
大型語言模型的本質,其實就是一個能根據提示詞與前文脈絡,持續預測下一個 token 的深度學習模型。它的訓練方式,是先吃進海量文本資料,反覆練習「看到前面,預測後面」這件事。接著讓我們先來認識 LLM 的核心架構:Decoder-Only Transformer。
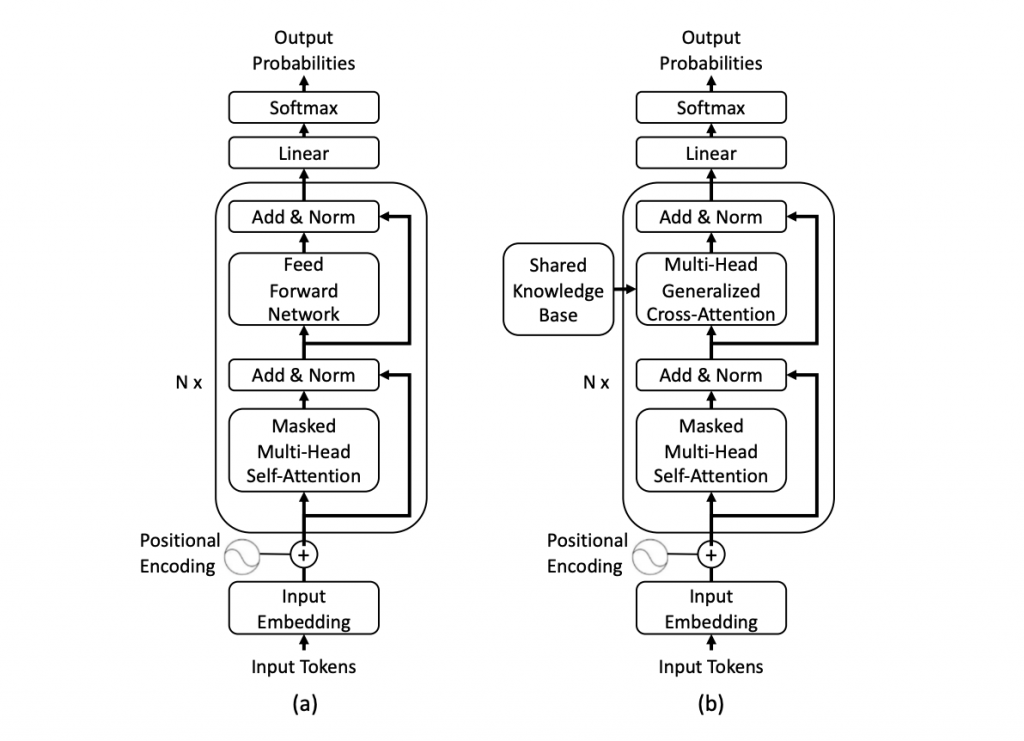
沿著圖由下往上看,文字首先會被切成 token,進入 Input Embedding 轉成向量,並加入 Positional Encoding 來保留順序資訊。接著,這些表示會送進一層層重複堆疊的 decoder block。每一層中,模型先透過 Masked Multi-Head Self-Attention 去讀取前文,找出目前最該關注的上下文,但不會看到未來的 token;再透過 Feed Forward Network 進一步轉換與提煉資訊,而 Add & Norm 則負責讓整個訓練過程更穩定。當資訊一路傳到最上方後,模型會經過 Linear 與 Softmax,輸出下一個 token 的機率分布。
在預訓練階段,模型就是在海量文本上反覆做一件事:「看前面的 token,預測下一個 token,再拿這個預測去對照真實答案,持續更新整個 Transformer 的參數」。所以這張圖是在說明 LLM 當初如何透過 next-token prediction 被一步一步訓練出來。之後推論時,只需沿用同樣的生成機制,不用再更新參數。
當模型在海量文本上做了足夠大量的文字預測練習,它開始不只是學到字詞接龍,而是逐漸學到語言結構、知識關聯、推理模式,甚至展現出某種近似類人智慧的能力。當模型規模、資料規模與訓練規模跨過某個門檻後,這種能力會變得特別明顯,我們把這類現象稱為「湧現」。
但只做到這一步,還不夠。因為預訓練後的模型,雖然已經具備強大的語言能力與基礎文字智能,卻不一定符合人類需求。它可能會答非所問、不夠聽話、不夠實用,也不夠穩定。於是,後續就需要透過一系列對齊與後訓練方法,讓模型變得更強,讓我們看怎麼做。
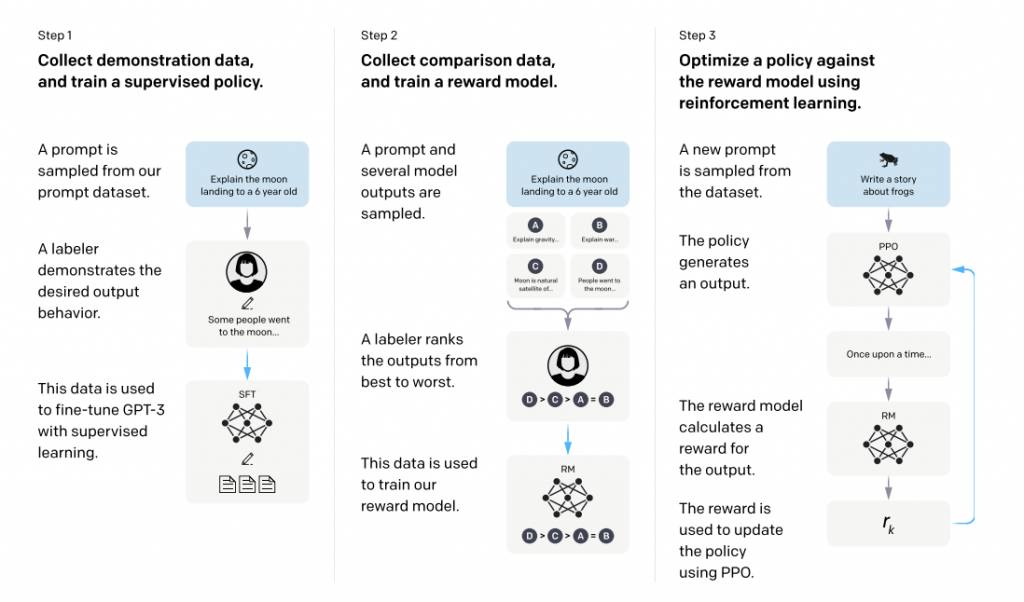
SFT(Supervised Fine-Tuning)
使用人工示範的資料集來教模型「人類期待你怎麼回答」。你可以把它想成先請一批人做示範答案,讓模型模仿,學會比較像樣、比較像人會講的回覆。
Reward Model(RM)
接著,不是只告訴模型標準答案,而是讓人類去比較多個答案哪個更好,訓練出一個「評分員模型」,專門學習人類偏好。
PPO(Proximal Policy Optimization)
最後,再讓模型根據這個評分員給的分數持續調整,強化那些更符合人類偏好的回答方式。簡單說,就是讓模型不只會模仿,還會朝「更討喜、更有用」的方向優化。
InstructGPT 論文正是用這三步:SFT、RM、PPO,來把 GPT-3 往更符合使用者意圖的方向推進。
