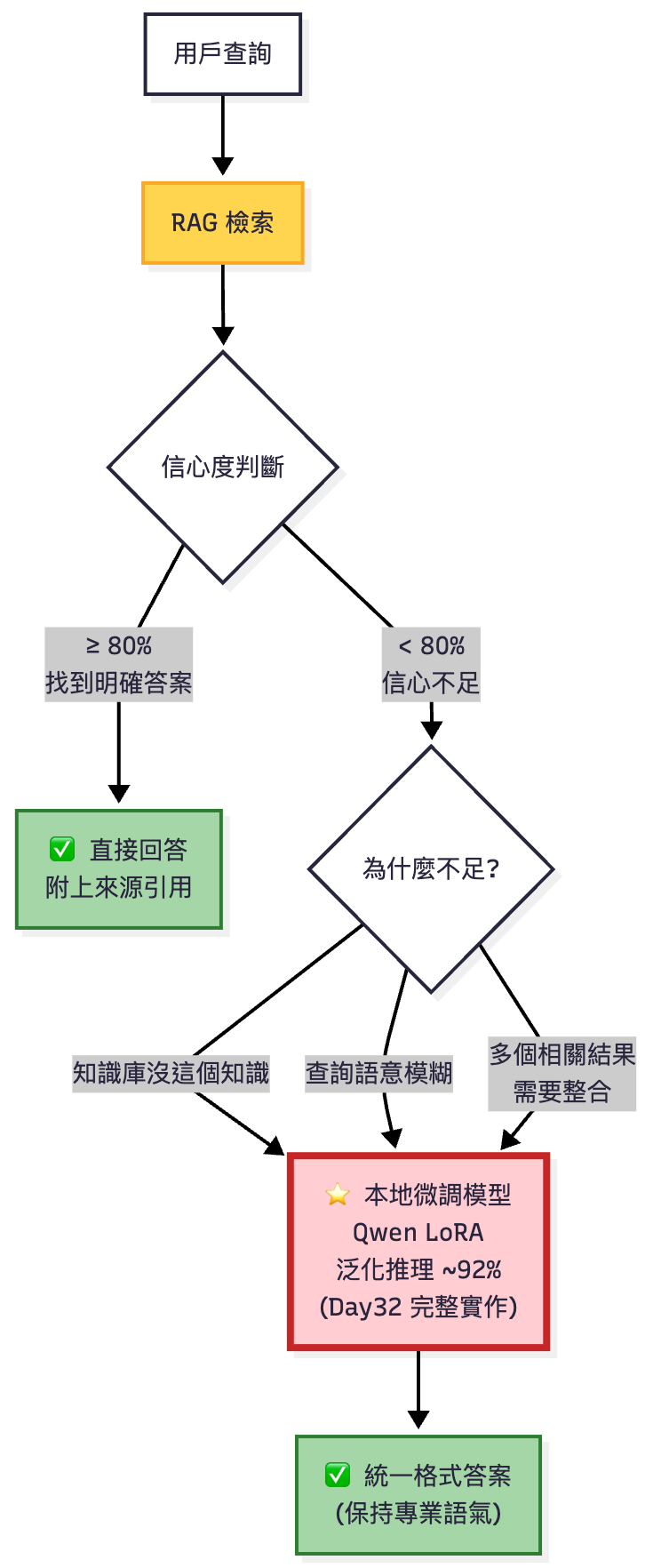
RAG 檢索不足時的 Fallback 策略:本地微調模型(Qwen LoRA)接手處理,今天將完整實作
當時我們在 Day 23 提到:
如果你用的是自建/開源模型,可以用 LoRA 做輕量化微調...
建議把這段當「資料設計與流程概念」來看。
今天就來補完這最後一塊拼圖:完整實作本機 LoRA 微調流程。
✅ 你的公司有以下需求:
❌ 這篇不適合:
📖 系列定位:
不是教你成為 ML 工程師,而是讓你:
💡 80/20 法則依然成立:
「LoRA」其實是 Low-Rank Adaptation of Large Language Models 的縮寫。
意思是「大型語言模型的低秩適應」。
| 名稱部分 | 含義 | 為什麼取這樣 |
|---|---|---|
| Low-Rank (低秩) | 指用低維度矩陣(rank 很小)來近似原本龐大的權重矩陣。 | 這樣可以只訓練少量參數(幾百萬 vs 幾十億),節省算力與記憶體。 |
| Adaptation (適應) | 指模型在保持原始權重不變的情況下,學習特定任務的調整。 | 不需要重新訓練整個模型,只「適應」新的資料。 |
| LoRA | 就是這個方法的縮寫。 | 方便記,也像人名一樣親切(很多人會誤以為是人名 😆)。 |
假設你有一個大模型 (LLM) = 🎹 一台史坦威自動演奏鋼琴。
要讓它彈出不同風格(爵士、古典、搖滾),你可以:
LoRA 就是在原模型權重 W 上加上「低秩矩陣分解」的補丁:
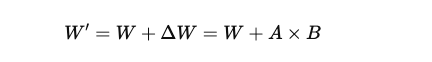
其中 A、B 是小矩陣(rank 很低),所以省很多資源。
LoRA 這個名字出自 2021 年的論文
"LoRA: Low-Rank Adaptation of Large Language Models"
作者:Edward J. Hu et al., Microsoft Research.
