問題管理是識別和管理 IT 服務事故原因的流程,旨在識別和管理 IT 基礎架構中的根本原因,以防止問題引起的重複事件。其目標是找出並解決造成一個或多個事故的根本原因,以及在問題尚未完全解決前提供臨時的替代解決方案或變通措施。
我們先來看看 iTop 標準的 Problem Life Cycle 長怎樣。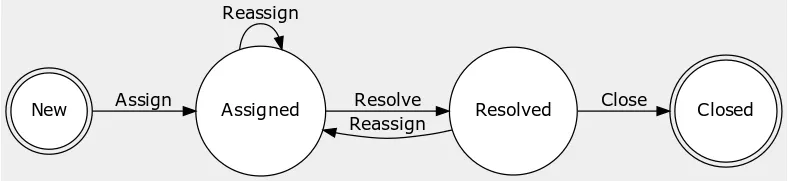
把人物角色放上去,是不是比較容易理解了。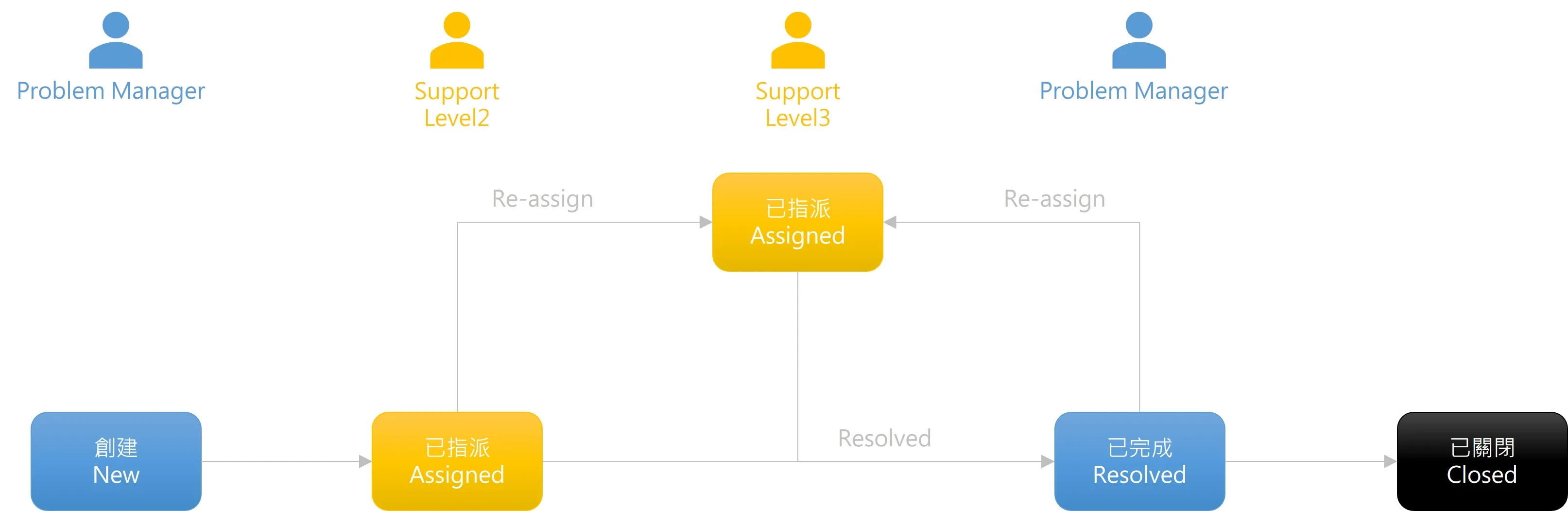
通常由部門的主管來擔任問題管理員的角色,負責建立問題並且指派給熟悉該領域的主任工程師或資深工程師,因為他們才是精通該問題的專家。