當在 Twitter 上分享一個長達 200 個字元的商品連結時,短網址服務悄悄地將它變成了簡潔的
bit.ly/abc123。這個看似簡單的轉換背後,隱藏著每秒處理數十萬請求、確保毫秒級回應、防範惡意攻擊的複雜系統設計。今天我們要探討的不只是如何產生短碼,更要理解如何設計一個能夠承載十億級請求的短網址服務。
場景定義與需求分析
業務場景描述
想像你正在經營一個行銷平台,客戶需要在社群媒體、簡訊、Email 中分享產品連結。原始連結可能包含複雜的追蹤參數,長度超過 500 個字元。你需要一個短網址服務來:
- 讓連結在字數限制的平台(如 Twitter)中更容易分享
- 追蹤點擊數據,提供行銷分析
- 隱藏真實 URL 結構,保護商業邏輯
- 提供品牌化的短連結,增強識別度
這不僅是技術問題,更是商業價值的體現。一個穩定、快速、可分析的短網址服務,直接影響著數位行銷的成效。
核心需求分析
功能性需求
-
URL 縮短:將長網址轉換為 6-8 位字元的短碼
-
URL 還原:根據短碼快速重定向到原始網址
-
自訂短碼:允許用戶指定易記的短碼(如 brand.ly/summer2024)
-
點擊統計:記錄訪問次數、來源、裝置等資訊
-
過期管理:支援設定連結有效期限
-
批次處理:支援 API 批次建立短網址
-
黑名單管理:防止惡意網址的縮短服務
非功能性需求
-
效能要求:URL 重定向的 P99 < 50ms
-
併發量:100K QPS ,尖峰時段的讀取請求
-
可用性:99.99% SLA ,年度停機時間 < 52 分鐘
-
資料規模:10 億條記錄 ,系統需支援的 URL 總數
-
擴展性:水平擴展 ,可透過增加節點提升容量
-
安全性:防止短碼猜測,避免連續短碼洩露資訊
核心架構決策
識別關鍵問題
技術挑戰 1:短碼生成策略
- 影響:決定系統的擴展性上限與效能表現
- 核心問題:如何在確保唯一性的同時維持高效能
技術挑戰 2:高併發讀取優化
- 影響:直接影響使用者體驗與系統成本
- 核心問題:如何在數十億資料中實現毫秒級查詢
技術挑戰 3:資料一致性與快取策略
- 影響:決定系統的可靠性與維護複雜度
- 核心問題:如何平衡快取命中率與資料正確性
短碼生成方案比較
| 維度 |
雜湊演算法 |
計數器方案 |