他們想解決 fine-tuning LLM 太貴 的問題,
於是提出這種低秩分解方法,只訓練幾個小層參數就能達到效果。
在 Day 23,我們比較過 API Fine-tuning vs. LoRA:
| 面向 | OpenAI Fine-tuning (Day 23 已做) | LoRA 自建 (今天實作) |
|---|---|---|
| 基礎設施 | 雲端處理(Model:gpt-4o-mini) |
需本機 GPU/M3 晶片 |
| 推理成本 | $0.19/次 (64K tokens) | $14(A10 4h) 或 M3 免費 |
| 適用情境 | 快速上線、語氣統一 | 離線自訓、法遵需求 |
| 資料隱私 | 上傳到 OpenAI | 完全本地,不外洩 |
| 模型控制 | 黑盒 | 可調整參數、Merge 權重 |
編按:本比較表以範例訓練資料集作為基準。
今天的重點場景:
👉 Day 23 用 OpenAI API 解決 80% 場景;今天用 LoRA 補完剩下 20% 的硬需求。
在自建或開源模型場景,我們可以用 LoRA 做輕量化再訓練,快速學會企業的語氣、規範或格式。
只用雲端 API 的讀者:可以跳過實作細節,重點看「資料格式設計」
需要離線訓練的讀者:請繼續往下,本篇會用 M3 完整示範
想理解原理的讀者:這是最好的學習機會,建議實際操作一遍
LoRA 可以幫助你理解「再訓練」的底層流程:
instruction-tuning 資料:定義模型的「輸入-輸出」範本💡 即使你不自己訓練,也能用這套想法來設計資料,交給供應商的 Fine-tune API。
| 模型 | 參數量 | 神經網路架構類型[註1] | 中文品質 | M3 24GB訓練時間 | 推薦場景 | 推薦度 |
|---|---|---|---|---|---|---|
| Flan-T5 base | 250M | Encoder-Decoder | ⭐⭐ | 10 分鐘 | 英文場景 | ❌ |
| mT5 base | 580M | Encoder-Decoder | ⭐⭐⭐⭐⭐ | 12-15 分鐘 | 中文 FAQ/翻譯/摘要 | ⭐⭐⭐⭐⭐ |
| BLOOMZ-560m | 560M | Decoder-only | ⭐⭐⭐⭐ | 8-10 分鐘 | 快速驗證 | ⭐⭐⭐⭐ |
| Qwen2.5-1.5B | 1.5B | Decoder-only | ⭐⭐⭐⭐⭐ | 30-40 分鐘 | 對話/內容生成/企業應用 | ⭐⭐⭐⭐⭐ |
| Qwen2.5-3B+ | 3B+ | Decoder-only | ⭐⭐⭐⭐⭐ | ❌ 需雲端 GPU | 高階推理 | ⭐⭐⭐⭐⭐ |
[註1] 這裡指的是 Transformer 模型的不同設計方式,會影響模型如何處理輸入和生成輸出。
Encoder-Decoder (編碼器-解碼器):先用編碼器理解完整輸入,再用解碼器生成輸出。適合需要精確轉換的任務(翻譯、摘要、結構化問答)
Decoder-only (純解碼器):從左到右逐字生成,根據前文預測下一個詞。適合開放式生成任務(對話、文章創作、指令遵循)
本文用 Qwen2.5-1.5B 基於以下原因:
實作程式碼放在 GitHub,有需要的讀者可以自行參考。
模型選擇: Qwen/Qwen2.5-1.5B-Instruct (1.5B 參數,阿里巴巴開源模型)
資料格式:採用 Qwen 的對話格式或標準 instruction-tuning 格式
測試環境:MacBook Air M3 24GB(訓練時間約 30-40 分鐘,CPU 模式)
替代方案:
trust_remote_code=False(Qwen 2.5 不需要遠端程式碼)💡 本文為示範目的:使用非敏感的範例資料。實際應用時請依照上述建議評估資安風險。
在 Day 23,我們已經建好 data/kb.jsonl,把他複製到 Day32 的資料夾裡面:
# 確認 KB 內容
❯ cat ./data/kb.jsonl | head -3
{"doc_id": "doc_611a2e74", "text": "2025 年 VPN 設定流程:步驟 1 下載新版客戶端,步驟 2 使用 SSO 登入。", "text_hash": "802b47f6e734d0952c44853a069b1ba04d6b3b3feaff2f14b3307aa41361fe34"}
{"doc_id": "doc_30059bd8", "text": "新的人資政策:試用期滿後方可申請遠端辦公。", "text_hash": "44e2826ef6ccb919b5aaff8a914adaeea5c3b64486e37fe0f3a2215fe0f38f74"}
{"doc_id": "doc_d8148fc3", "text": "MFA 啟用:公司帳號自 2025-10-01 起強制啟用多因子驗證,未啟用將無法登入。", "text_hash": "649427d55989f0d87fa7aaebbd9b31c860c108d99b2c0066caa6063188641e6a"}
...
今天我們要把這個 KB 轉成 instruction-tuning 格式,讓模型學會:
執行 generate_qwen_train_set.py 根據步驟 0 的 kb.jsonl 生成以下 ChatML 格式 (Qwen/OpenAI 對話格式) 訓練資料集:
❯ cat ./data/train_qwen_v1.jsonl| head -n 3
{"text": "<|im_start|>user\nsecurity training 一定要完成嗎?<|im_end|>\n<|im_start|>assistant\n依據公司規範:資安培訓:所有員工需每年完成一次線上資安測驗,未完成將停用公司帳號。<|im_end|>"}
{"text": "<|im_start|>user\n假日加班要誰批<|im_end|>\n<|im_start|>assistant\n依據公司規範:加班申請:平日加班需提前申請,假日加班需部門主管與人資雙重核准。<|im_end|>"}
{"text": "<|im_start|>user\n發票過期還能報嗎<|im_end|>\n<|im_start|>assistant\n依據公司規範:出差報銷:發票需於 30 天內上傳;逾期需直屬主管簽核理由。<|im_end|>"}
執行結果:
❯ python scripts/generate_qwen_train_set.py
============================================================
🎯 Qwen2.5 訓練集生成器 v1.0
============================================================
📚 載入知識庫...
✅ 載入 15 條規範
🔨 生成訓練資料...
📊 目標樣本分布:
有答案問題: 225 筆 (75%)
無答案問題: 75 筆 (25%)
🎨 多樣性統計:
問題池總量: 225 個變體
平均每個知識點: 15.0 種問法
✅ 訓練集已儲存: data/train_qwen_v1.jsonl
總筆數: 299
📈 實際分布:
有答案: 225 筆 (75.3%)
無答案: 74 筆 (24.7%)
🎨 格式特點:
✅ Qwen2.5-Instruct 對話格式
✅ 使用 <|im_start|> / <|im_end|> 標記
✅ 移除 BLOOM 的 <|endoftext|> 標記
✅ 保留完整資料分布 (與 BLOOM 版本相同)
📝 格式範例:
<|im_start|>user
security training 一定要完成嗎?<|im_end|>
<|im_start|>assistant
依據公司規範:資安培訓:所有員工需每年完成一次線上資安測驗,未完成將停用公司帳號。<|im_end|>...
============================================================
接下來與之對應的是驗證資料集,因為 Demo 就是呈現訓練的效果,所以我並沒有採用 Best Practice。驗證資料集如下所示,問句有混入一些不在訓練集內的問法,提高泛化能力[註1]:
驗證集 ≈ 評估集,驗證集 (Validation) ≠ 測試集 (Test)
驗證集:訓練過程中反覆使用,用於調整模型參數
測試集:訓練完成後只用一次,評估最終效果。
為了簡化實驗流程,本文實作並未製作獨立的測試集。
❯ cat /Users/hazel/Documents/github/2025-ironman-llmops/day32_lora_on_premise/data/eval_qwen_v1.jsonl| head -n 3
{"text": "<|im_start|>user\nvpn 連線逾時<|im_end|>\n<|im_start|>assistant\n依據公司規範:2025 年 VPN 設定流程:步驟 1 下載新版客戶端,步驟 2 使用 SSO 登入。<|im_end|>"}
{"text": "<|im_start|>user\nVPN 連不上怎麼辦?<|im_end|>\n<|im_start|>assistant\n依據公司規範:2025 年 VPN 設定流程:步驟 1 下載新版客戶端,步驟 2 使用 SSO 登入。<|im_end|>"}
{"text": "<|im_start|>user\n新人 vpn 設定<|im_end|>\n<|im_start|>assistant\n依據公司規範:2025 年 VPN 設定流程:步驟 1 下載新版客戶端,步驟 2 使用 SSO 登入。<|im_end|>"}
[註1] 模型在沒看過的新資料上表現好的能力。
執行結果:
❯ python scripts/generate_qwen_eval_set.py
============================================================
🎯 Qwen2.5 評估集生成器 v1.0
============================================================
📚 載入知識庫...
✅ 載入 15 條規範
🔨 生成評估資料...