針對潛在或已經發生的事故進行深入分析,找出問題的根本原因並解決,以避免類似事件再次發生。
真實案例分享:Terminal Quit Unexpectedly
事故描述:某位使用者反應透過遠端桌面連線至終端機伺服器,開啟 Excel 工作時發生不定時斷線問題,嚴重影響工作進度。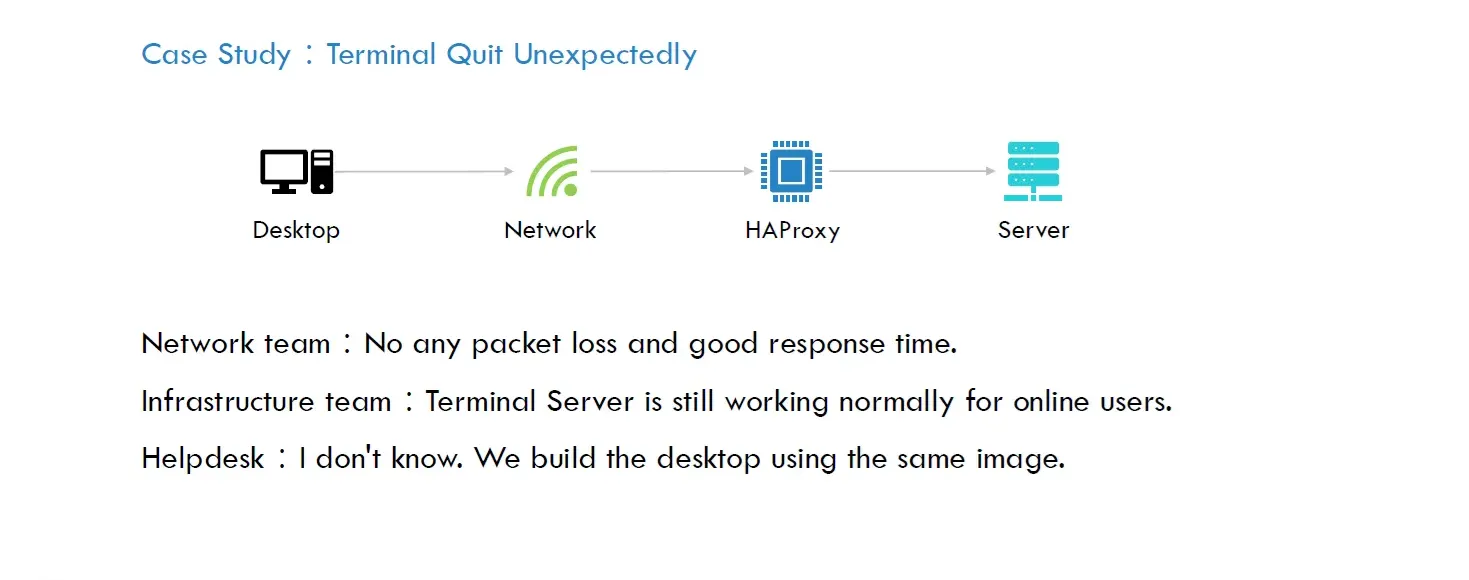
Service Desk Team 很快地就將該 Incident 指派給該服務的維運團隊,於是就展開了以下的對話。
Application Team:該使用者連線到的終端伺服器也都正常運作,看看其他線上用戶不都跑得好好的,是不是網路問題啊。