預生成池 |
雪花演算法 |
| 核心特點 |
MD5/SHA 後取前 N 位 |
自增 ID 轉 Base62 |
預先產生短碼池 |
分散式 ID 生成 |
| 優勢 |
無狀態、實作簡單 |
短碼長度可控 |
效能最佳 |
可排序、含時間戳 |
| 劣勢 |
可能碰撞、需處理 |
需要全域計數器 |
需要額外儲存 |
短碼較長 |
| 適用場景 |
小規模系統 |
中等規模 |
高併發場景 |
需要時序性 |
| 複雜度 |
低 |
中 |
中 |
高 |
| 成本 |
最低 |
低 |
中 |
中 |
決策思考框架
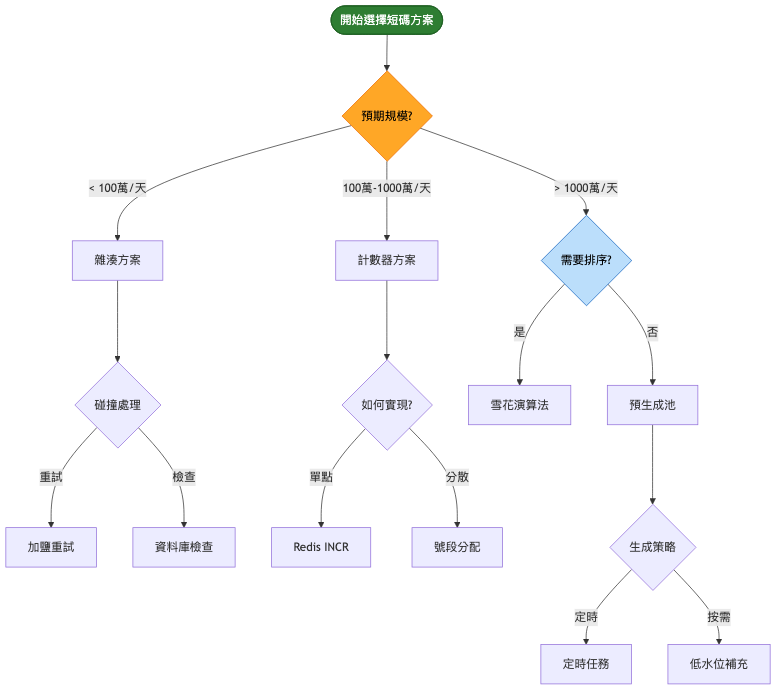
系統演進路徑
第一階段:MVP(0-10萬 / 使用者)
架構重點:
- 單體應用快速迭代
- 使用 PostgreSQL 儲存映射關係
- Redis 做熱點資料快取
- Nginx 處理靜態重定向
系統架構圖:
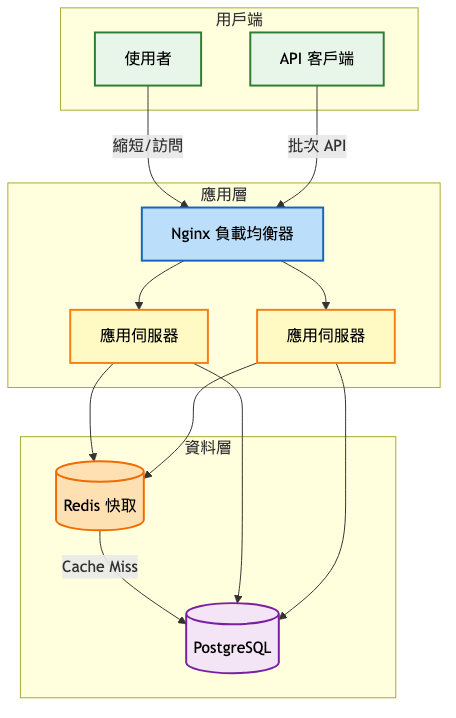
為什麼這樣設計:
-
計數器方案:簡單可靠,避免碰撞問題
-
Redis 快取:減少資料庫壓力,提升回應速度
-
非同步統計:不阻塞主要重定向流程
-
批次同步:減少資料庫寫入次數
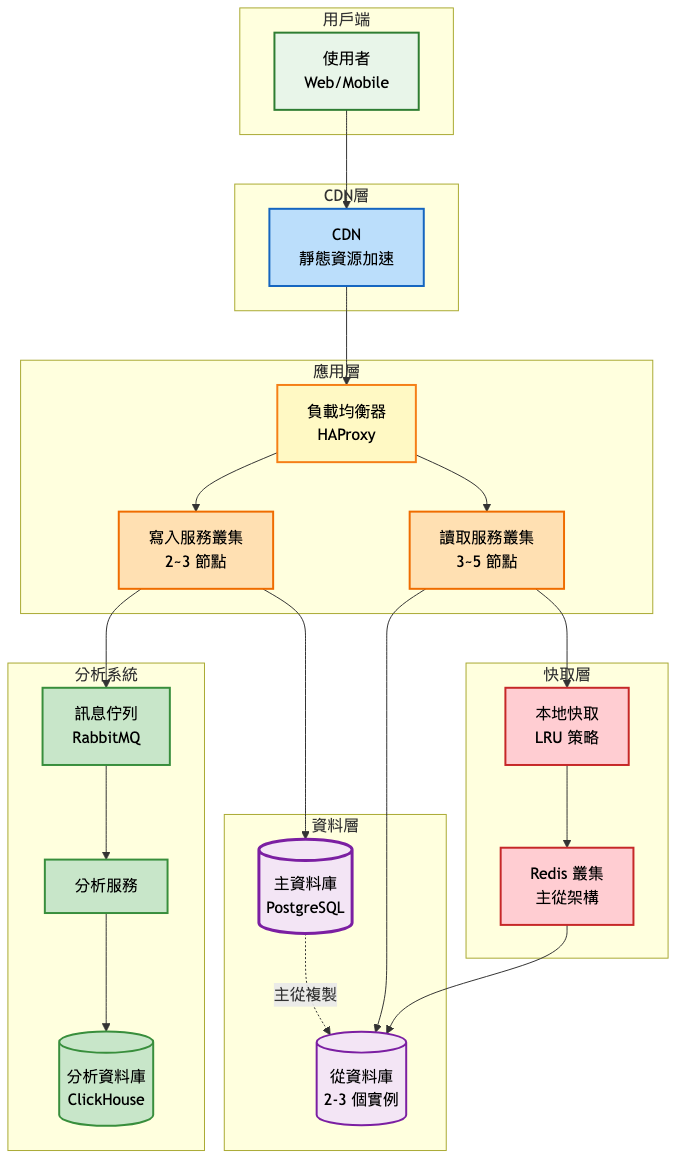
第二階段:成長期(10萬-1000萬 / 使用者)
架構演進重點:
- 讀寫分離,主從複製
- 多層快取架構(本地快取 + Redis)
- 引入訊息佇列處理統計
- CDN 加速靜態資源
主要系統架構圖:
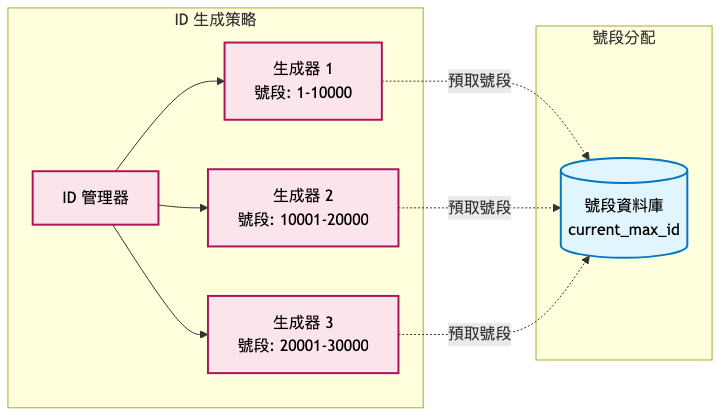
分散式 ID 生成架構:
關鍵設計變更:
-
分散式短碼生成
- 原因:單點計數器成為瓶頸
- 實施方式:號段分配策略,每個節點預先獲取一段 ID 範圍
- 預期效果:每個節點獨立生成,無需同步,提升 10 倍生成速度
-
多層快取架構
- 原因:Redis 連線成為瓶頸
- 實施方式:LRU 本地快取(5000 項)+ Redis 分散式快取
- 預期效果:減少 90% Redis 請求,降低網路開銷
-
讀寫分離架構
- 原因:讀取請求佔比達 95% 以上
- 實施方式:主資料庫處理寫入,2~3 個從庫分擔讀取