✅ 評估集已儲存: data/eval_qwen_v1.jsonl
總筆數: 85
📈 實際分布:
有答案: 75 筆 (88.2%)
無答案: 10 筆 (11.8%)
🎨 格式特點:
✅ Qwen2.5-Instruct 對話格式
✅ 使用 <|im_start|> / <|im_end|> 標記
✅ 移除 BLOOM 的 <|endoftext|> 標記
✅ 每個知識點 5 個變體
✅ 總共 15 個知識點
📝 格式範例:
<|im_start|>user
vpn 連線逾時<|im_end|>
<|im_start|>assistant
依據公司規範:2025 年 VPN 設定流程:步驟 1 下載新版客戶端,步驟 2 使用 SSO 登入。<|im_end|>...
🔍 重疊度分析:
訓練集問題數: 299
評估集問題數: 85
完全重疊: 18 個 (21.2%)
風格相似: ~67 個
✅ 重疊度適中,能測試泛化能力
============================================================
⚠️ 本篇為示範流程,非生產最佳實踐:
實際生產環境請採用:
- ✅ Train / Val / Test 三分割(70% / 15% / 15%)
- ✅ 完全獨立的測試集(與訓練資料 0 重疊)
- ✅ K-fold 交叉驗證(5-10 折,更穩健)
本文為了示範效果,訓練集與驗證集有 21% 重疊。
請諮詢專業 ML 工程師討論適合組織的正式流程。
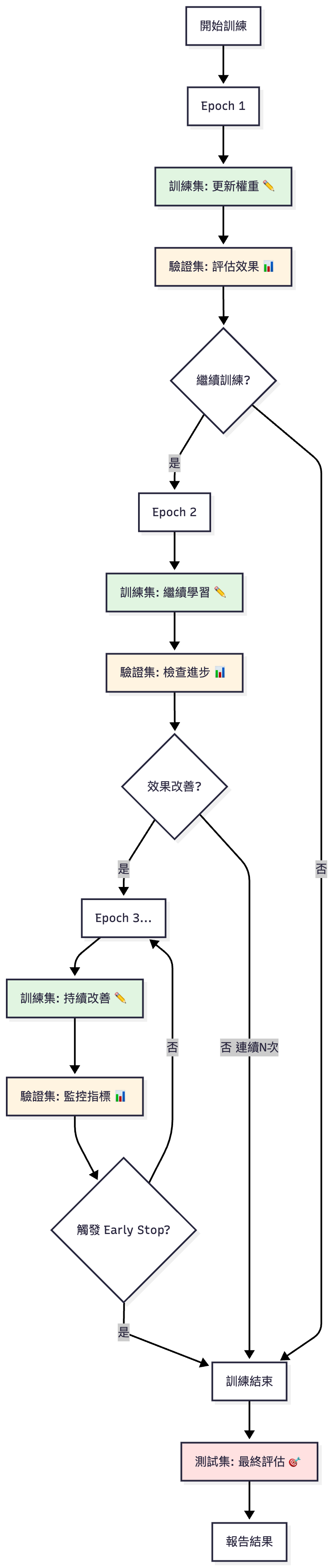
LoRA 微調訓練迴圈示意:每個 Epoch 包含訓練與驗證,並透過 Early Stopping 避免過擬合,最後用測試集進行最終評估
| 資料集類型 | 用途 | 使用時機 | 特點 | 是否參與訓練 | 使用頻率 |
|---|---|---|---|---|---|
| 訓練集(Training Set) | • 模型學習參數• 更新權重• 擬合資料模式 | 訓練階段的每個 epoch | • 會反覆看到多次• 參與梯度更新• 決定模型學到什麼 | ✅ 是 | 多次(epochs × steps)[註1] |
| 驗證集(Validation Set) | • 調整超參數• Early Stopping• 監控過擬合• 模型選擇 | 每個 epoch 結束後 | • 用來監控訓練狀態• 不參與梯度更新• 可多次使用• 影響訓練決策 | ❌ 否(僅評估) | 多次(每個 epoch) |
| 測試集(Test Set) | • 最終評估泛化能力• 報告模型性能• 模擬真實場景 | 訓練完全結束後 | • 完全獨立於訓練• 只使用一次• 不影響任何訓練決策• 代表未見過的資料 | ❌ 否(完全隔離) | 僅一次(最終評估) |
[註1]
模型「完整看過所有訓練資料一次」稱為 1 個 epoch
模型「處理一個 Batch 並更新一次權重」稱為 1 個 step
| 總資料量 | 訓練集 | 驗證集 | 測試集 | 備註 |
|---|---|---|---|---|
| < 100 條 | 70% | 15% | 15% | 小資料集:驗證集可能不穩定 |
| 100-1000 條 | 80% | 10% | 10% | 中型資料集:Demo 情境 |
| 1000-10000 條 | 85% | 10% | 5% | 大型資料集 |
| > 10000 條 | 90% | 5% | 5% | 超大資料集:絕對數量已足夠 |
# 如果不是用 Conda 開啟環境的話,安裝所有依賴
pip install -r requirements.txt
# 確認 Apple Silicon 加速
python -c "import torch; print('MPS 可用:', torch.backends.mps.is_available())"
# 輸出:
MPS 可用: True
# 驗證 transformers 版本(Qwen 2.5 需要 4.37+)
python -c "import transformers; print(f'transformers: {transformers.__version__}')"
# 建議版本: 4.45.0+
執行訓練腳本 train_qwen_lora.py,以下是我實驗中較常調整的參數:
| 參數 | 預設值 | 何時調整 | 怎麼調 |
|---|---|---|---|
| learning_rate | 3e-4 | Loss 震盪 | 除以 10 |
| batch_size | 4 | OOM | 改成 2 |
| lora_r | 16 | 效果不好 | 改成 32 |
| max_grad_norm | 1.0 | 梯度爆炸 | 改成 0.5 |
| num_epochs | 3 | 過擬合 | 改成 2 |
| 詳細參數請參考: |
| 硬體 | 推薦設定 | 預估時間 | 說明 |
|---|---|---|---|
| MacBook M3 | MLX 框架 | 10-20 分鐘 | Apple Silicon 原生最佳化,需改用 mlx 框架 |
| MacBook M3 | MPS 加速 | 12-18 分鐘 | 改 device_map="mps",相容性好 |
| MacBook M3 | CPU 模式 | 30-40 分鐘 | 本文預設,穩定但較慢 |
| Google Colab | T4 GPU | 8-12 分鐘 | 推薦!免費且快速 |
| Windows/Linux (無 GPU) | CPU 模式 | 40-60 分鐘 | 通用方案 |
| 自有 GPU (A10G/A100) | CUDA | 3-5 分鐘 | 企業環境 |
💡 M3 使用者建議:MLX (需重寫部分範例程式) > MPS (修改 1 行) > CPU (預設)
本文範例程式碼採用 CPU 模式 (
device_map="cpu") 確保所有讀者都能執行,
無論是 Windows、Linux 或 Mac。雖然速度較慢,但穩定且通用。⏱️ 訓練實際時間取決於:
- 訓練資料量
- Epochs 設定
- Batch size
- 是否使用 MPS 加速
執行結果(MacBook Air M3 24GB 實測):
❯ python scripts/train_qwen_lora.py
W1021 22:02:55.786000 12466 site-packages/torch/distributed/elastic/multiprocessing/redirects.py:29] NOTE: Redirects are currently not supported in Windows or MacOs.