Network Team:我們查了該辦公區域負責連線的交換機,沒有發生任何的封包遺漏,而且反應時間都正常,我們的網路沒有問題。
Service Desk Team:我們也是照著標準作業流程,使用同一個映像檔安裝作業系統的,之前的設備也都沒有狀況。
問題管理員可以透過 Problem management 的 New Problem,建立與指派問題。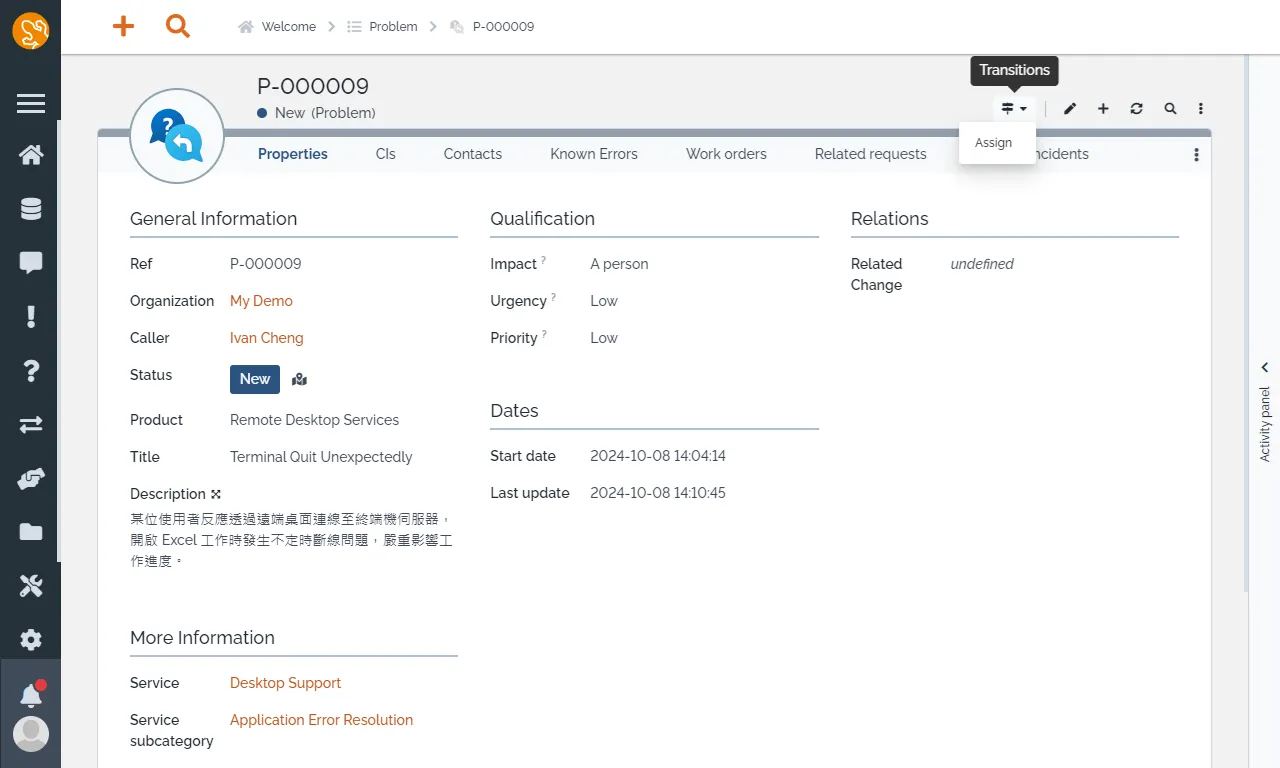
General Information
Qualification
More Information
