在強化學習(Reinforcement Learning, RL)裡,Q-learning 是最經典也最常見的演算法之一。它的目標很單純:讓一個智能體(Agent)透過與環境互動,不斷學習在不同情境下應該採取什麼行動,才能獲得最大的長期回報(Reward)。如果你聽過「試誤學習」這個概念,那 Q-learning 就是一種數學化、系統化的「試誤學習方法」。
Q-learning 的核心概念
在 Q-learning 裡,有一個核心的數值函數叫做 Q函數 (Q-value function)。
這個函數記錄了在某個「狀態 (state)」下,採取某個「動作 (action)」後,所能期待得到的「長期回報 (expected future reward)」。
可以把它想像成一張 價值表(Q-table):
橫軸:環境的狀態 (state)
縱軸:Agent 可以選的動作 (action)
表格的值:如果在某狀態下採取這個動作,未來能期待得到多少報酬(Q-value)
Agent 的任務就是 學會這張表,並在行動時 挑選 Q 值最高的動作,因為那通常代表「最划算」。
Q-learning 的更新公式
Q-learning 最重要的數學公式是 Q 值的更新規則: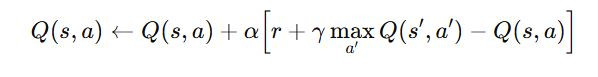
拆解一下這個公式:
Q(s,a):目前估計的 Q 值(在狀態 s 下做動作 a 的價值)。
α:學習率(learning rate),決定新知識要蓋掉多少舊知識。
r:採取動作後立刻得到的獎勵。
γ:折扣因子(discount factor),介於 0 到 1,決定我們有多看重「未來的報酬」。
max𝑎′𝑄(𝑠′,𝑎′)max:下一個狀態 s' 中最好的動作價值(代表未來的最佳選擇)。
白話來說:
「把現在的估計 𝑄(𝑠,𝑎)Q(s,a) ,往『實際得到的獎勵 + 未來可能的最大報酬』這個方向修正一點點。」
這就像學習一門遊戲:
你原本覺得按這個按鈕很爛(Q 值低),
但實際玩了幾次,發現這招有時候能帶來高分(獎勵 + 未來回報),
於是你就慢慢把這招的價值調高。
久而久之,這張 Q 表會越來越準確,Agent 也就能根據它做出「最優策略」。
學習流程
Q-learning 的學習過程大致上可以分成以下幾步:
初始化 Q 表
一開始 Q 值都是亂猜的(通常設成 0 或隨機),因為 Agent 對環境一無所知。
在環境中互動
Agent 在某個狀態下,選擇一個動作(通常會用 ε-greedy 策略:大部分時間挑 Q 值最高的動作,但偶爾隨機試試,以免陷入局部最佳)。
執行動作後,環境會回饋一個「獎勵」並進入下一個狀態。
更新 Q 值
使用上面的更新公式,把新經驗修正到 Q 表裡。
重複學習
透過不斷的「嘗試 → 獎勵回饋 → 更新」,Q 值會逐漸收斂,最終 Agent 就能掌握最好的行為策略。