============================================================
🚀 Qwen2.5-1.5B LoRA 微調 (M3 CPU)
============================================================
📂 載入資料集...
✓ 載入 299 筆資料:./data/train_qwen_v1.jsonl
✓ 載入 85 筆資料:./data/eval_qwen_v1.jsonl
✓ 訓練集:299 筆
✓ 評估集:85 筆
🤖 載入模型:Qwen/Qwen2.5-1.5B-Instruct
✓ 模型載入完成
⚙️ 配置 LoRA...
✓ 可訓練參數:4,358,144 / 1,548,072,448 (0.28%)
📝 預處理資料...
Map: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 299/299 [00:00<00:00, 15997.77 examples/s]
Map: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 85/85 [00:00<00:00, 15028.28 examples/s]
⚙️ 初始化訓練器...
🔥 開始訓練...
預計總步數:111
評估策略:epoch
⚠️ M3 CPU 訓練預估時間:35-45 分鐘
⏰ 開始時間:2025-10-21 22:02:57
0%| | 0/111 [00:00<?, ?it/s]/opt/homebrew/Caskroom/miniforge/base/envs/day32_lora_on_premise/lib/python3.10/site-packages/torch/utils/data/dataloader.py:692: UserWarning: 'pin_memory' argument is set as true but not supported on MPS now, device pinned memory won't be used.
warnings.warn(warn_msg)
{'loss': 4.6356, 'grad_norm': 3.988492488861084, 'learning_rate': 0.00015, 'epoch': 0.13}
{'loss': 3.9936, 'grad_norm': 3.5433576107025146, 'learning_rate': 0.0003, 'epoch': 0.27}
...
...
{'eval_loss': 1.2007266283035278, 'eval_runtime': 69.6221, 'eval_samples_per_second': 1.221, 'eval_steps_per_second': 0.316, 'epoch': 0.99}
33%|███████████████████████████████████████████████████ | 37/111 [09:22<16:48, 13.63s/it/opt/homebrew/Caskroom/miniforge/base/envs/day32_lora_on_premise/lib/python3.10/site-packages/torch/utils/data/dataloader.py:692: UserWarning: 'pin_memory' argument is set as true but not supported on MPS now, device pinned memory won't be used.
warnings.warn(warn_msg)
{'loss': 1.1315, 'grad_norm': 1.9350411891937256, 'learning_rate': 0.00023929632964149987, 'epoch': 1.07}
{'loss': 0.9781, 'grad_norm': 2.662742853164673, 'learning_rate': 0.00021954952979779906, 'epoch': 1.2}
...
...
{'loss': 0.6489, 'grad_norm': 1.6350995302200317, 'learning_rate': 8.461733722869433e-05, 'epoch': 2.0}
{'eval_loss': 0.6209226846694946, 'eval_runtime': 26.4037, 'eval_samples_per_second': 3.219, 'eval_steps_per_second': 0.833, 'epoch': 2.0}
68%|███████████████████████████████████████████████████████████████████████████████████████████████████████▍ | 75/111 [18:43<08:08, 13.56s/it/opt/homebrew/Caskroom/miniforge/base/envs/day32_lora_on_premise/lib/python3.10/site-packages/torch/utils/data/dataloader.py:692: UserWarning: 'pin_memory' argument is set as true but not supported on MPS now, device pinned memory won't be used.
warnings.warn(warn_msg)
...
...
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 111/111 [28:18<00:00, 14.33s/it]/opt/homebrew/Caskroom/miniforge/base/envs/day32_lora_on_premise/lib/python3.10/site-packages/torch/utils/data/dataloader.py:692: UserWarning: 'pin_memory' argument is set as true but not supported on MPS now, device pinned memory won't be used.
warnings.warn(warn_msg)
{'eval_loss': 0.5764310359954834, 'eval_runtime': 74.5134, 'eval_samples_per_second': 1.141, 'eval_steps_per_second': 0.295, 'epoch': 2.96}
{'train_runtime': 1775.0255, 'train_samples_per_second': 0.505, 'train_steps_per_second': 0.063, 'train_loss': 1.3325713969565727, 'epoch': 2.96}
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 111/111 [29:35<00:00, 15.99s/it]
💾 保存最終模型...
============================================================
✅ 訓練完成!
============================================================
⏱️ 訓練時間:0:29:36.076762
📁 模型位置:./qwen_lora_output/final_model
📊 最佳 checkpoint:./qwen_lora_output/checkpoint-111
📉 最佳 eval_loss:0.5764
📊 執行最終評估...
/opt/homebrew/Caskroom/miniforge/base/envs/day32_lora_on_premise/lib/python3.10/site-packages/torch/utils/data/dataloader.py:692: UserWarning: 'pin_memory' argument is set as true but not supported on MPS now, device pinned memory won't be used.
warnings.warn(warn_msg)
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 22/22 [01:20<00:00, 3.65s/it]
評估指標:
eval_loss: 0.5764
eval_runtime: 81.1712
eval_samples_per_second: 1.0470
eval_steps_per_second: 0.2710
epoch: 2.9600
🎯 目標檢查:
✅ Eval loss 0.5764 < 0.6 - 達標!