指派給熟悉該領域的專家,因為他們擁有足夠深度與廣度的專業知識與技能,能夠深入問題的核心進行分析。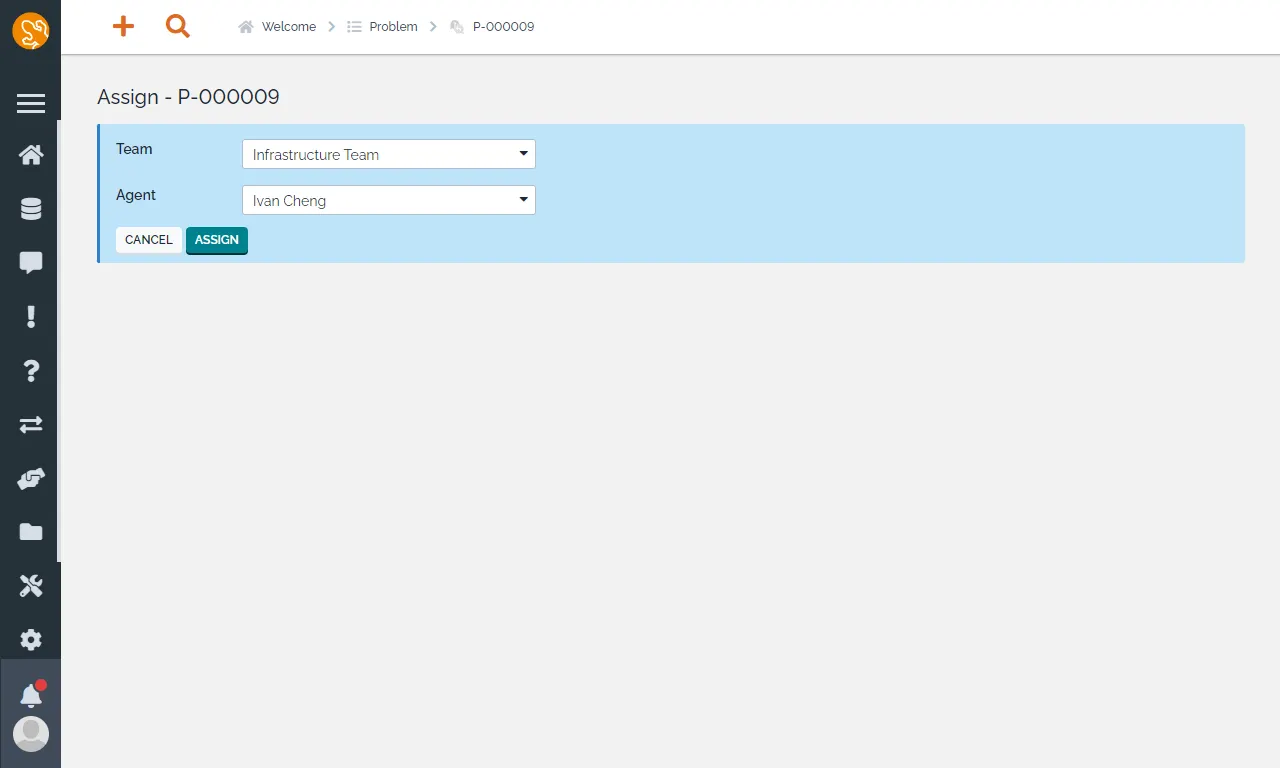
問題和事故之間的主要區別在於,事故必須盡快解決,以縮短服務不可用的時間,而問題則著重於找出根本原因。在根本原因未確定之前,通常會提供一個替代解決方案來幫助解決相應的重複性事件。
我們可以將相關的 CIs 與問題進行連結。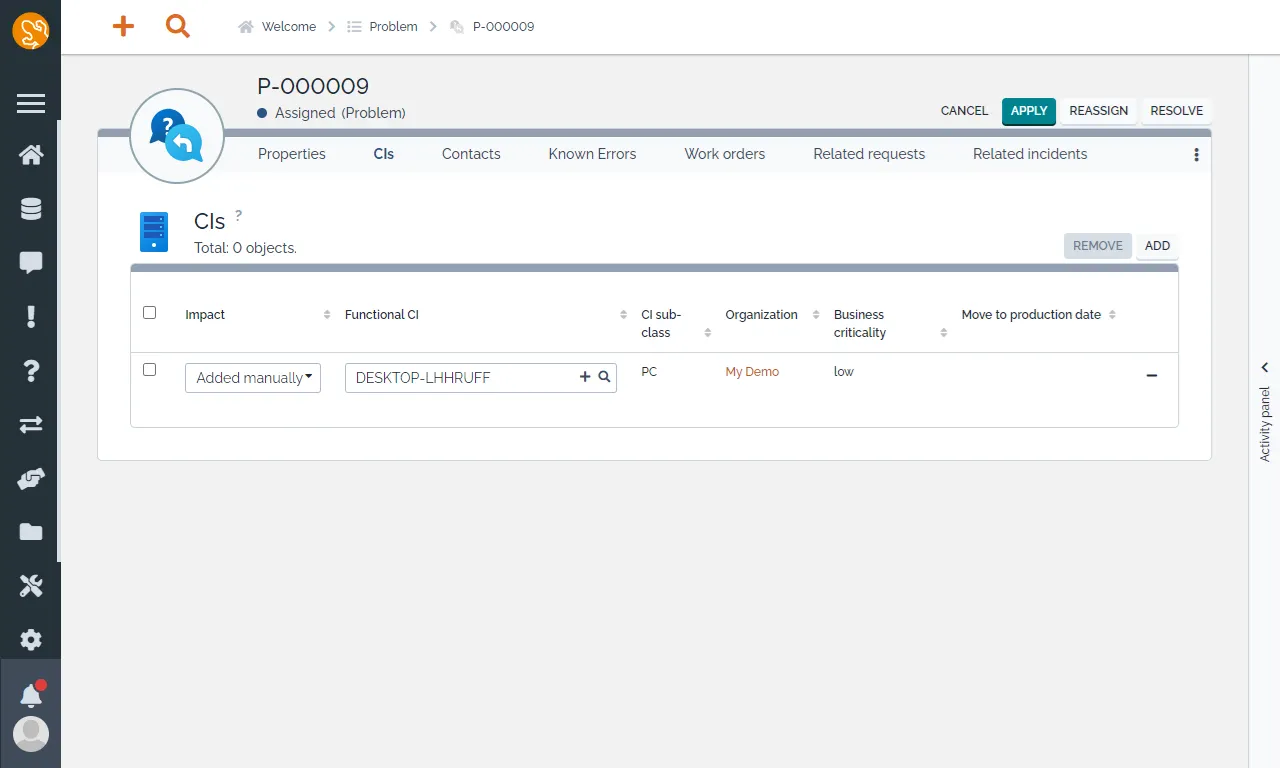
也可以將相關的 Incident 與問題進行關聯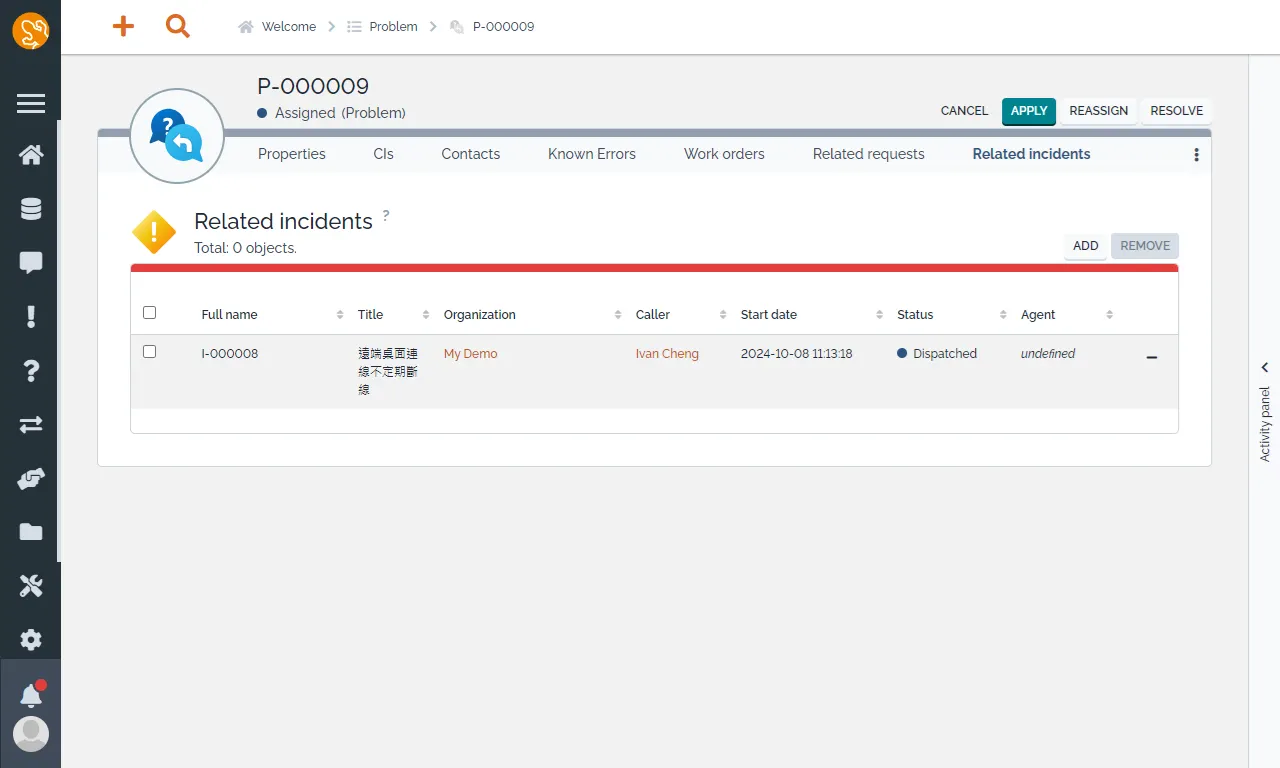