- 預期效果:讀取能力線性擴展,支撐百萬級併發
第三階段:規模化(1000萬+ / 使用者)
企業級架構特點:
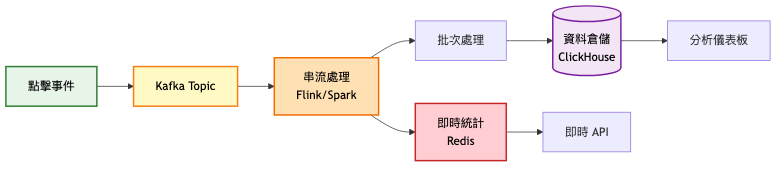
高層架構總覽:
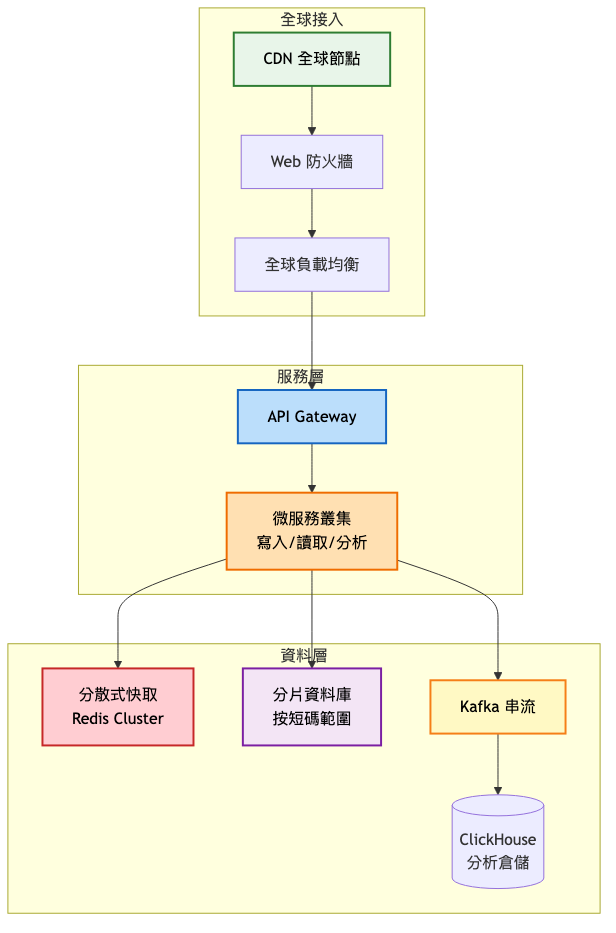
資料分片策略:
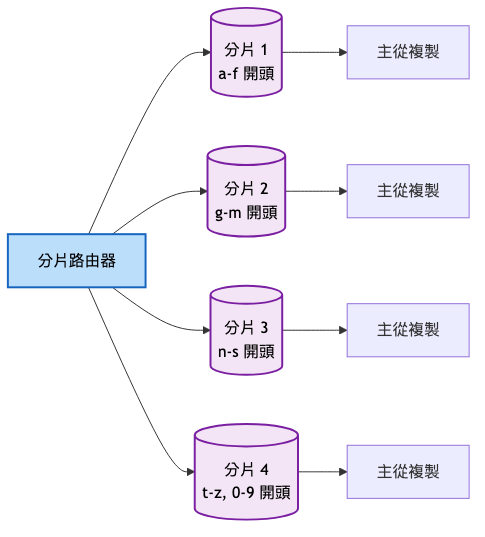
多區域部署架構:
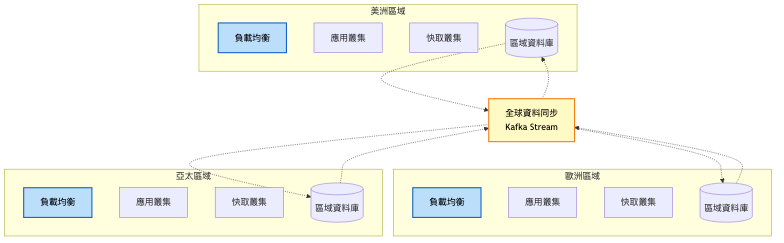
即時分析資料流:
架構設計考量:
-
高可用性設計
- 多區域部署,就近訪問
- 主從自動切換,故障轉移
- 熔斷降級機制
-
擴展性規劃
- 按短碼範圍分片(如 a-z 開頭分到不同分片)
- 讀寫分離,獨立擴展
- 無狀態設計,水平擴展
-
營運效率
技術選型深度分析
關鍵技術組件比較
| 技術選項 |
優勢 |
劣勢 |
適用場景 |
| 資料庫 |
|
|
|
| PostgreSQL |
ACID 保證、成熟穩定 |
單機效能上限 |
MVP 階段 |
| MySQL + Vitess |
水平擴展、相容性好 |
運維複雜 |
成長期 |
| TiDB |
分散式事務、自動分片 |
成本較高 |
規模化階段 |
| 快取 |
|
|
|
| Redis |
效能極高、功能豐富 |
記憶體成本 |
全階段 |
| Memcached |
簡單高效 |
功能單一 |
純快取場景 |
| Hazelcast |
分散式、自動發現 |
Java 生態 |
企業級 |
| 訊息佇列 |
|
|
|
| RabbitMQ |
可靠性高、易用 |
吞吐量限制 |
中小規模 |
| Kafka |
超高吞吐、持久化 |
複雜度高 |
大規模 |
| Pulsar |
多租戶、儲存分離 |
生態較新 |
雲原生 |
技術演進策略
-
初期技術:PostgreSQL + Redis + Nginx
-
成長期調整:加入 RabbitMQ、讀寫分離、CDN
-
成熟期優化:分散式資料庫、Kafka、全球部署
實戰經驗與教訓
常見架構陷阱
-
短碼長度規劃不當
- 錯誤:使用 4 位短碼,很快耗盡
- 正確:預留 6-8 位,考慮未來成長