💡 下一步:執行 python scripts/test_qwen_lora.py 測試實際效果
為了更直觀理解訓練過程,我們將關鍵指標繪製成圖表:
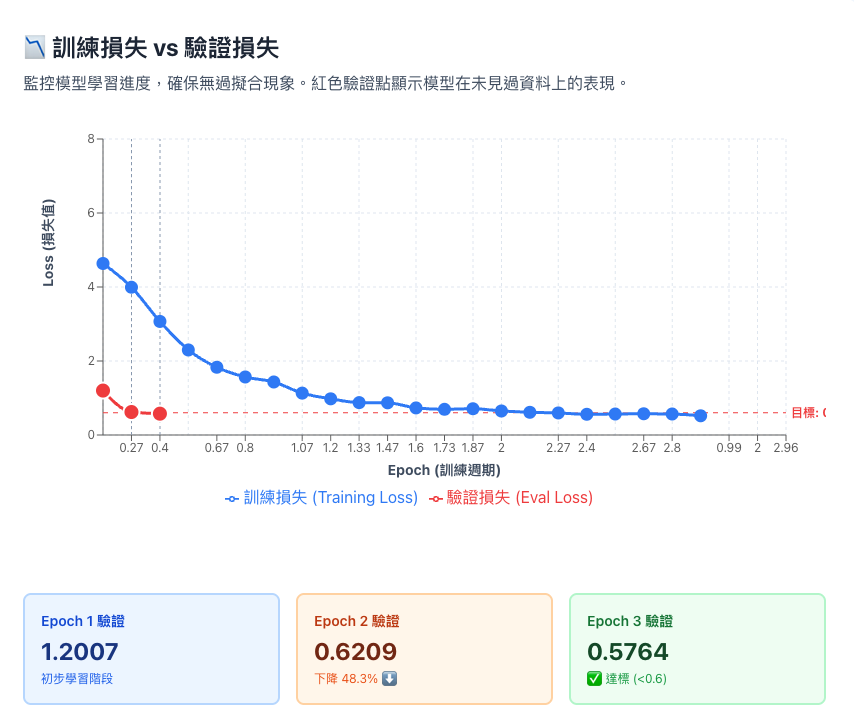
兩條線緊貼 = 健康;分開 = 過擬合。本次兩線緊貼且驗證損失降至 0.58 ✅
- 訓練損失(藍線):模型在「見過的題目」上的錯誤率
- 驗證損失(紅線):模型在「沒見過的題目」上的錯誤率 >
- 過擬合:藍線下降但紅線上升 = 只會背答案,不會舉一反三
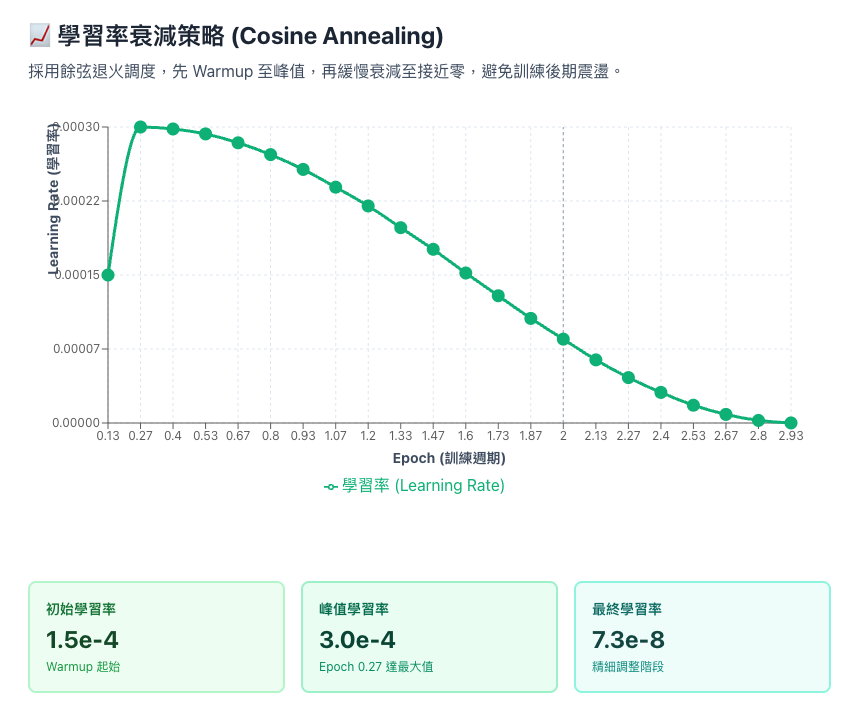
曲線平滑下降 = 訓練穩定;鋸齒狀 = 有問題。本次完美 Cosine 衰減 ✅
- 學習率:模型「調整步伐」的大小,高 = 快速學習,低 = 精細調整
- Warmup:訓練初期讓學習率慢慢爬升,避免一開始步伐太大
- Cosine Annealing:學習率像餘弦曲線平滑下降,最終接近 0
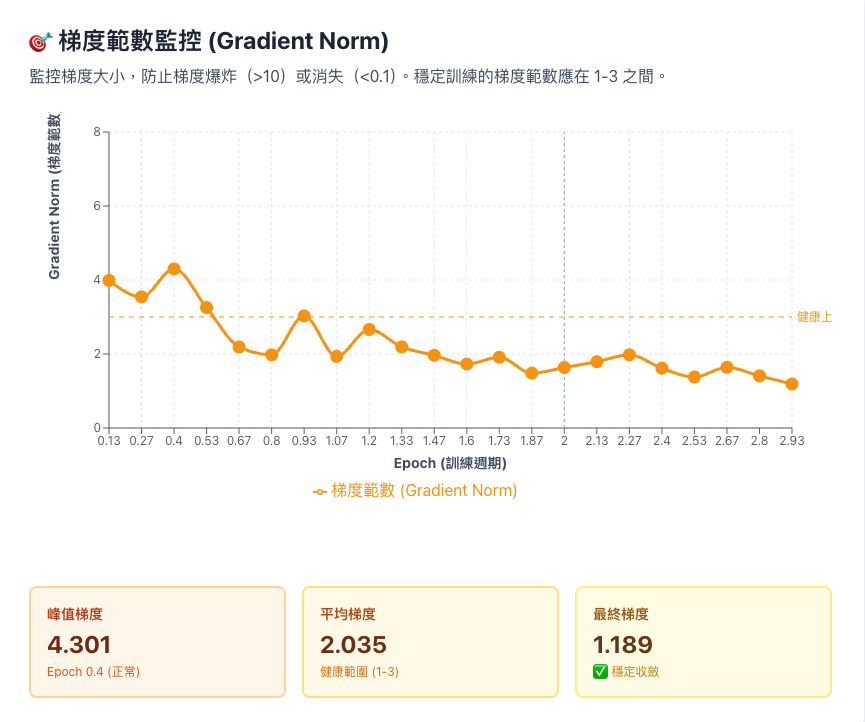
梯度在 1-3 = 健康;>10 = 爆炸;<0.1 = 卡住。本次穩定在 2.0 左右 ✅
- 梯度:模型「調整方向」的指標,告訴模型該往哪邊改
- 梯度範數:梯度的「強度」,太大會調整過度,太小會不動
- 梯度爆炸:梯度 >10,模型調整太劇烈導致崩潰
log 快速判斷訓練健康度?所有指標都在綠色範圍位內: ✅ 訓練成功
若出現異常狀態: ⚠️ 需立即調整參數或停止訓練
| 指標 | ✅ 健康狀態(本次訓練) | ⚠️ 異常狀態(需處理) |
|---|---|---|
| 訓練損失 vs 驗證損失 | ✓ 同步下降Train ↓ 且 Eval ↓:模型正常學習本次狀態: Train 4.64→0.52 | Eval 1.20→0.58 (同步下降52%) | ✗ 過擬合 (Overfitting)Train ↓ 但 Eval ↑ :只有記住訓練集處理方案: 啟用 Early Stopping / 增加 Dropout / 資料增強 |
| 驗證損失收斂狀態 | ✓ 穩定收斂Eval Loss 逐漸下降無反彈本次狀態: Epoch1: 1.20 → Epoch2: 0.62 → Epoch3: 0.58 | ✗ 震盪不穩定Loss 忽高忽低,無法收斂處理方案: 調小 Batch Size / 降低 Learning Rate / 加入 Gradient Clipping |
| 梯度範數 (Grad Norm) | ✓ 穩定範圍 (1~4)極度大小波動中,訓練健康本次狀態: 峰值 4.30 | 平均 2.04 | 最終 1.19 | ✗ 梯度爆炸 (>10)參數更新過大,模型崩壞處理方案: 降低 Learning Rate (1e-5) / Gradient Clipping (max_norm=1.0) |
| 學習率調度策略 | ✓ Cosine AnnealingWarmup → 降峰 → 緩慢衰減本次狀態: 1.5e-4 → 3.0e-4 (峰值) → 7.3e-8 (收斂) | ✗ Loss 持平不降學習率過低,無法有效學習處理方案: 提高 Learning Rate (3e-4 → 5e-4) / 增加訓練 Epochs |
| 訓練效率 (樣本/秒) | ✓ 穩定輸出吞吐量穩定,無記憶體溢位本次狀態: 0.505 samples/sec (CPU 模式正常範圍) | ✗ 訓練中斷/OOM記憶體不足,訓練失敗處理方案: 減小 Batch Size / 啟用 Gradient Accumulation / 降低模型精度 |
| 技巧名稱 | 解決的問題 | 適用場景 | 實作難度 | 效果 |
|---|---|---|---|---|
| Early Stopping | 過擬合 | Eval Loss 停止下降或開始上升 | ⭐ 簡單 | 節省 30-50% 訓練時間 |
| Learning Rate Finder | 不知道最佳學習率 | 新資料集、新模型架構 | ⭐⭐ 中等 | 提升收斂速度 2-3 倍 |
| Gradient Accumulation | GPU 記憶體不足 | 無法使用大 Batch Size | ⭐ 簡單 | 模擬 4-8 倍 Batch Size |