分析步驟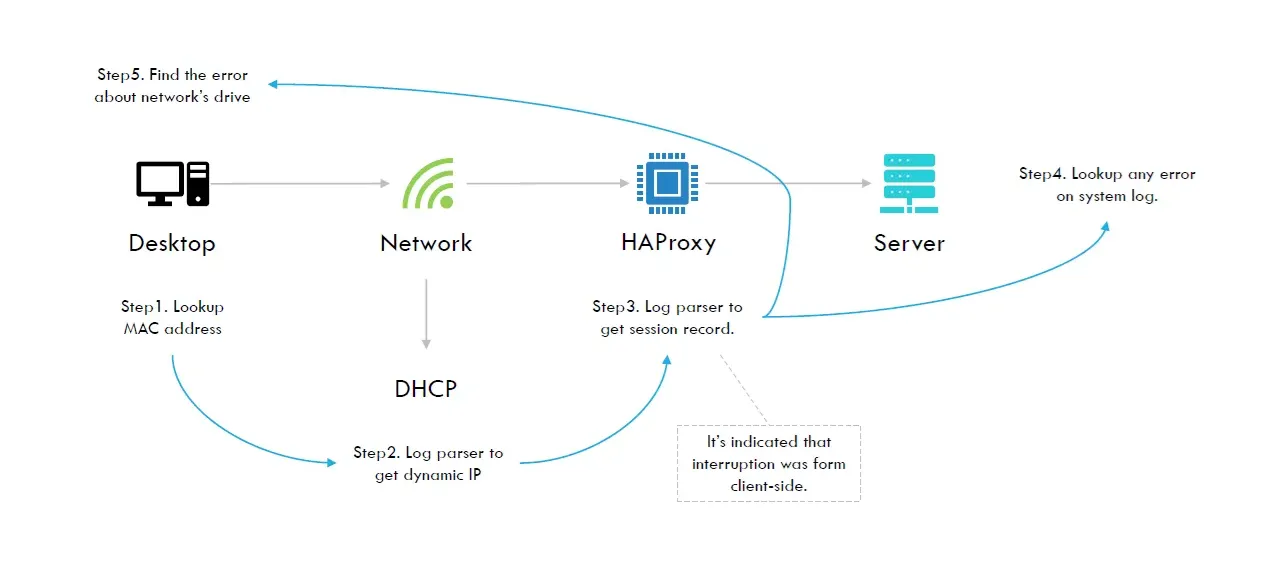
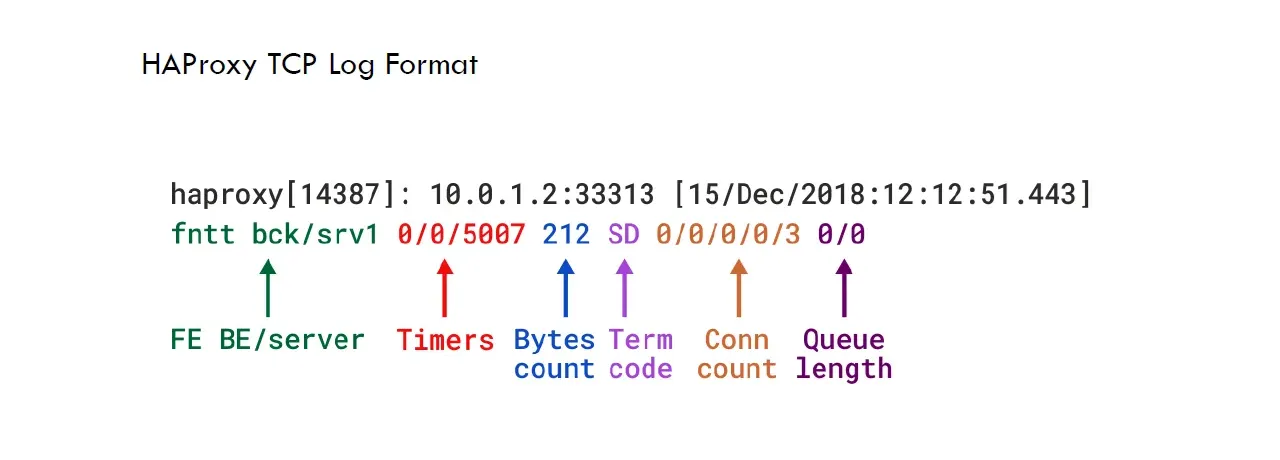
藉由 Term Code 便可得知是從哪一方斷開的,例如 CD 代表是使用者端不預期的中斷資料傳輸。
The client unexpectedly aborted during data transfer. This can be caused by a browser crash, by an intermediate equipment between the client and haproxy which decided to