當你被技術卡住時,別忘了換個角度,有時不是自己硬闖,而是找到能幫你開門的鑰匙。
在 Day 8 我們學過,透過 HTTP Request 可以拿到網頁的 HTML 程式碼。
HTML 本質上就是一堆文字標籤,瀏覽器則是把它「翻譯」成我們眼睛看到的畫面。
不過,現實沒這麼簡單。
有些網頁,你直接抓 HTML,卻什麼都看不到!
這是因為:
舉個例子,我們打開這個頁面(這是過去我曾做過SEO共學小組的活動頁):
👉 https://www.accupass.com/event/2105031734251520643298
然後查看它的 HTML 原始碼。
結果發現:完全沒有網頁上顯示的活動資訊!
這也是為什麼很多人說:爬蟲技術是門大學問。
n8n 本身不是爬蟲工具,它的強項是「把工具串起來」。所以我們需要借助更專業的工具來補足。
今天介紹一個好用又簡單的第三方服務 Jina.ai Reader API。
它能幫你:
只要在網址前加上前綴:
https://r.jina.ai/
例如:
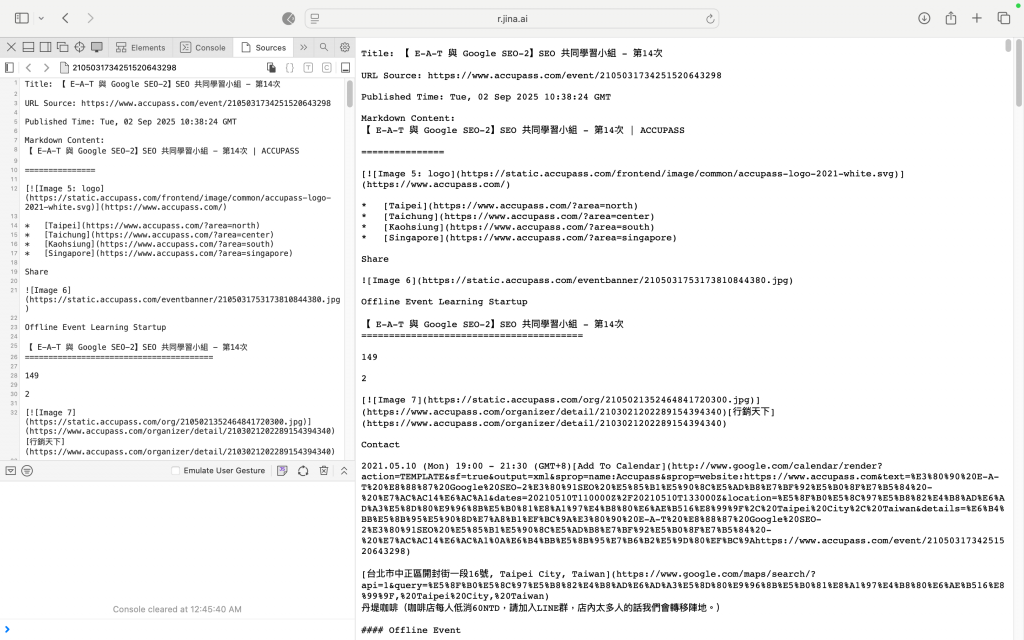
👉 https://r.jina.ai/https://www.accupass.com/event/2105031734251520643298
這樣就能獲取整理過的內容。
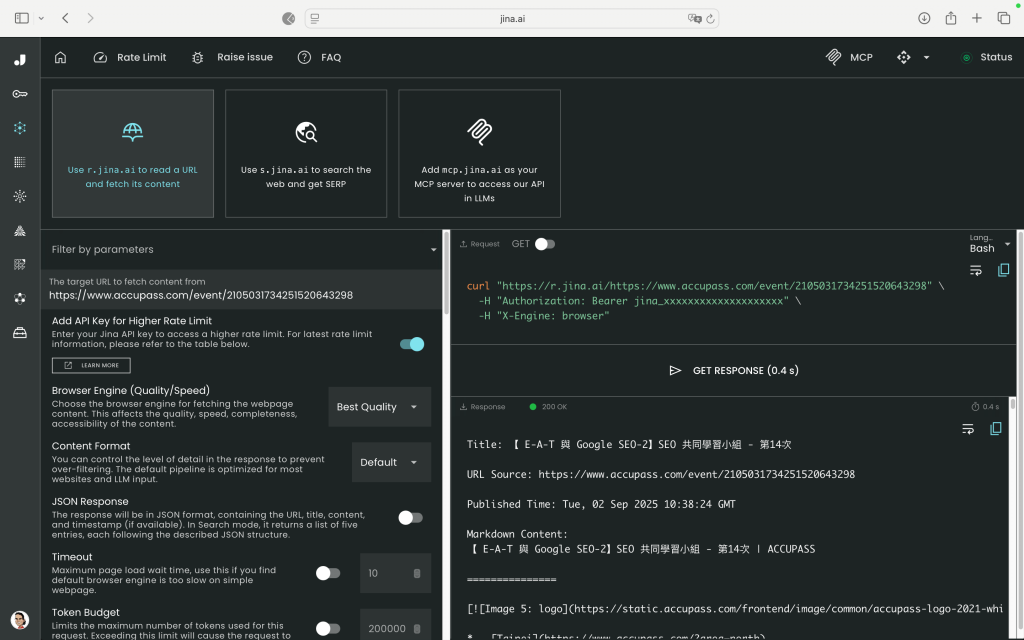
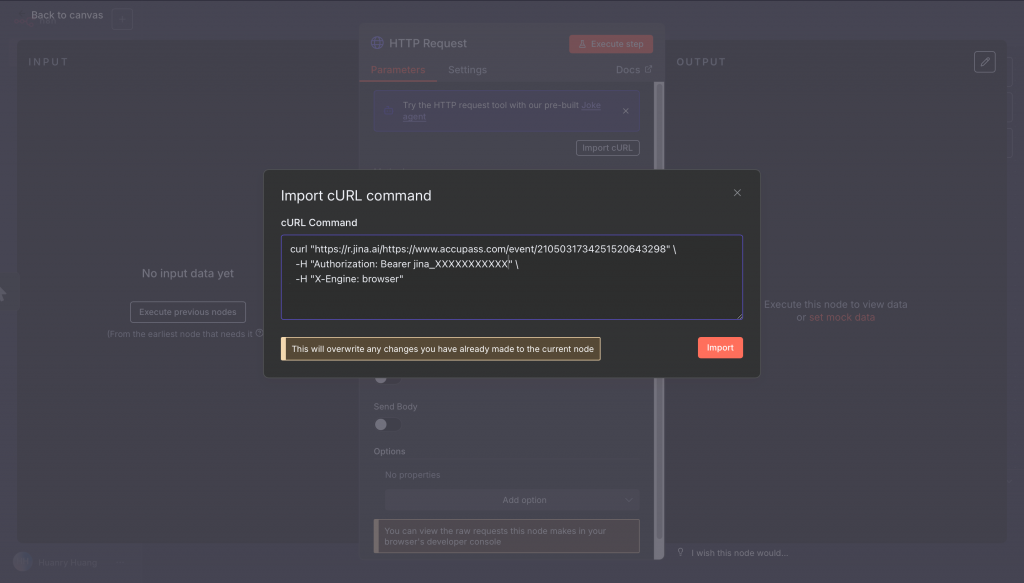
👉 什麼是 cURL?
