資料除了儲存在硬碟中,MySQL 還會將讀取過資料放在記憶體,用來提升查詢效能,但記憶體空間有限,無法把所有資料都放入,因此淘汰資料的策略就很重要了。
直覺上要淘汰不常用資料,但 MySQL 卻不是用 LFU (Least Frequently Used) 策略,因為 LFU 無法適應熱點資料變化,例如客服在某天頻繁查詢特定用戶的資料,但後續不再使用,該資料就會一直放在快取中,且許多業務情境 (e.g 電商 & 交易所 & 搶票) 新建立資料高機率會馬上被查詢,而 LFU 不適用於這種時間局部性,因為當 LFU 滿了,剛建立資料容易馬上被淘汰。
雖然 LRU 能彌補上述 LFU 缺點,但也會產生新問題,例如執行 SELECT * FROM users; 全表掃描,依照 LRU 最新載入資料要放進快取並逐出最後讀取資料,因此會把大量資料放進快取並逐出其他資料,然而全表掃描操作通常為排程任務,有許多非熱門資料,若因此排擠掉熱門資料那就得不償失了。
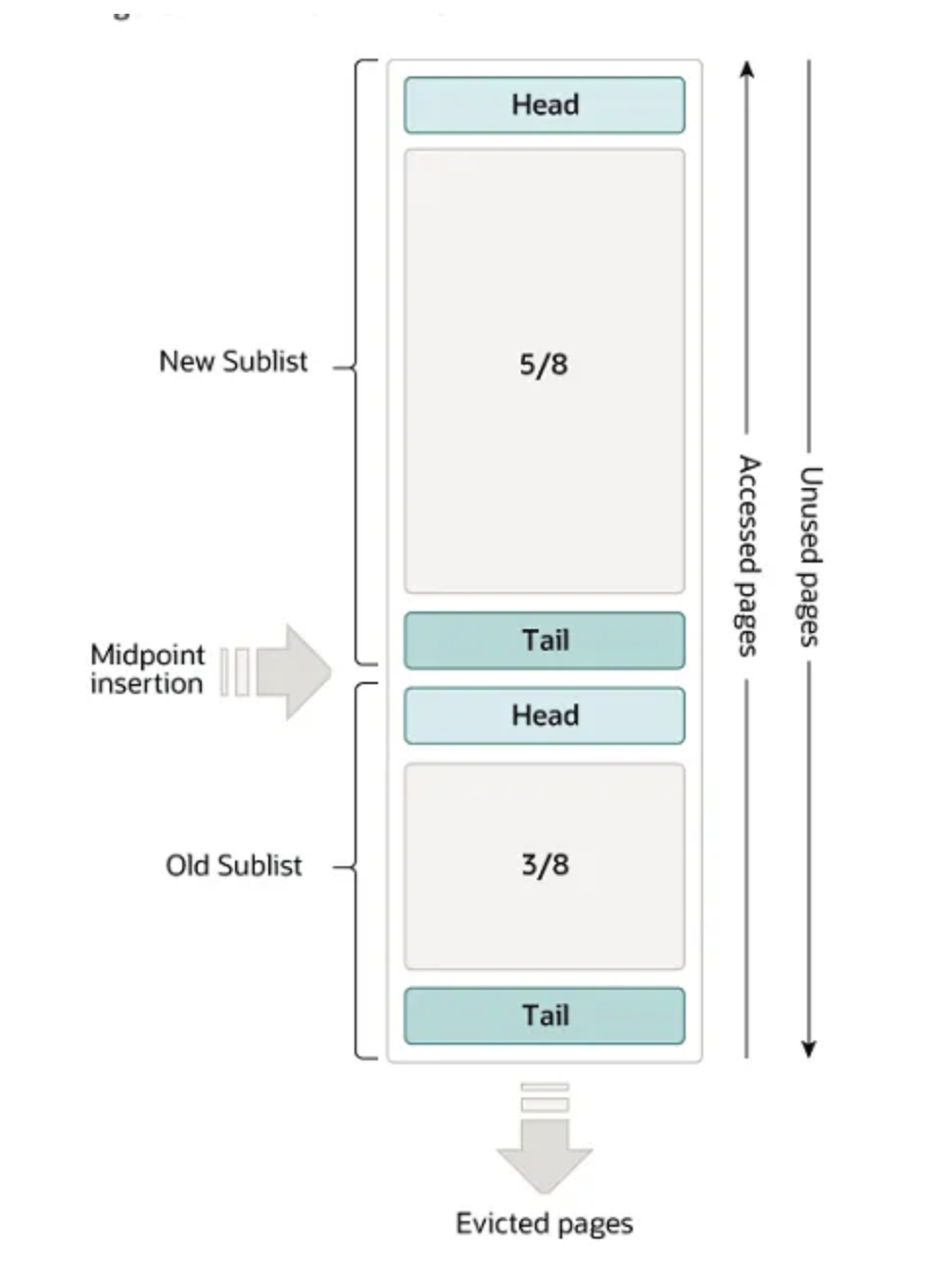
因此 MySQL 用兩個 LRU 結構,分別為 Old & New Sublist,新讀取資料會放到 Old Sublist 若反覆被讀取才放到 New Sublist,在 New Sublist 的資料為長期活躍資料且不受全表掃描影響,通常 Old Sublist 佔總快取的 38% 而 New Sublist 為 62%。
(圖片來源:https://dev.mysql.com/doc/refman/8.4/en/innodb-buffer-pool.html)
資料從 Old Sublist 搬移到 New Sublist 的時機為:
當資料位於 Old Sublist 後 3/4 段落中,且過 n sec 後再次被讀到才會移到 New Sublist,n sec 可透過 innodb_old_blocks_time 設定,預設 1 sec。
等 n 秒設計是因為 MySQL 快取單位為 Page,一個 Page 有多筆連續資料,如果是 Full Table Scan,相同 Page 短時間會被讀取多次,避免 Full Table Scan 搬大量 Page 到 New Sublist,需要等 n 秒設計,而不搬前 1/4 段落是因為這些資料還不會被踢除 ,搬這些資料到 New Sublist 效益比較低。
由於快取單位為 Page,因此快取中 hash map 結構的 key 為 (space_id, page_no):