actively break the connection, by network routing issues between the client and haproxy, or by a keep-alive session between the server and the client terminated first by the client.
根本原因
雖然 Service Desk Team 依照標準作業流程進行系統的安裝,但即使是同型號的電腦隨著時間的推移,不同批次的電腦也有可能因為物料短缺而改採其他零組件,使得映像檔裡的網卡驅動不符合現實的狀況所導致。
當 IT 工程師在記錄問題時,其根本原因可能仍然未知。因此,這類型的工單允許記錄所有為找到根本原因並解決問題所做的操作。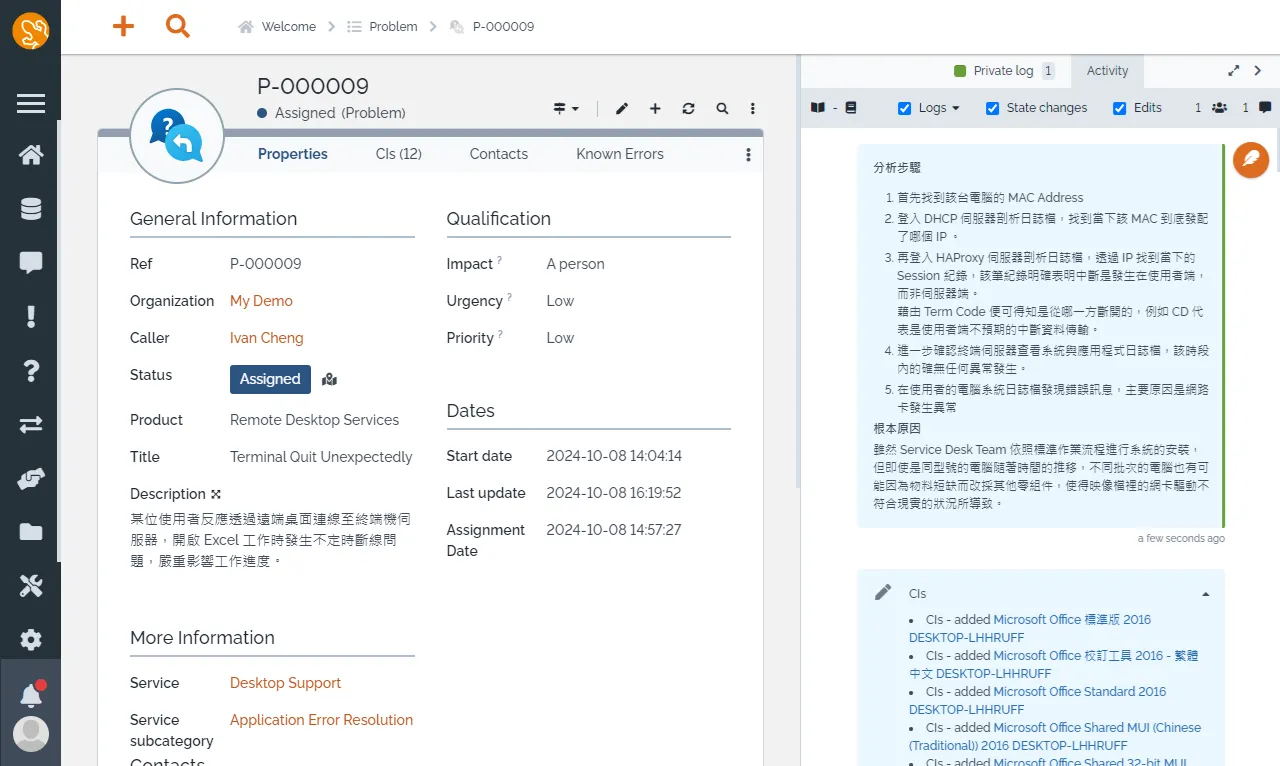
找到根本原因之後,便可將問題變成 RESOLVED 狀態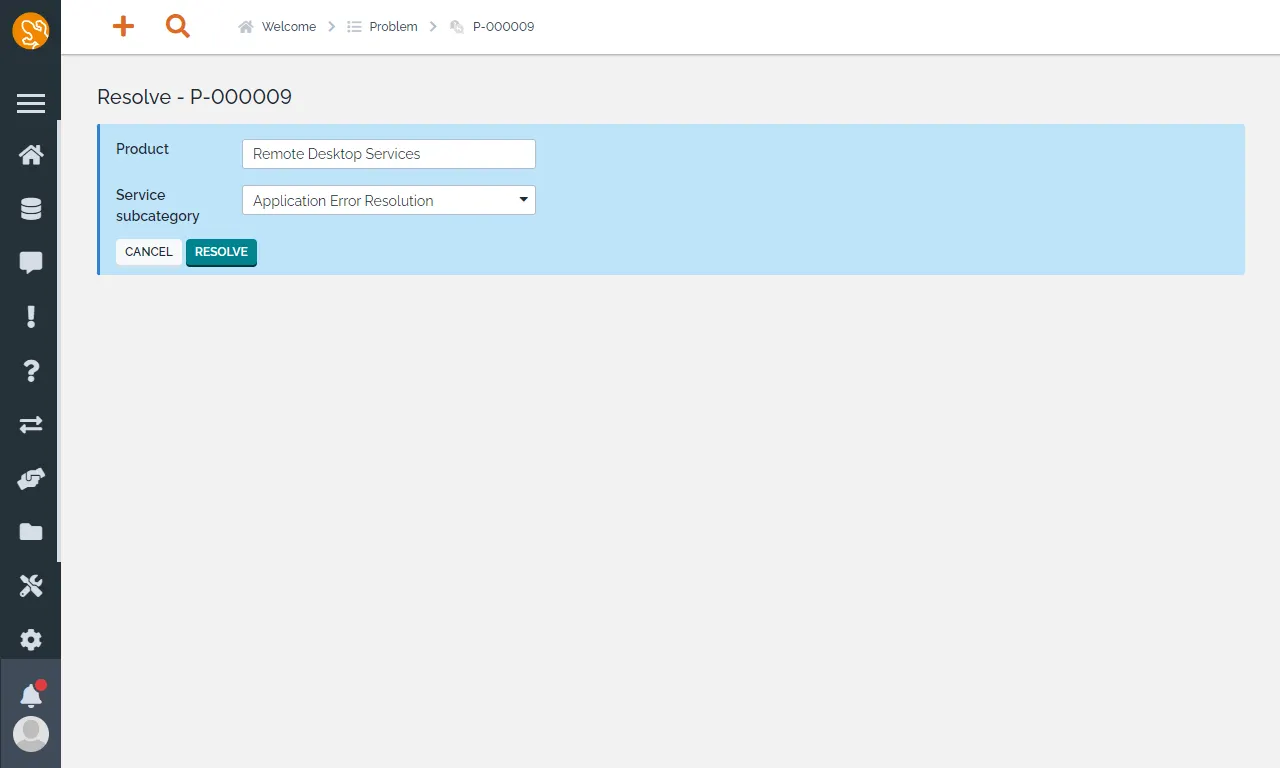
問題管理員將把關決定問題是否關閉,若覺得並非根本原因也可以選擇 Reassign 重新指派問題給其他專家。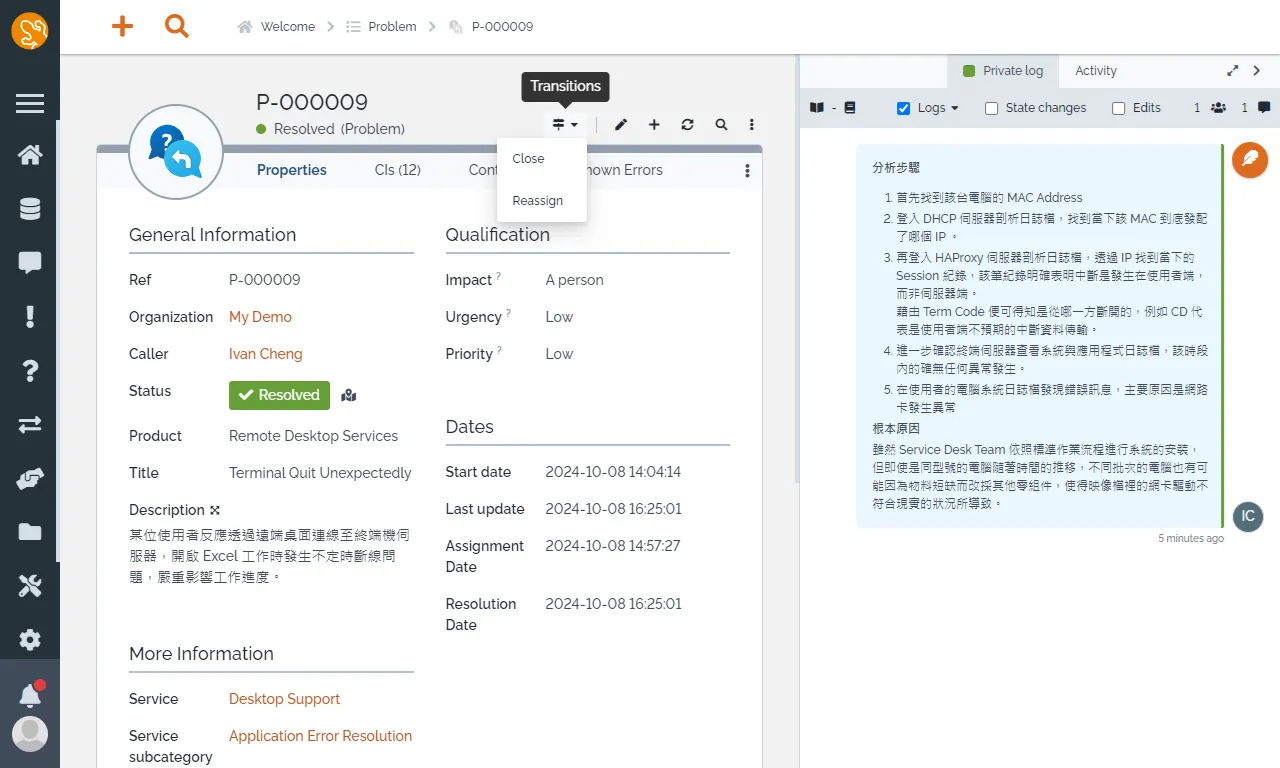
問題管理的相關流程圖可參考如下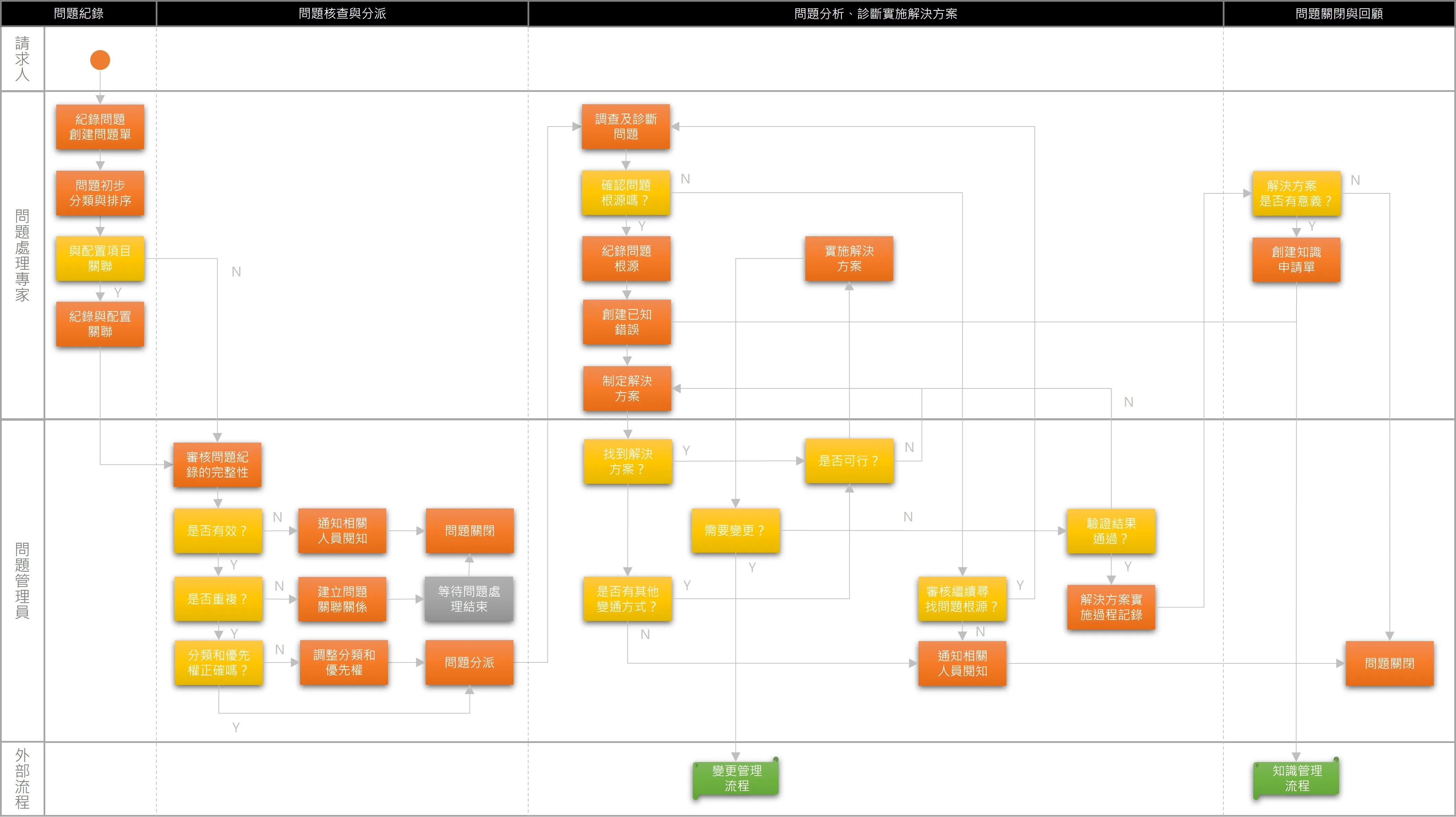