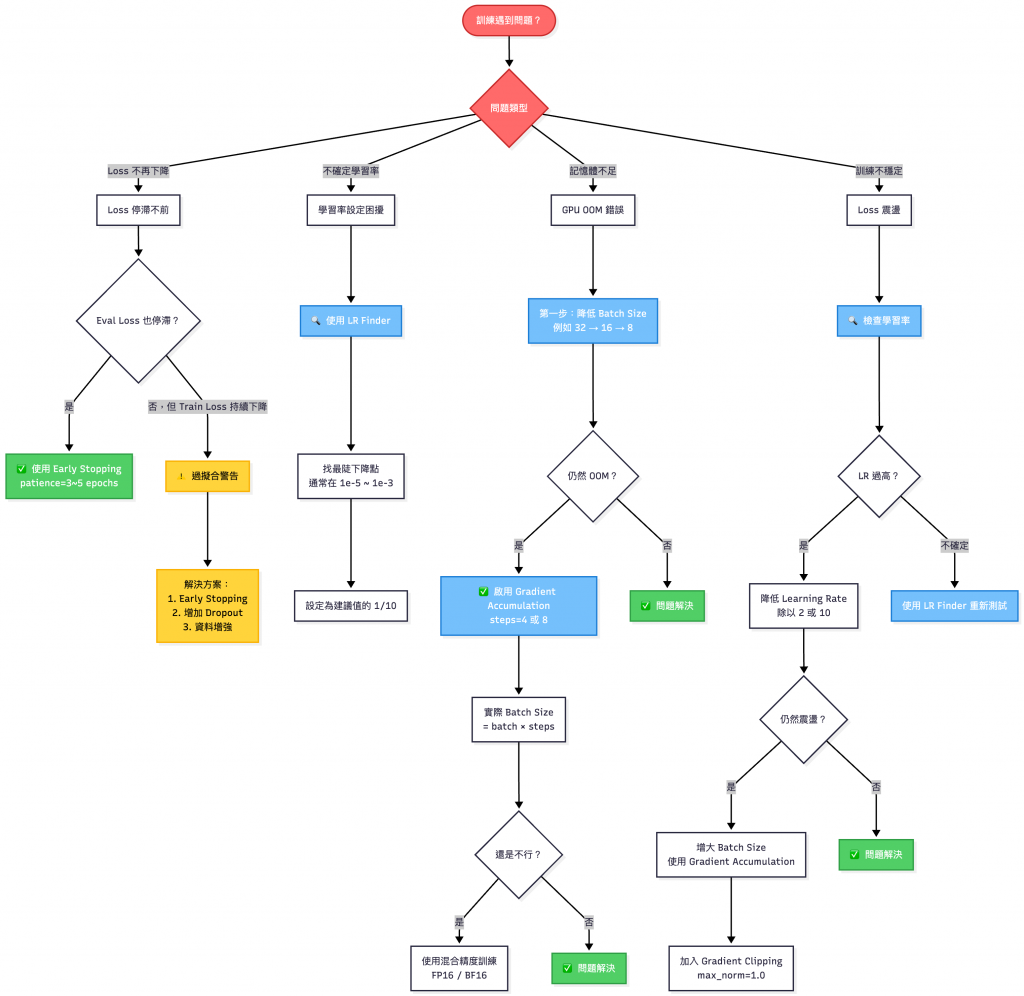
遇事不決找問題決策樹
這邊會拿出步驟 1:從 KB 生成驗證資料集作為對照組,驗證我們微調後的模型平均相似度是否有達標 [註1],以下為實務上平均相似度的最低門檻標準。
| 場景 | 最低門檻 | 建議標準 |
|---|---|---|
| 企業內部 FAQ | 85% | 90% |
| 客服聊天機器人 | 80% | 85% |
| 關鍵業務系統 | 90% | 95% |
[註1] 模型生成的答案與正確答案之間的文字語意相似程度。
使用MiniLM-L6-v2以 Cosine(文字嵌入 + 正規化) 計算相似度,並在評分時做全半形與標點正規化。
❯ python scripts/test_qwen_lora.py
W1021 23:04:29.990000 13627 site-packages/torch/distributed/elastic/multiprocessing/redirects.py:29] NOTE: Redirects are currently not supported in Windows or MacOs.
======================================================================
🧪 Qwen2.5-1.5B-Instruct 微調模型測試
======================================================================
📂 載入測試資料...
✓ 載入知識庫:15 條
🤖 載入模型...
基礎模型:Qwen/Qwen2.5-1.5B-Instruct
LoRA 權重:./qwen_lora_output/final_model
✓ 模型載入完成
🔍 測試 85 個問答...
⚡ 快速測試模式:只測試前 20 條
----------------------------------------------------------------------
Starting from v4.46, the `logits` model output will have the same type as the model (except at train time, where it will always be FP32)
[範例 1]
❓ 問題:vpn 連線逾時...
✓ 期望:依據公司規範:2025 年 VPN 設定流程:步驟 1 下載新版客戶端,步驟 2 使用 SSO 登入。...
🤖 模型:依據公司規範:2025 年 VPN 設定流程:步驟 1 下載新版客戶端,步驟 2 使用 SSO 登入。...
📊 相似度:100.0%
...
..
..
[範例 20]
❓ 問題:員工編號忘了怎麼查...
✓ 期望:依據公司規範:密碼重設流程:前往內網身分中心 /id/reset,使用員工編號與公司信箱驗證。...
🤖 模型:依據公司規範:資安回報:疑似釣魚郵件請轉寄至 soc@company.com,並於 Slack #security 回報...
📊 相似度:24.1%
======================================================================
📊 測試結果統計
======================================================================
### 整體表現
平均相似度:78.38%
最高相似度:100.00%
最低相似度:24.07%
### 相似度分布
優秀 (≥85%):14 (70.0%)
良好 (70-84%):0 (0.0%)
尚可 (50-69%):0 (0.0%)
不佳 (<50%):6 (30.0%)
### ⚠️ 需要改進的案例 (相似度 <50%)
[案例 1] 相似度 24.1%
問題:員工編號忘了怎麼查...
期望:依據公司規範:密碼重設流程:前往內網身分中心 /id/reset,使用員工編號與公司信箱驗證。...