- 原因:改變短碼長度需要資料遷移,成本極高
-
忽視快取雪崩
- 錯誤:所有快取同時過期
- 正確:隨機過期時間、多級快取
- 原因:瞬間大量請求會壓垮資料庫
-
統計即時寫入
- 錯誤:每次點擊都寫資料庫
- 正確:批次寫入、非同步處理
- 原因:寫入會成為效能瓶頸
業界案例分析
案例:Bitly 的架構演進 參考資料
發展歷程
-
初期(2008-2012)
- 架構特點:Ruby on Rails 單體應用,在 Betaworks 內部孵化
- 技術:MySQL 作為主要資料庫,Memcached 處理快取需求
- 規模:開始時處理每天數百萬短網址請求,快速成長至每月數億次點擊
-
成長期(2012-2016)
- 主要改進:轉向服務導向架構(SOA),將單體應用拆分為數十個小型服務
- 遇到的挑戰:MySQL 寫入瓶頸、全球用戶的延遲問題、需要更好的水平擴展能力
- 解決方案:引入 Cassandra 處理大規模資料儲存、實施多資料中心部署、開發 NSQ 分散式訊息系統
-
規模化時期(2016-2020)
- 架構革新:使用 Go 語言重寫核心服務,提升效能 10 倍以上
- 技術升級:採用 Kafka 作為事件串流平台、Kubernetes 容器編排、微服務架構
- 規模突破:每月處理 90-110 億次點擊,覆蓋 40 億個瀏覽器,400+ 伺服器支撐全球服務
關鍵學習點
-
學習點 1:服務隔離是分散式系統的核心 - Bitly 採用 SOA + 佇列 + 非同步訊息的組合,讓各元件能獨立運作、併發處理工作,單一服務故障不會導致整體系統崩潰
-
學習點 2:事件驅動優於命令驅動 - 使用「X 發生了」的事件風格訊息,而非「執行 X」的命令風格,實現更好的服務隔離並自然支援多個消費者處理同一事件
-
學習點 3:地理分佈需要及早規劃 - 全球化服務的延遲問題難以在後期解決,初期就應考慮多資料中心架構和邊緣節點部署
-
學習點 4:選擇正確的儲存方案勝過優化查詢 - 從 MySQL 遷移到 Cassandra 解決了寫入瓶頸,證明選擇適合場景的資料庫比不斷優化 SQL 更有效
-
學習點 5:監控系統與主系統同等重要 - 「如果沒有 Nagios 監控,那它幾乎肯定已經壞了,你只是還不知道」- 完善的監控讓 400 台伺服器的運維成為可能