問題管理透過詳細的記錄和分析,幫助企業降低事故的頻率和影響,提升整體服務品質和系統穩定性。
Known Error
已知的錯誤是問題管理流程的一部分,它們用於記錄已知的問題,可在問題尚未完全解決前提供臨時的替代解決方案與變通措施,有助於提升事故管理流程的效率。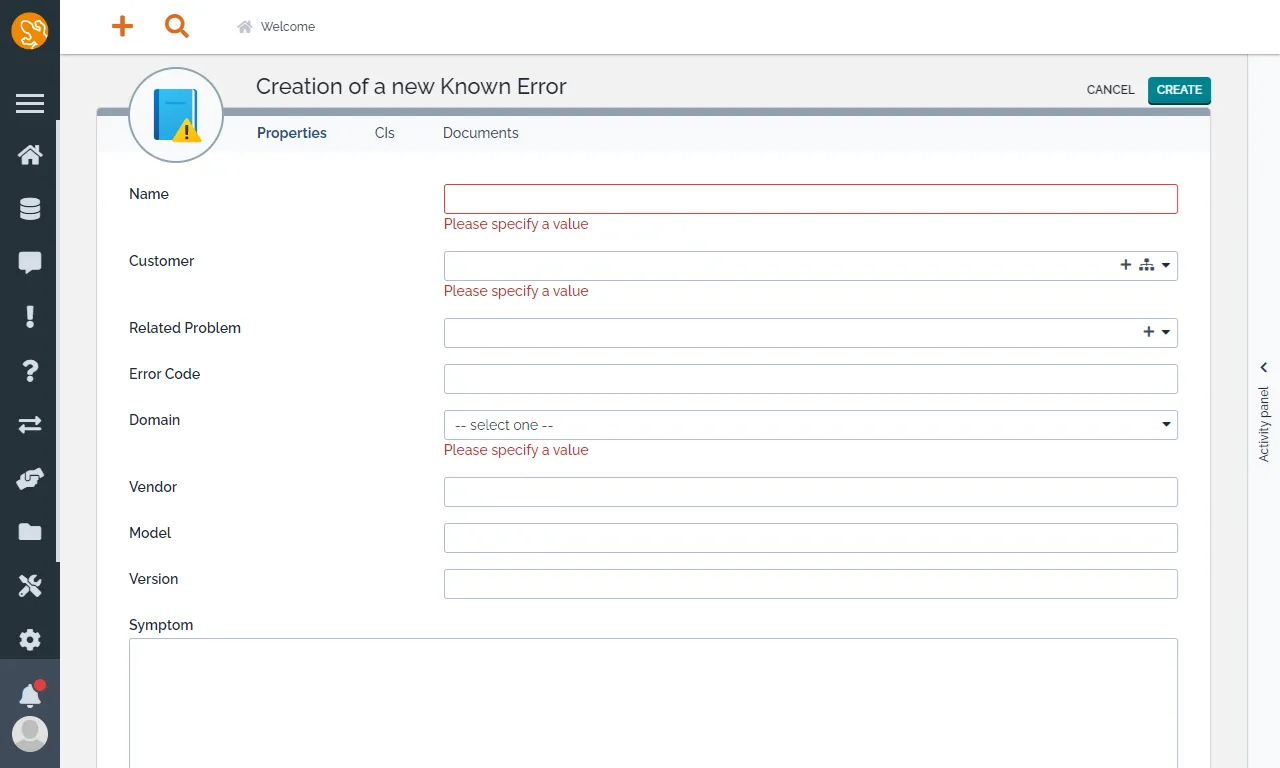
FAQ
常見問題與解答 (FAQ),用於記錄使用者提出的有關服務的最常見問題與解答,有助於降低服務台人員的工作負擔。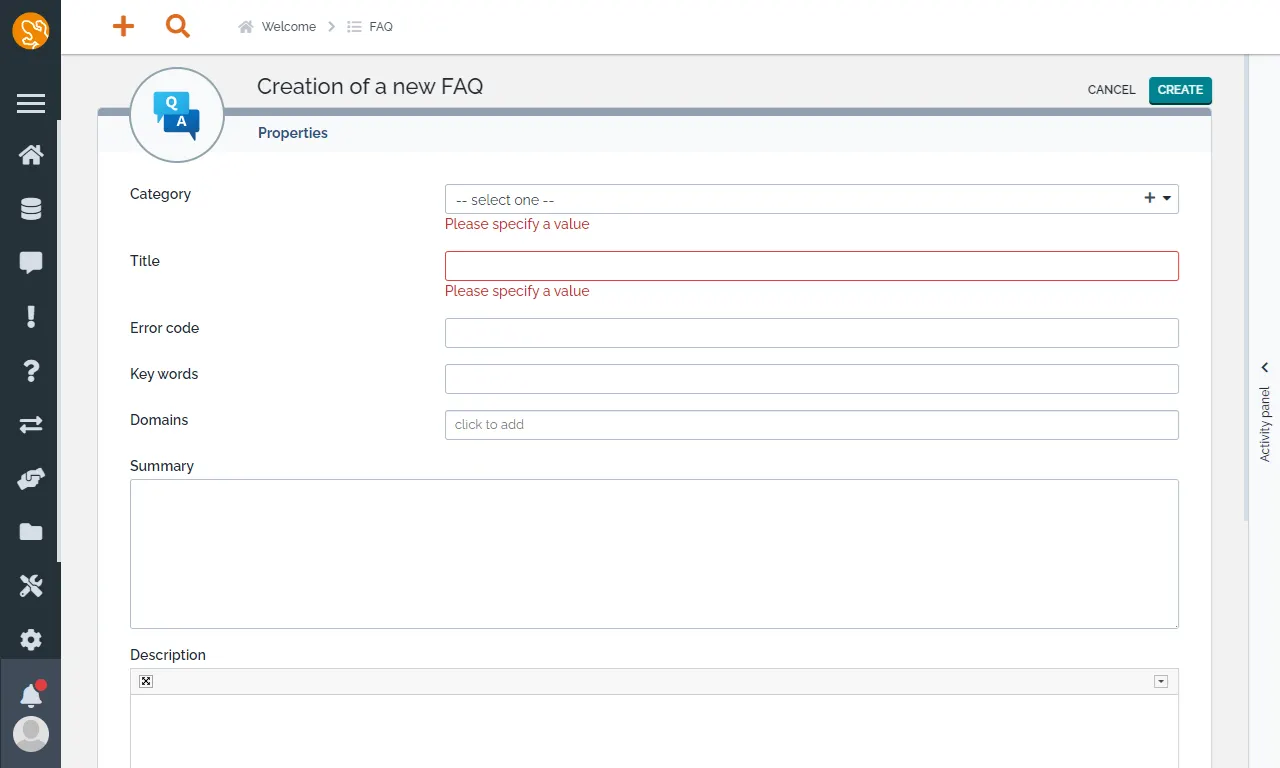
今天的分享就到這邊,感謝收看。
參考文件