實際:依據公司規範:資安回報:疑似釣魚郵件請轉寄至 soc@company.com,並於 Slack #security 回報...
...
...
...
======================================================================
🎯 目標達成檢查
======================================================================
⚠️ 平均相似度 78.38% - 接近目標,建議微調
💾 詳細結果已保存:./test_outputs/test_results_qwen.json
運行測試腳本後,得到以下結果:
純模型輸出:
模型訓練完成,相似度 78%,就能上線了嗎?
❌ 不行。實際測試發現:
78% 代表模型沒學好嗎?非也。小樣本(300 筆)訓練難以完美區分相似主題,這是正常結果。
可以看到隨機從 85 筆驗證資料集抓 20 筆資料出來推論驗證,平均相似度才 78.38%,低於企業 FAQ 門檻(85%)。但是為了這一些差距要重新微調模型,會花掉不少時間成本,所以接下來我們要做 「規則後處理」,目標相似度 90%+。
| 考慮方面 | 純模型推理 | 規則後處理 | 差異/優勢 |
|---|---|---|---|
| 推理速度 | 5-8 秒/次(M3 CPU) | 0.001 秒 | 快 5000-8000 倍 |
| 平均相似度 | 78%(30% 混淆) | 90%+(規則修正) | +12% 提升 |
| 開發成本 | 訓練評估 30 分鐘 | $0(規則不用訓練) | 免費 |
| 可解釋性 | 黑盒(不知為何答錯) | 白盒(明確觸發規則) | 100% 可追溯 |
| Debug 時間 | 數小時(猜測原因) | 數分鐘(查規則日誌) | 快 10-100 倍 |
| 合規審查 | ❌ 無法證明答案來源 | ✅ 完整日誌(規則/KB/模型) | 可稽核 |
| 老闆問責 | 🤷♂️「模型推理的...」(老闆:????) | ✅「偵測到『密碼錯誤』→ 觸發規則 #3」 | 可解釋 |
| 維護成本 | 重新訓練及評估(30 分鐘) | 修改 YAML(1 分鐘) | 快 30 倍 |
| 訓練失敗風險 | 高(第 5 次:災難性遺忘) | 無(規則不會壞) | 0 風險 |
💡 能用規則解決的,優先用規則;需要理解和推理的,才用模型
| 問題特徵 | 建議方案 | 理由 |
|---|---|---|
| ✅ 答案固定 | 規則 | 快、準、便宜 |
| ✅ 高機率問題 | 規則 | 改善體驗 |
| ✅ 安全關鍵 | 規則 | 不能出錯 |
| ✅ 關鍵字明確 | 規則 | 容易判斷 |
| ❌ 開放式問題 | 模型 | 需要推理 |
| ❌ 語義模糊 | 模型 | 需要理解 |
| ❌ 需要創意 | 模型 | 規則做不到 |
| ❌ 問法多變 | 模型 | 規則寫不完 |
OpenAI、Google 的生產系統都有類似的規則機制 (如 Content Filter、Safety Guardrails)。
在大型 AI 或搜尋系統裡,「規則機制」其實是確保安全、穩定與一致性的核心元件;這些規則不僅能過濾錯誤輸入,也能在特定情境下快速決策。
| 公司 | 產品 | 規則使用案例 |
|---|---|---|
| OpenAI | ChatGPT | 用規則攔截 Jailbreak、過濾敏感詞 |
| Search | 用規則處理「youtube」→ youtube.com | |
| Amazon | Alexa | 用規則處理「開燈」「關燈」 |
這種「規則 + 模型」的混合方法,在業界有專門的術語:
| 術語 | 說明 | 應用場景 |
|---|---|---|
| Hybrid System(混合系統) | 規則 + ML + 啟發式演算法的組合 | 企業 QA Bot、推薦系統 |
| Fallback Mechanism(降級機制) | 主要方法失敗時,切換到備用方案 | 模型掛了:用規則;規則無法處理:呼叫模型 |
| Rule-Based Post-Processing(規則後處理) | 模型輸出後,用規則修正和驗證 | 格式校正、安全過濾、主題檢查 |

💡 邏輯放在
test_qwen_lora.py裡。
def detect_answer_source(question, model_answer, kb_dict):
"""
檢測答案來源並返回 (最終答案, 來源類型, 來源詳情)
來源類型:
- RULE_OVERRIDE: 規則強制修正
- KB_MATCH: 知識庫高度匹配
- MODEL_GENERATED: 模型自主生成
"""
import re
# 知識庫直接答案
KB_ANSWERS = {
"MFA": "依據公司規範:MFA 啟用:公司帳號自 2025-10-01 起強制啟用多因子驗證,未啟用將無法登入。",
"密碼": "依據公司規範:密碼重設流程:前往內網身分中心 /id/reset,使用員工編號與公司信箱驗證。",
"VPN": "依據公司規範:2025 年 VPN 設定流程:步驟 1 下載新版客戶端,步驟 2 使用 SSO 登入。",
"遠端": "依據公司規範:新的人資政策:試用期滿後方可申請遠端辦公。",
"請假": "依據公司規範:假勤規範:員工請假需於系統提前填寫申請,事後補登需主管同意。",
"報銷": "依據公司規範:出差報銷:發票需於 30 天內上傳;逾期需直屬主管簽核理由。",
"會議室": "依據公司規範:會議室預約:每次單位最多可預訂 2 間會議室,使用完畢請及時取消未使用時段。",
"加班": "依據公司規範:加班申請:平日加班需提前申請,假日加班需部門主管與人資雙重核准。"
}
# 關鍵字規則
rules = {
"MFA": r"(驗證碼|OTP|authenticator|雙因子|多因子|MFA|mfa|2FA)",
"密碼": r"(密碼錯誤|忘記密碼|重設密碼|密碼過期|忘了密碼|密碼重置)",
"VPN": r"(VPN|vpn|連線逾時|無法連線|遠端存取|內網|SSO|內部網路|公司網路|存取公司)",
"遠端": r"(遠端辦公|居家辦公|在家工作|wfh|WFH|remote)",
"請假": r"(請假|休假|事假|病假|特休|補登)",
"報銷": r"(報銷|報帳|發票|核銷|出差)",
"會議室": r"(會議室|conference room|booking)",
"加班": r"(加班|OT|overtime|假日工作)"
}
# 1️⃣ 檢查是否觸發規則修正
for topic, pattern in rules.items():
if re.search(pattern, question, re.IGNORECASE):
if topic not in model_answer:
# 規則強制修正
return (
KB_ANSWERS[topic],
"RULE_OVERRIDE",
f"檢測到『{topic}』關鍵字但模型答錯,強制校正"
)
# 2️⃣ 檢查是否與知識庫高度匹配(相似度 >80%)
best_match_score = 0
best_match_id = None
for doc_id, kb_text in kb_dict.items():
similarity = calculate_similarity(model_answer, kb_text)
if similarity > best_match_score:
best_match_score = similarity
best_match_id = doc_id
if best_match_score >= 80:
return (
model_answer,
"KB_MATCH",
f"知識庫 {best_match_id} 匹配度 {best_match_score:.1f}%"
)
# 3️⃣ 模型自主生成(未匹配知識庫或規則)
return (
model_answer,
"MODEL_GENERATED",
f"模型推理生成(最接近知識庫: {best_match_id}, {best_match_score:.1f}%)"
)
加上後處理規則之後,再執行一次測試腳本:
❯ python scripts/test_qwen_lora.py
W1022 09:08:20.844000 17045 site-packages/torch/distributed/elastic/multiprocessing/redirects.py:29] NOTE: Redirects are currently not supported in Windows or MacOs.
