「數位時代最有價值的資源不是黃金,而是你能不能找到、整理、再利用資訊。」
在 Day 8 裡,我們已經學會了怎麼用 HTTP Request 節點 把網頁的程式碼(HTML)請回來。
不過問題來了:那一大串 HTML 對我們來說就像一本亂碼的字典,要怎麼從裡面挑出我們想要的「書名」和「網址」呢?
今天,我們就要動手做一個「篩選器」,從龐雜的程式碼裡只抓取有用的資訊,並轉成可以下載的 CSV 檔案。
流程會是:
在開始前,我們要先搞清楚「網頁是怎麼組成的」。
👉 在爬資料的時候,最重要的就是 CSS,因為它能幫我們「指定」到底要抓哪個部分。這個指定方式就叫做 CSS Selector(選擇器)。
在網頁上 右鍵 → Inspect(檢查元素),就會出現一個分割視窗,裡面全是程式碼。
這時候,可以找到一個小按鈕(例如 Chrome 叫「Select element」),點下去,然後把滑鼠移到網頁上的「書名」。
當你點選書名,右邊的程式碼就會自動定位到對應的 HTML。
例如:
書 1:<a href="catalogue/a-light-in-the-attic_1000/index.html" title="A Light in the Attic">A Light in the ...</a>
書 2:<a href="catalogue/tipping-the-velvet_999/index.html" title="Tipping the Velvet">Tipping the Velvet</a>
一般來說,HTML 元素大多是這樣的形式:
<element attribute="Attribute">Text</element>
也就是說,一個元素同時會包含「屬性(attribute)」和「文字內容(Text)」,許多這樣的元素組合起來,就形成整個網頁。
我們觀察這兩個元素,以我們所抓取的網站為例:
title="A Light in the Attic"
title="Tipping the Velvet"
A Light in the ...
Tipping the Velvet
這表示,如果我們想要拿到完整的書名,最佳方式就是去讀取 attribute「title」的值。
同時,我們也可以右鍵複製它的 Selector Path(選擇器路徑),用來定位元素。
例如書 1 與書 2 的 Selector Path:
Slector Path-1:
body > div > div > div > div > section > div:nth-child(2) > ol > li:nth-child(1) > article > h3 > a
Slector Path-2:
body > div > div > div > div > section > div:nth-child(2) > ol > li:nth-child(2) > article > h3 > a
雖然完整路徑不同,但最後的相對路徑「article > h3 > a」是一樣的,代表「所有書的標題元素」都符合這個規則。
這就是我們等一下在 n8n 裡要用的 CSS Selector。
接下來,回到 n8n。
在上一次的流程裡,我們已經有:
現在,新增一個節點:
Extract HTML Content
在「Extraction Values」裡輸入:
Title
article > h3 > a
Attribute
title
執行之後,Output 就會列出書目中每本書的標題! 🎉
最後,再新增一個節點:
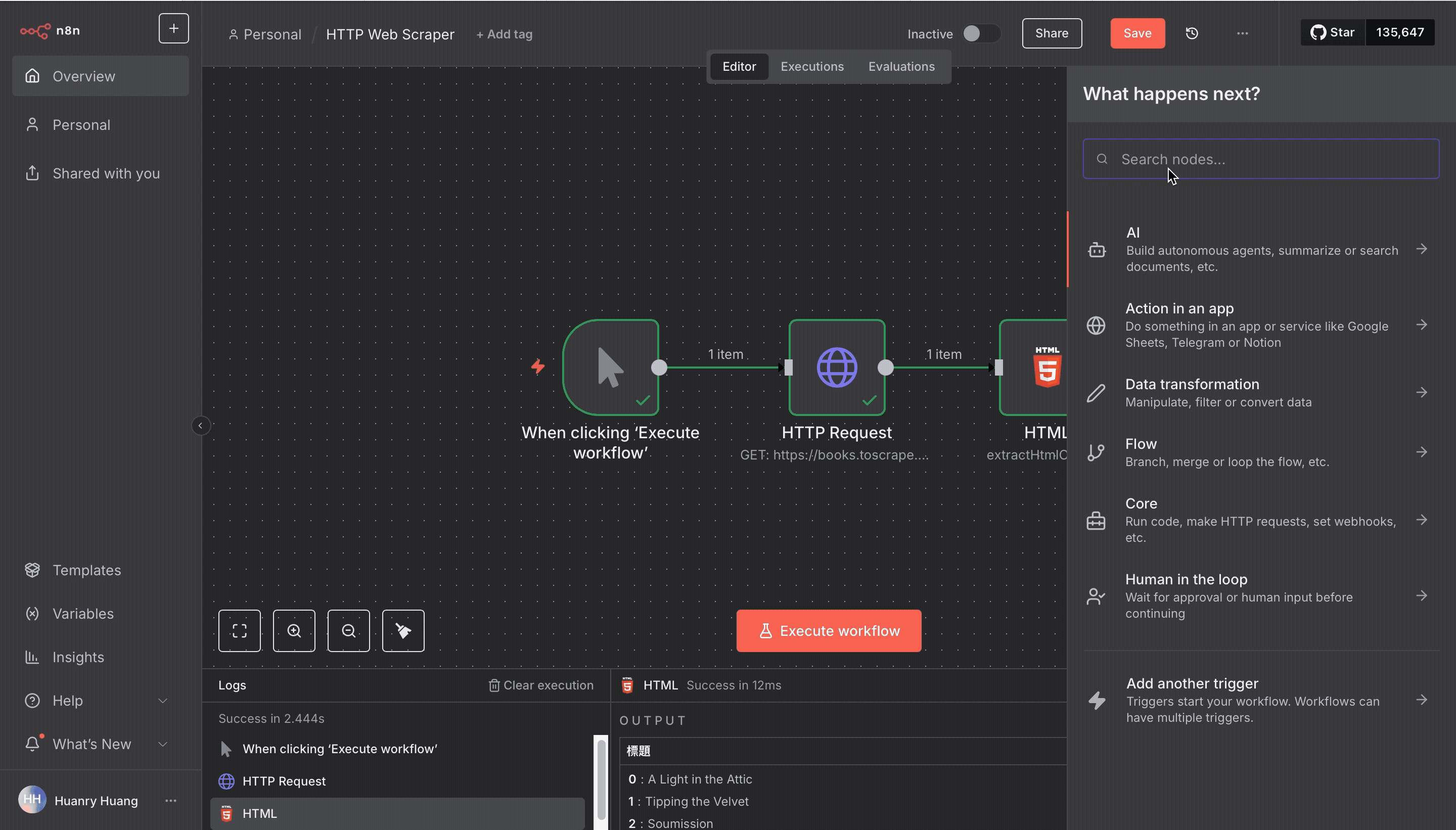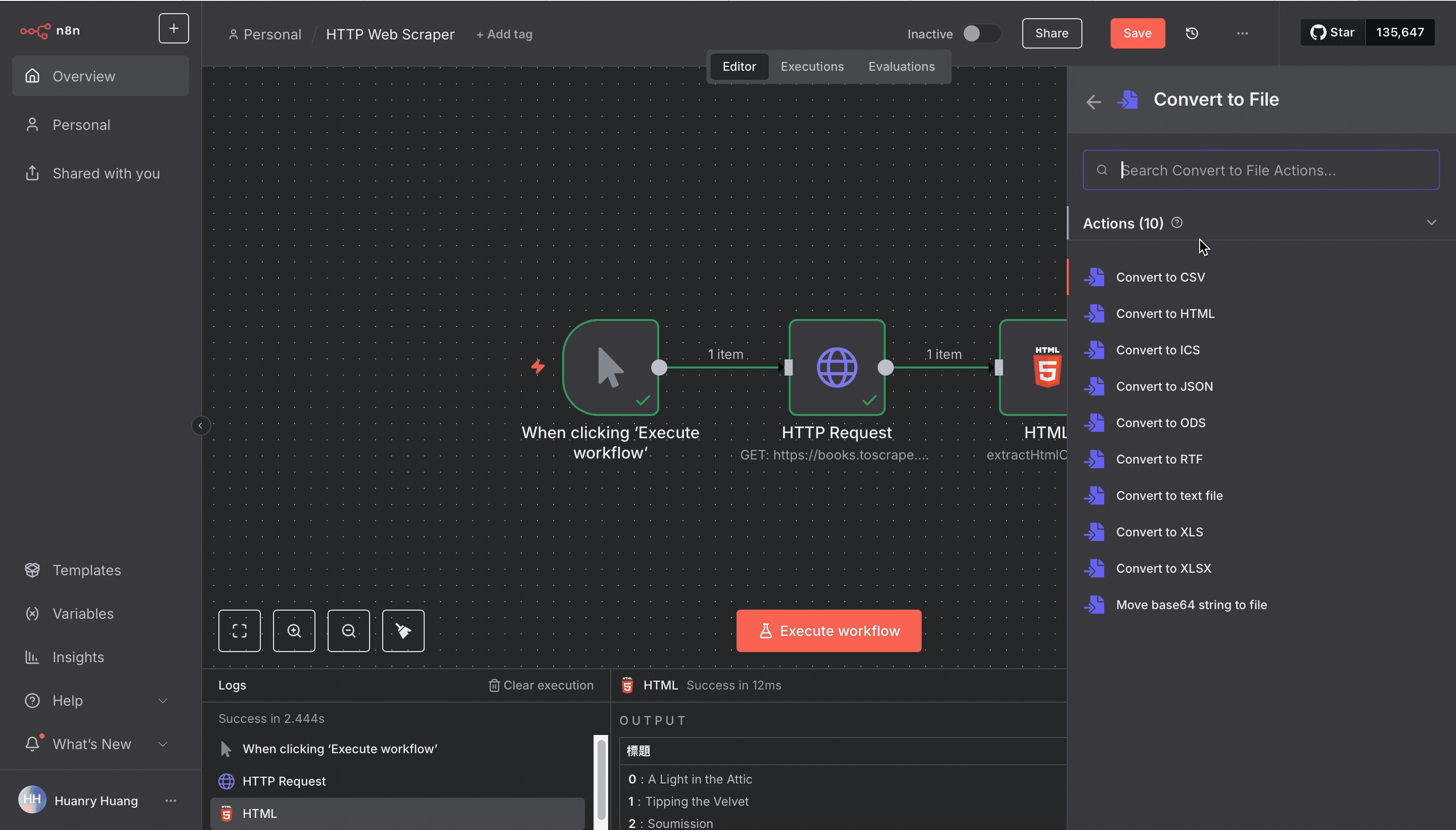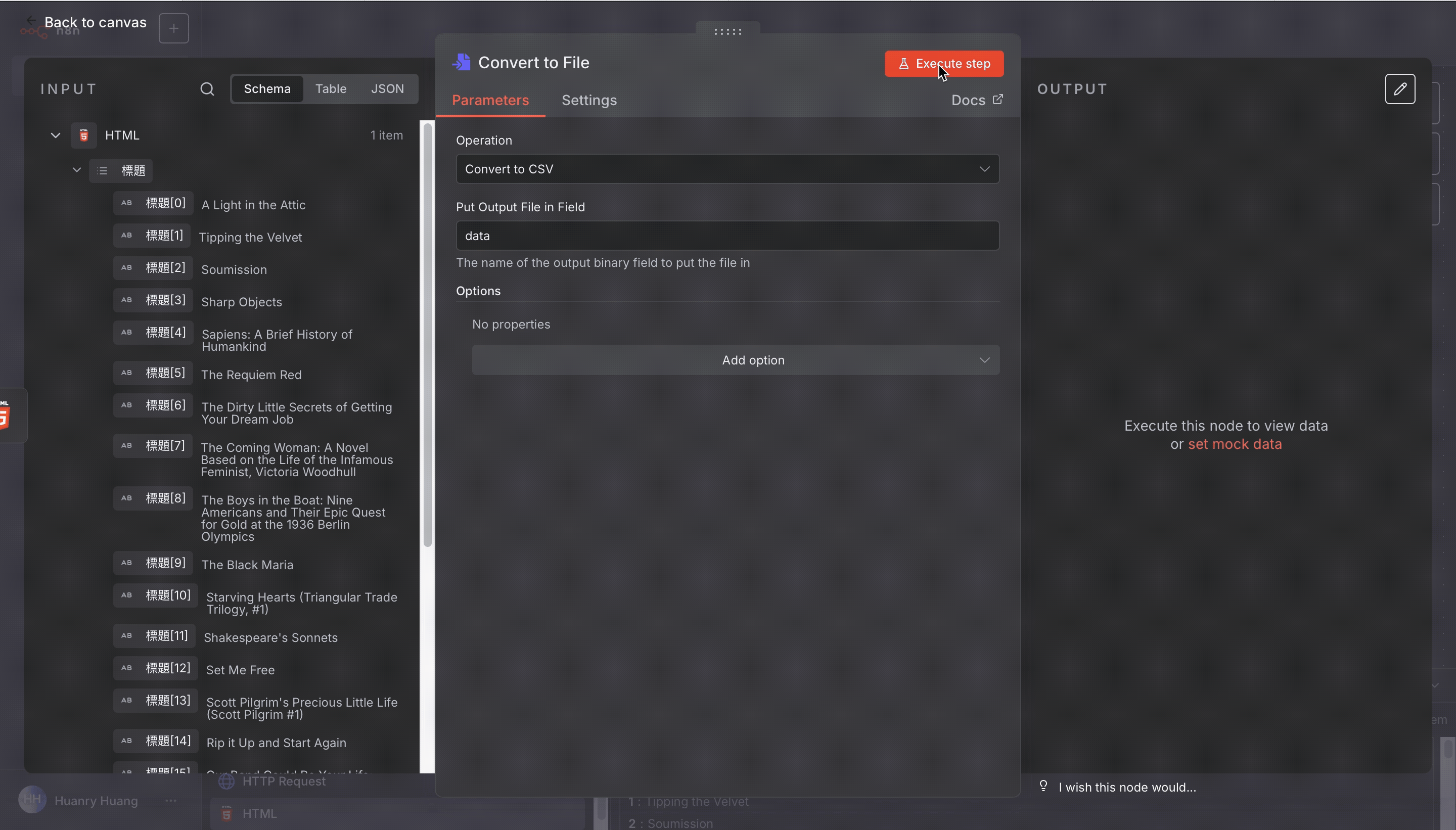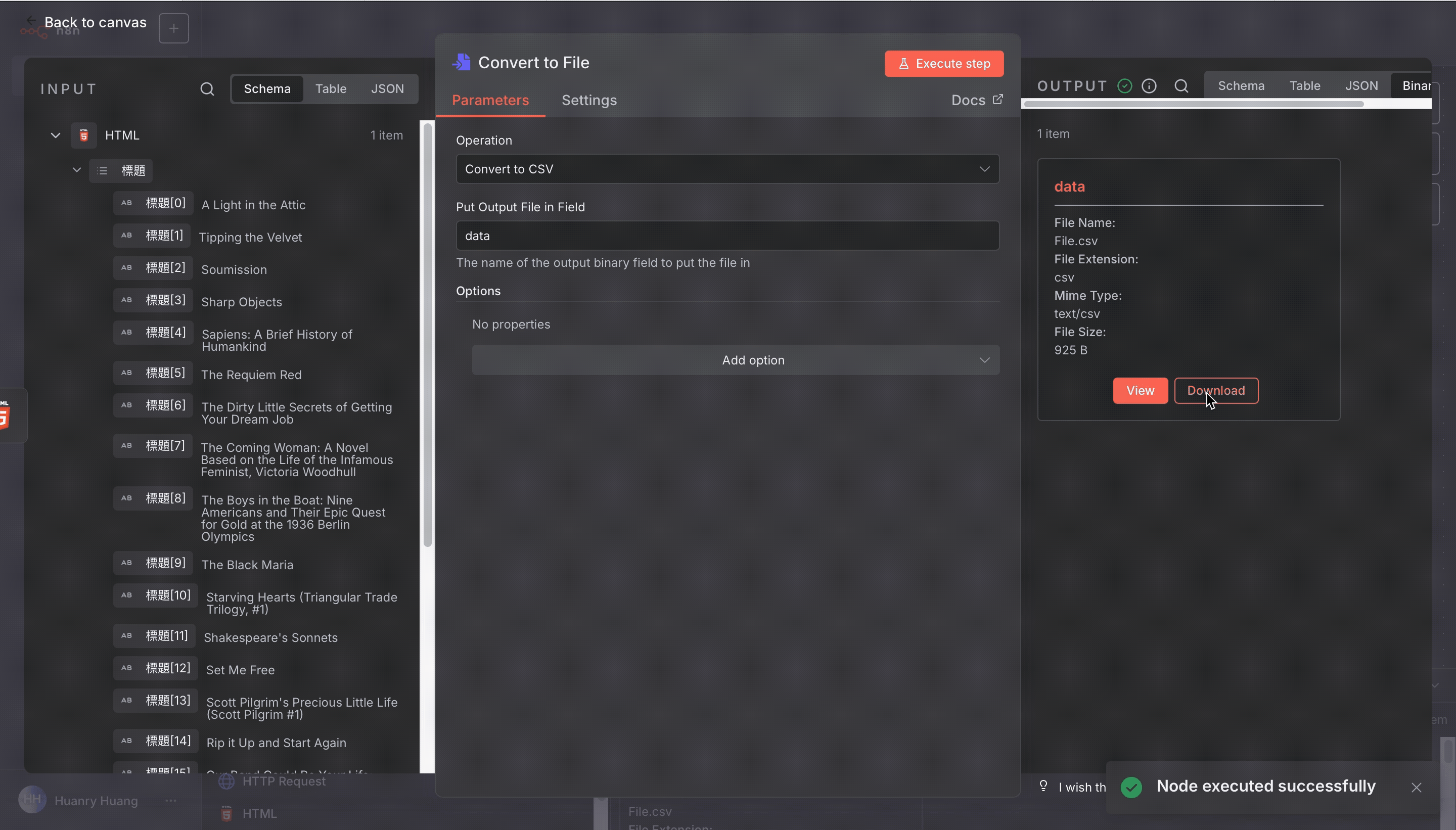
Convert to File → CSV
執行之後,你會看到 Download 按鈕,點擊就能下載 CSV 檔案。
打開來,就能看到整整齊齊的書名清單。
到這裡,我們已經學會了:
不過要注意,這個方法只適合「結構單純」的靜態網頁。
很多現代網站有更複雜的動態載入機制,就需要更進階的技巧。
然而,用 Selector 抓資料的方法,看似清楚,卻有幾個挑戰:
所以我們要換個角度思考:如果門檻太高,不一定要硬著頭皮自己寫程式,善用第三方工具(甚至是無程式碼工具)也是一種很聰明的做法。後面我也會介紹其他更簡單的方法。
這次我們只提取了書名。
請你嘗試看看:
我建立了一個行銷技術交流群,專注討論 SEO、行銷自動化等主題,歡迎有興趣的朋友一起加入交流。
掃QR Code 或點擊圖片加入