SELECT * 時,會把 Secondary & Clustered Index 都放進快取。如果將快取單位改成紀錄,且 hash map 結構的 key 改為 (table_name, column_name, column_value),不僅查詢不用 traversal 整棵樹,也不用把多餘的 page 放進快取中,但缺點就是順序查詢 WHERE create_time > ? 時,要不斷讀取 hash map,且讀取 page 後要將 page 中紀錄一筆筆放到 hash map 會消耗較多 CPU。
另外只放 page 中有命中的紀錄到快取,雖然比較高效跟省空間,但資料查詢除了時間局部性還有空間局部性,例如執行完 id = 1 後,id=2 高機率未來會被用到,因此放整個 page 能提高快取命中率並降低 I/O 次數,此外 MySQL 還提供兩個 read-ahead 功能優化空間局部性。
Linear read-ahead:
如果 extent 中 page 依照物理位置順序被讀取,MySQL 會把物理位置的下一個 extent 透過異步 process 載入到記憶體中,可透過 innodb_read_ahead_threshold 參數設定多少個 page 被連續讀取才觸發。
note : 注意這裡的物理順序不代表 b+tree 的順序,是硬碟連續空間的意思。
Random read-ahead:
如果一個 extent 內有許多 page 被隨機讀取,MySQL 會把整個 extent 透過異步 process 載入到記憶體中,可透過 innodb_random_read_ahead 開關開啟,官方說如果連續隨機讀取到 13 個 page 才會觸發。
大部分情況需要 traversal B+Tree 所以會是 O(LogN),但 MySQL 提供了 Adaptive Hash Table (AHT) 記憶體結構,可透過 innodb_adaptive_hash_index 參數開啟,其 key 類似 (table_name, column_name, column_value) 而 value 是指向 Buffer Pool 中儲存資料的 leaf page。
AHT 大小是動態調整的,會根據查詢情況決定新增或刪除 key,雖然 AHT 能讓快取查詢變成 O(1),但缺點是高併發下 AHT 效能會很差,因為讀取 AHT 會觸發動態更新,因此多個讀也要競爭相同鎖,若要提高 AHT 併發效能可調整 innodb_adaptive_hash_index_parts 會建立多個 AHT partition。
而從 Buffer Pool 讀取就是單純讀取,所以可用讀寫鎖,併發讀取效能較好,此外也可調整 innodb_buffer_pool_instances 參數建立多個 Buffer Pool partition。


 iThome鐵人賽
iThome鐵人賽