想像它是一種「命令列瀏覽器」。
我們平常在瀏覽器輸入網址,會看到漂亮的網頁畫面;
而用 cURL,拿到的是背後的「原始資料」:JSON、文字,方便程式直接用。
當我們在這個測試面板,確認了某種參數組合能拿到需要的資訊,就可以把那段 cURL 指令複製下來。接著,我們就能在 n8n 裡重現這個操作。
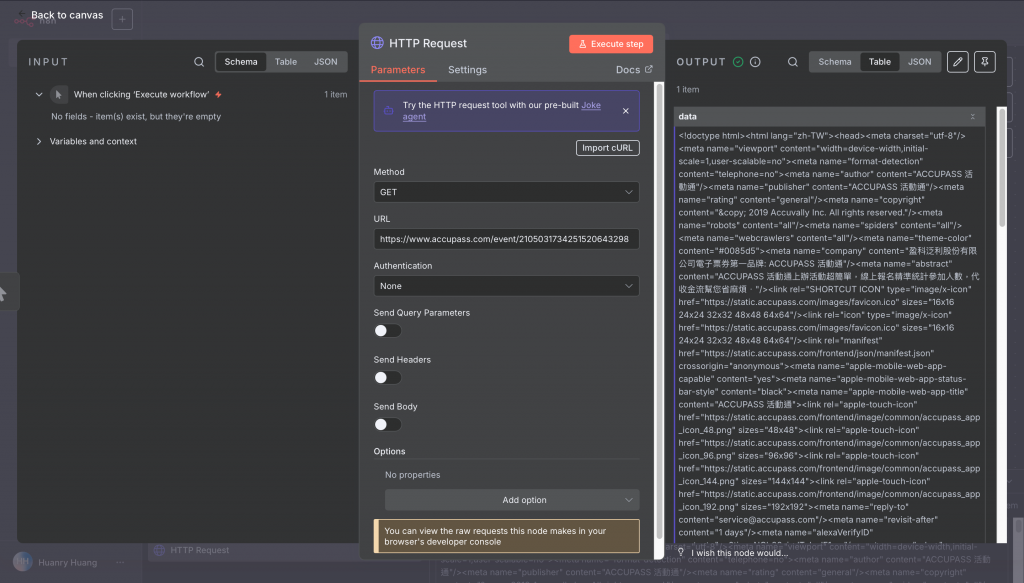
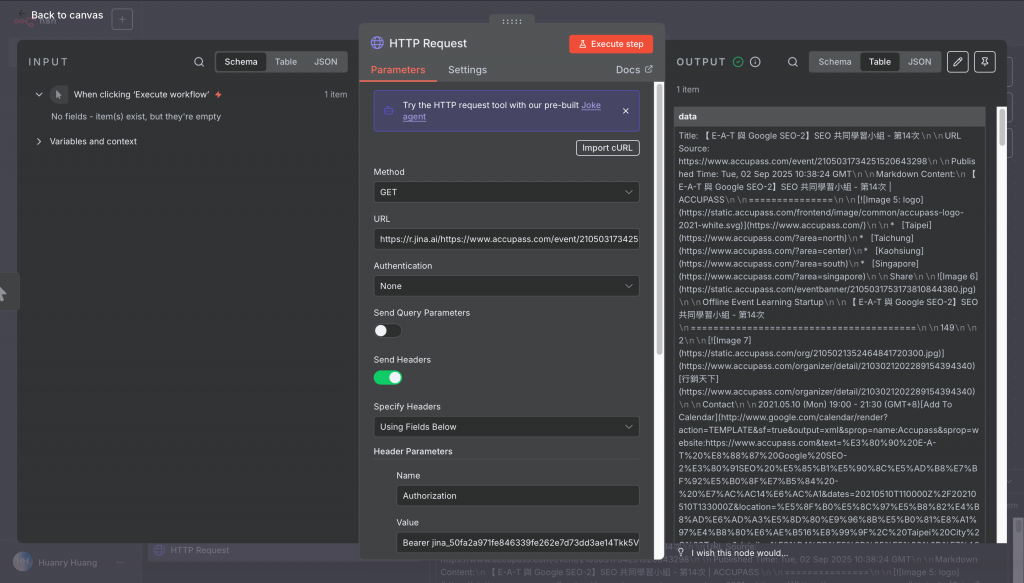
透過這樣的方式,我們就能把 n8n 的能力擴充,處理那些單靠 HTTP Request 拿不到的資料。
你可以把 Jina.ai 想成「外包助手」:
不過要注意,每個 API 都有自己的限制,可能需要不同的參數設定。
而這些參數該怎麼調?其實也可以再交給 AI 幫忙。
在下一篇,我們就要來談 「把工具交給 AI 自己操作」 也就是最近很火的 MCP(Model Context Protocol) 概念。
試著用 Jina.ai 去抓一個你常用的網站:
https://r.jina.ai/ 前綴測試看看。我建立了一個行銷技術交流群,專注討論 SEO、行銷自動化等主題,歡迎有興趣的朋友一起加入交流。
掃QR Code 或點擊圖片加入