技術債務與重構決策
Bitly 的 Go 語言重寫決策展示了技術債務管理的最佳實踐。他們沒有一次性重寫整個系統,而是採用漸進式重構策略,優先重寫高負載的核心服務,保持新舊系統並行運作,直到新系統證明穩定性後才完全切換。這種方式讓他們在保持服務可用性的同時,實現了 10 倍的效能提升。
監控與維護策略
關鍵指標體系
技術指標:
- P50/P95/P99 延遲(目標:< 20ms/50ms/100ms)
- QPS(目標:100K+)
- 快取命中率(目標:> 95%)
- 錯誤率(目標:< 0.01%)
業務指標:
- 日活躍短網址數量
- 短碼使用率
- 惡意連結攔截率
- API 調用量與配額使用
維護最佳實踐
-
自動化策略
- 自動擴容:根據 QPS 自動調整實例數
- 自動清理:定期清理過期連結
- 自動備份:增量備份 + 定期全量備份
-
監控告警
- 應用層:APM 工具(如 New Relic)
- 基礎設施:Prometheus + Grafana
- 業務層:自定義 Dashboard
-
持續優化
- 定期壓測,發現瓶頸
- A/B 測試新演算法
- 逐步遷移到新技術推疊
總結
核心要點回顧
-
短碼生成的權衡:在簡單性、效能、擴展性之間找平衡
-
多層快取的重要性:這是達到毫秒級回應的關鍵
-
統計系統的解耦:不要讓分析需求影響核心服務
-
預留擴展空間:短碼長度、資料分片策略都要考慮未來
設計原則提煉
-
簡單開始,逐步演進:不要過度設計,但要預留演進路徑
-
讀寫分離是必然趨勢:短網址服務讀遠大於寫
-
快取不是萬能藥:要考慮快取失效、雪崩等問題
-
監控先於優化:沒有數據支撐的優化都是盲目的
-
安全不能事後補:從一開始就要防範短碼猜測、惡意連結
下期預告
明天我們將設計「線上聊天室系統」,這將帶我們進入即時通訊的世界。
不同於短網址的請求-回應模式,聊天室需要處理 WebSocket 長連接、訊息即時推送、線上狀態管理等全新挑戰。
我們會探討如何實現訊息的可靠傳遞、如何處理斷線重連、如何設計可擴展的即時通訊架構。準備好迎接即時性的挑戰了嗎?
參考資源
Bitly 架構演進與案例分析
開源專案與工具
系統設計教學資源
雲端架構參考
延伸學習資源


 iThome鐵人賽
iThome鐵人賽