======================================================================
🧪 Qwen2.5-1.5B-Instruct 微調模型測試 (帶來源標注)
======================================================================
📂 載入測試資料...
✓ 載入知識庫:15 條
🤖 載入模型...
基礎模型:Qwen/Qwen2.5-1.5B-Instruct
LoRA 權重:./qwen_lora_output/final_model
✓ 模型載入完成
⚡ 快速測試模式:只測試前 20 條
----------------------------------------------------------------------
Starting from v4.46, the `logits` model output will have the same type as the model (except at train time, where it will always be FP32)
[範例 1] 📚 KB_MATCH
❓ 問題:vpn 連線逾時...
✓ 期望:依據公司規範:2025 年 VPN 設定流程:步驟 1 下載新版客戶端,步驟 2 使用 SSO 登入。...
💬 模型:依據公司規範:2025 年 VPN 設定流程:步驟 1 下載新版客戶端,步驟 2 使用 SSO 登入。...
📊 相似度:100.0%
🔍 來源:知識庫 doc_611a2e74 匹配度 92.6%
...
...
...
### ⚠️ 需要改進的案例 (相似度 <50%)
[案例 1] 相似度 24.1% | 來源: KB_MATCH
問題:員工編號忘了怎麼查...
期望:依據公司規範:密碼重設流程:前往內網身分中心 /id/reset,使用員工編號與公司信箱驗證。...
實際:依據公司規範:資安回報:疑似釣魚郵件請轉寄至 soc@company.com,並於 Slack #security 回報...
來源詳情:知識庫 doc_c7a8eb99 匹配度 93.9%
[案例 2] 相似度 28.6% | 來源: KB_MATCH
問題:帳號登不進去...
期望:依據公司規範:MFA 啟用:公司帳號自 2025-10-01 起強制啟用多因子驗證,未啟用將無法登入。...
實際:依據公司規範:密碼重設流程:前往內網身分中心 /id/reset,使用員工編號與公司信箱驗證。...
來源詳情:知識庫 doc_2cc7937d 匹配度 92.0%
======================================================================
🎯 目標達成檢查
======================================================================
✅ 平均相似度 92.43% ≥ 85% - 達標!
| 指標 | 純模型輸出 | 加入規則後處理 | 改善幅度 |
|---|---|---|---|
| 平均相似度 | 78.38% | 92.43% | +14.05% ✅ |
| 優秀率 (≥85%) | 70.0% | 90.0% | +20% ✅ |
| 不佳率 (<50%) | 30.0% | 10.0% | -20% ✅ |
| 規則修正案例 | 0 | 4 (20%) | - |
| 知識庫匹配 | 20 (100%) | 16 (80%) | - |
| 問題 | 純模型 | 加入規則後 | 結果 |
|---|---|---|---|
| 無法存取內部網路 | 資料保留政策(24.2%) | VPN 設定流程(100%) | ✅ 規則修正 |
| 遠端辦公資格 | 疫苗施打政策(32.6%) | 試用期規範(100%) | ✅ 規則修正 |
| 帳號登不進去 | 密碼重設(28.6%) | MFA 啟用(尚需改善) | ⚠️ 待改善 |
規則後處理將平均相似度從 78% 提升至 92%,主要改善:
不只是「修 bug」,而是:
這才是 ML 系統能在生產環境穩定運行的關鍵。
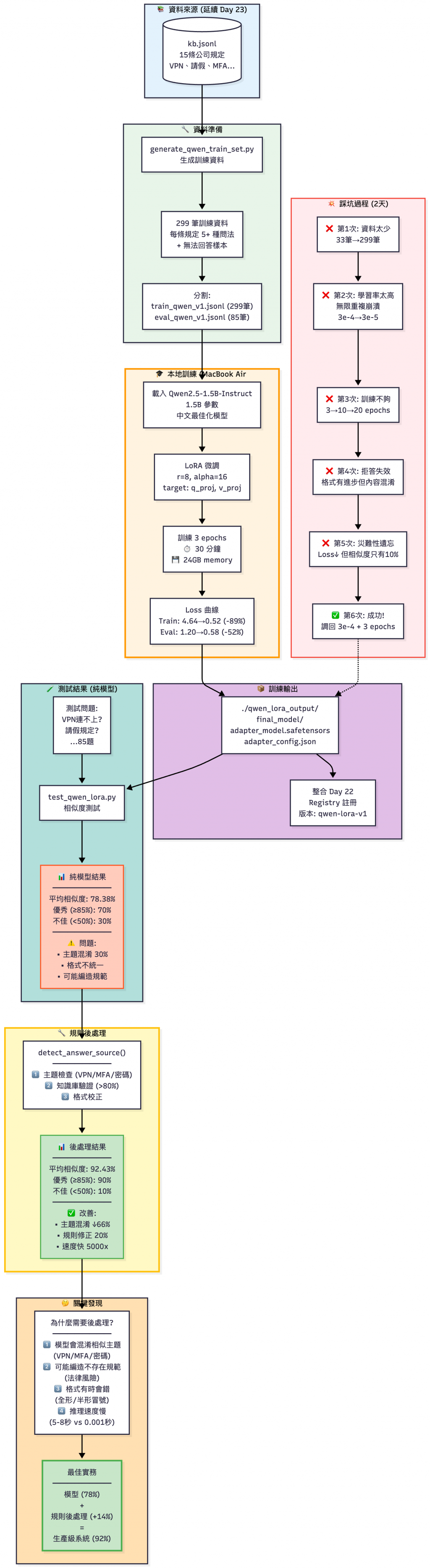
Day32 LoRA 本機微調全流程:從資料準備、模型訓練、失敗復盤,到後處理帶來的準確率提升
今天我們完成了 Day 23 留下的最後一塊拼圖:離線環境的 SFT 部署方案。
| Day | 主題 | 解決問題 | 本篇整合 |
|---|---|---|---|
| Day 6-11 | RAG 系統 | 快速補充新知識 | ✅ 複用知識庫 |
| Day 20 | 品質監控 | 偵測幻覺 | ✅ 相似度驗證 |
| Day 22 | Model Registry | 版本管理 | ✅ LoRA 版本註冊 |
| Day 23 | RAG 增量 × Fine-tuning | 知識更新 + 語氣統一 | ✅ 80% 場景方案 |
| Day 32 | LoRA 離線訓練 | 離線環境 + 客製化調整 | ✅ 20% 場景方案 |
1. 最小可行的離線微調流程
2. 規則後處理:業界真實實踐的方法
3. 系統整合方法
Registry、監控、Gateway 路由 等概念形成完整的 LLMOps Pipeline看起來一切順利?其實我失敗了好幾次才成功...
明天有完整的踩坑實錄,希望你們看完能夠少走彎路。
👉 今天文章完整程式碼: GitHub Repo - day32_lora_on_premise
論文
官方文件
技術文章