經過這一層後訓練,原本的預訓練大型語言模型,就會變得更像我們所熟悉的 LLM assistant,說話更像人類、也更能處理實際任務。
即使如此,在這裡我們仍然只把 LLM 看作一個「最小單位的智能體」,因為要想解決現實世界中複雜的問題,只靠單一 LLM 是不夠的,這也正是為什麼,我們需要進一步發展 LLM system。
經過後訓練和迭代微調過後的大型語言模型,即使是如今的最新模型 GPT-5 系列,也能在有足夠上下文的情況下生成極為優質的答案;但它仍有諸多技術上的限制,不能單靠訓練 LLM 解決。
知識不是即時更新
LLM 的知識主要來自訓練時吃進去的資料,所以一旦世界變了、文件更新了、公司內部資料換了,它不會自動知道最新資訊。例如你問 LLM 今天發生的事情,若沒有即時檢索網路資訊,它很可能會跟你胡說八道。
一本正經講糊話
胡說八道是 LLM 誕生之初就存在的最大危險。大部分 LLM 總是回答得很流暢、很像真的,但內容其實可能是錯的、編的,或沒有根據。這就是我們常說的 hallucination。
缺乏可靠的來源依據
當你問一個很難的問題,就算它答對了,你也不知道它是根據哪份資料、哪個事實或依據得出的。對很多真實工作來說,只給答案不夠,還要能追溯來源。
缺乏持久記憶與狀態管理
LLM 比較像一個很強的即時回答器,卻不是一個會長期記住任務進度、使用者偏好、歷史決策與中間狀態的系統,這也是為什麼後來的 agent 系統會很強調 memory。
不會使用外部工具
現實世界很多任務不是「會回答」就夠了,而是要查資料、打 API、跑程式、讀資料庫、操作環境。單一 LLM 本身主要還是文字生成核心,不是天生就能完成這些外部操作。
無法穩定完成多步驟任務
簡單問答它可以很強,可一旦任務變成要先拆解 → 規劃 → 執行 → 再修正,LLM 就容易中途走偏、忘記前面做了什麼,或缺少長程規劃能力,這也是 LLM agent planning 會變成一整個研究題目的原因。
沒有完整的驗證與回饋閉環
LLM 輸出一個答案,不代表這個答案被檢查過或驗證過。高風險任務真正缺的不是「再生成一次」,而是 verifier、evaluation、feedback loop 這些系統層機制,確保生成結果真實可用,否則無法放心交給 AI 自動化處理。
再來說說提升 LLM 的主要方法。OpenAI 將 LLM 的常見優化方式整理成一個很實用的矩陣:
順著這張圖看,常見的提升方式可以分成四個位置:
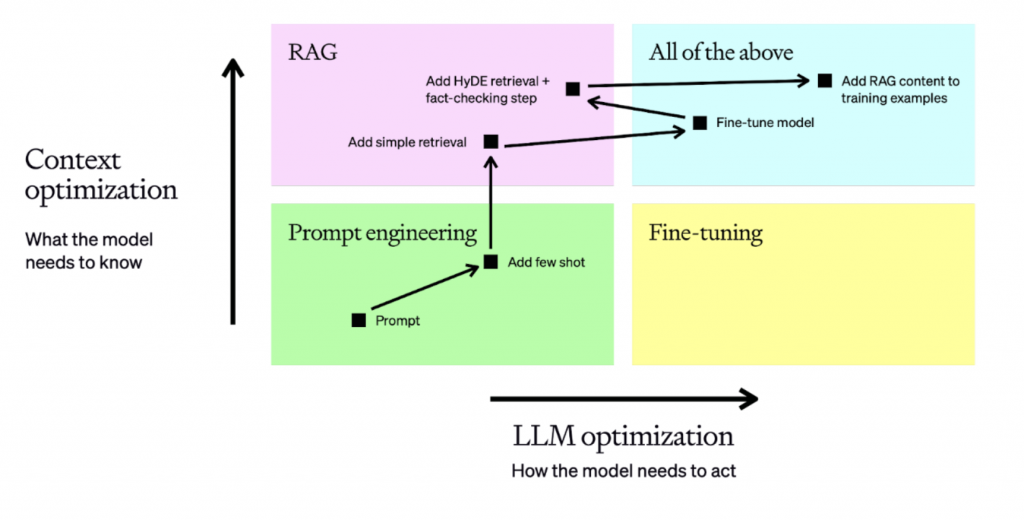
最左下角,是所有優化的起點。它不改模型,也不額外接入外部知識,而是透過更清楚的任務描述、格式要求、角色設定與 few-shot examples,讓模型先把原有能力發揮得更好。它最快、最便宜,也通常是第一步。
往上走,就是補外部 context。當模型不知道最新資訊、私有資料,或需要可追溯依據時,就不能只靠 prompt,而要先檢索外部知識,再把它放進 prompt。這就是 RAG 的核心。
往右走,就是補行為本身。當問題不在知識,而在輸出格式不穩、語氣不一致、規則遵守不好,或某種任務表現不夠穩定時,就要透過 fine-tuning 直接調整模型的權重,把這些行為更深地寫進模型裡。
右上角代表兩者疊加,一方面用 RAG 補最新或外部知識,一方面用 fine-tuning 強化模型行為與格式穩定性。這通常是更完整的解法,但做起來更耗時且複雜。
因此,不是一開始就該直接什麼優化都做,而是要根據問題到底缺的是 context 還是 behavior 來判斷。這些方法是可以 stack 的,但全都上不代表就一定最好,仍需根據不同情況制定優化策略。
單次呼叫 LLM,還只是模型在生成文字;當我們開始替它補上上下文、外部工具、執行流程與驗證機制時,它才真正變成一個系統。
這裡我們就要開始提到 Agent。它是一種處在環境中的自主系統,能感知環境、在環境中採取行動,並朝自己的目標前進。從這個角度來看,Agent 並不是獨立於 LLM System 之外的東西,而更像是 LLM System 的一種進一步實作:當系統開始能感知環境、調用工具、執行工作流,並根據回饋持續調整時,它就已經具備 agent 的核心特徵。讓我們先從構成 LLM System 的核心部件開始拆解。
模型是整個系統的智能核心,負責理解、推理與生成。沒有模型,就沒有 LLM System;但只有模型,也還不夠。
上下文決定模型當下看到了什麼。它包含 prompt、instructions、history、few-shot examples、retrieved documents,甚至 memory。很多時候,系統效果的差異,不在模型本身,而在 context 是否給對。
工具讓模型不只會說,還能做事。像是 search、database、calculator、code execution、API call,都是把模型連到外部世界的橋樑。
工作流決定系統怎麼完成任務。它負責安排步驟、決定何時檢索、何時調用工具、何時重試、何時反思。單次問答是最簡單的 workflow;一旦進入多步驟、可迭代、帶狀態的 loop,系統就開始往 agent 靠近。
評估系統決定整個 AI 系統能不能被信任。verifier、guardrails、human review、offline eval、online telemetry,這些都不是模型本身的一部分,卻往往決定這個系統最後能不能真的落地;而回饋系統則決定這個系統是否會跟著環境迭代進步。
簡單來說,一個完整的 LLM System,是將模型、上下文、工具調用、工作流、評估系統和回饋系統以不同的形式組合而成,用系統的角度去完善整個工程開發設計。
單一 LLM 提供的是語言智能的核心能力,但真正讓它能處理現實世界複雜任務的,並不是模型本身,而是圍繞它建立起來的上下文、知識注入、工具使用、工作流控制與回饋評估機制。當這些部件被組裝起來,LLM 才真正從一個會生成文字的模型,變成一個能解決問題的系統。
LLM 是起點,System 才是落地。
 Lucien
Lucien

 iThome鐵人賽
iThome鐵人賽