想像一下,你的團隊正在管理一個擁有數千個微服務的電商平台。每天需要部署數百次更新,處理數百萬個請求,還要確保系統在硬體故障時能自動恢復。 手動管理這些容器幾乎是不可能的任務。這時,你需要的不只是容器技術,而是一個能夠自動化管理整個容器生命週期的編排平台。
容器編排平台看似只是在管理容器,但其實它解決的是分散式系統中最困難的問題:如何在動態變化的環境中維持系統的穩定性?如何在資源有限的情況下達到最佳的利用率?如何在故障發生時快速恢復服務?
今天我們將深入探討容器編排平台的架構原理, 從單機 Docker 演進到 Kubernetes 的過程,並透過 Netflix 和 Reddit 的實際案例,理解企業級容器編排的設計挑戰與解決方案。
一家快速成長的社交媒體公司,目前有 200 個微服務、日均 5 億次 API 調用、每天 100+ 次部署。團隊面臨的挑戰包括:服務部署需要手動協調多個團隊、資源利用率低導致成本高昂、故障恢復時間長影響用戶體驗。
容器編排平台成為解決這些問題的關鍵基礎設施,它不僅要管理容器的生命週期,更要成為支撐業務快速發展的技術引擎。
功能性需求
非功能性需求
技術挑戰 1:資源調度複雜性
在異構環境中,如何將容器分配到最適合的節點?需要考慮 CPU、記憶體、儲存、網路等多維度資源,還要滿足親和性、反親和性等業務規則。
技術挑戰 2:服務發現與網路
容器的 IP 是動態的,服務如何找到彼此?如何實現跨節點的容器通訊?如何處理東西向和南北向流量?
技術挑戰 3:狀態一致性與容錯
分散式環境中,如何保證系統狀態的一致性?節點故障時如何快速恢復?如何避免腦裂問題?
| 維度 | 聲明式架構 | 命令式架構 | 混合架構 |
|---|---|---|---|
| 核心特點 | 描述期望狀態,系統自動調和 | 明確指定每個操作步驟 | 結合兩種方式的優點 |
| 優勢 | 易於理解、自動修復、版本控制友好 | 執行路徑清晰、調試方便 | 靈活性高、適應不同場景 |
| 劣勢 | 調試困難、收斂時間不確定 | 複雜度高、錯誤恢復困難 | 架構複雜、學習成本高 |
| 適用場景 | 大規模生產環境 | 簡單部署場景 | 企業混合環境 |
| 複雜度 | 中等 | 低 | 高 |
| 成本 | 中等 | 低 | 高 |
架構重點:
系統架構圖:
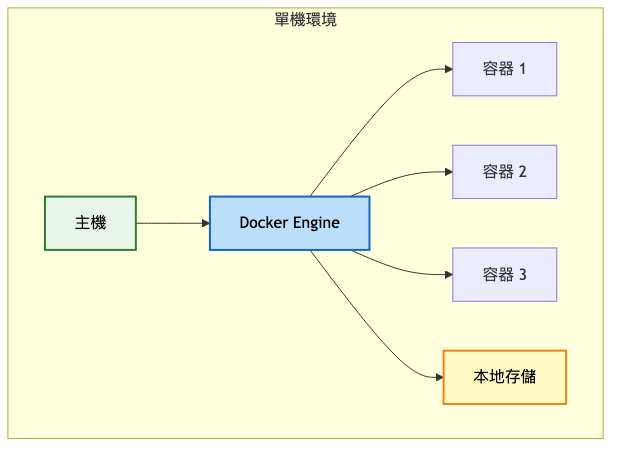
關鍵限制:
架構重點:
系統架構圖:
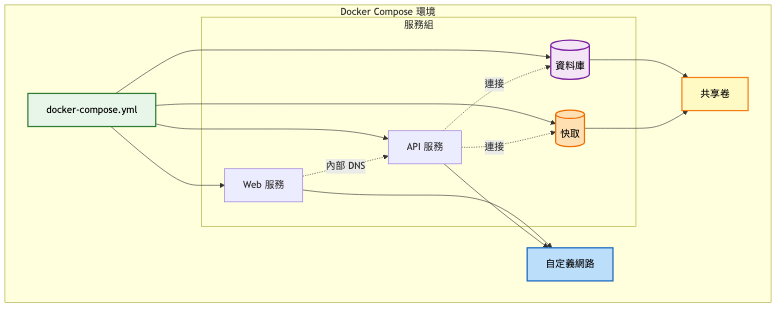
關鍵改進:
多容器協調
網路簡化
架構重點:
系統架構圖:
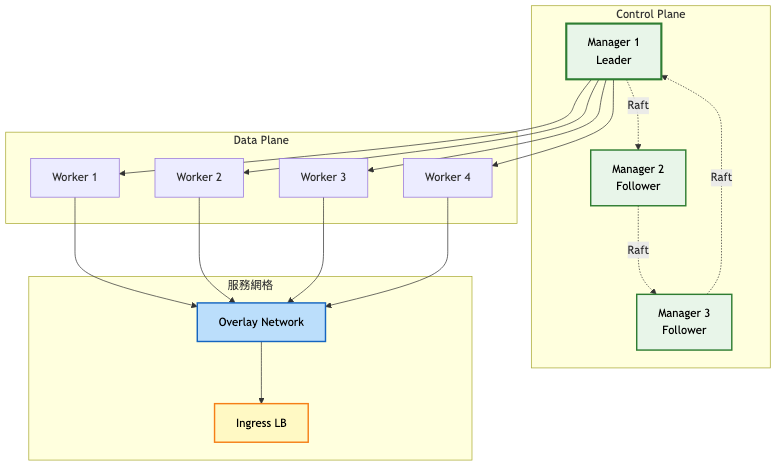
關鍵架構變更:
分散式架構
服務編排
架構重點:
總覽架構圖:
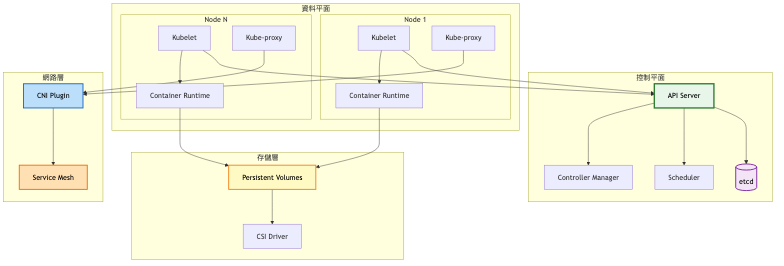
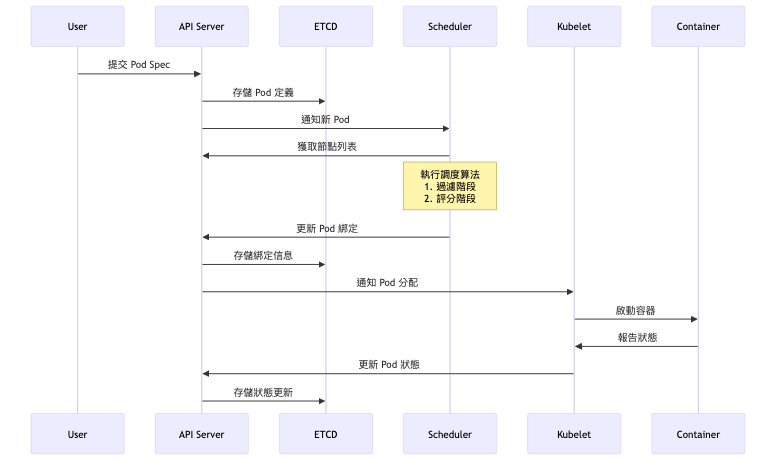
資源調度詳細流程:
階段演進總覽表:
| 架構特性 | 單機 Docker | Docker Compose | Docker Swarm | Kubernetes |
|---|---|---|---|---|
| 架構模式 | 單機執行 | 單機編排 | 叢集管理 | 企業級編排 |
| 節點規模 | 1 | 1 | 5-50 | 100+ |
| 服務發現 | 無 | 本地 DNS | 內建服務發現 | DNS + Service |
| 網路模式 | Bridge | 自定義網路 | Overlay | CNI 插件化 |
| 存儲管理 | 本地卷 | 命名卷 | 分散式卷 | CSI 標準化 |
| 故障恢復 | 手動 | 手動 | 自動重啟 | 全自動修復 |
| 擴展能力 | 垂直擴展 | 垂直擴展 | 水平擴展 | 彈性擴展 |
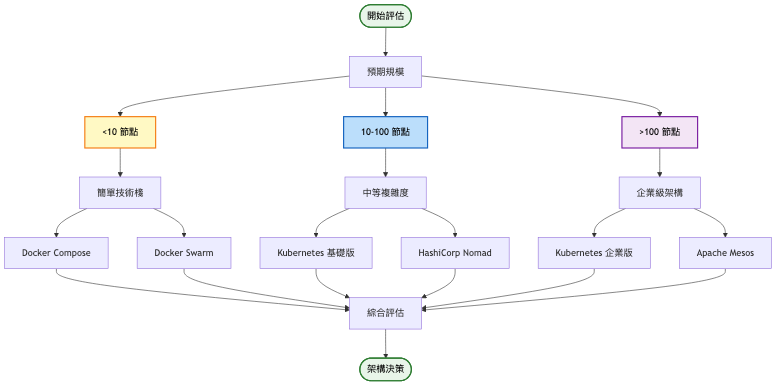
演進決策指南表:
| 觸發條件 | 採取行動 | 預期效果 |
|---|---|---|
| 容器數量 > 10 | 從 Docker 遷移到 Docker Compose | 簡化多容器管理,提升開發效率 30% |
| 需要跨主機部署 | 從 Compose 升級到 Swarm/K8s | 實現高可用,故障恢復時間 < 1分鐘 |
| 服務數量 > 50 | 採用 Kubernetes | 自動化運維,減少 70% 手動操作 |
| 需要進階功能 | 整合 Service Mesh、GitOps | 實現金絲雀發布、A/B 測試 |
編排平台比較:
| 技術選項 | 優勢 | 劣勢 | 適用場景 |
|---|---|---|---|
| Docker Swarm | 簡單易用、與 Docker 原生整合、學習曲線平緩 | 功能有限、生態系統較小、擴展性受限 | 中小型團隊、簡單應用、快速原型 |
| Kubernetes | 功能完整、生態豐富、高度可擴展、業界標準 | 複雜度高、資源開銷大、運維成本高 | 大型企業、複雜微服務、需要彈性擴展 |
| Nomad | 多類型工作負載、輕量級、易於運維 | 容器功能較少、社群較小 | 混合工作負載、HashiCorp 生態用戶 |
| Mesos | 兩級調度、大規模驗證、資源利用率高 | 學習成本高、容器支援非主流 | 大數據處理、批次運算 |
網路方案選擇:
| CNI 插件 | 效能 | 功能完整性 | 運維複雜度 | 使用建議 |
|---|---|---|---|---|
| Flannel | 中等 | 基礎 | 低 | 開發測試環境、小規模部署 |
| Calico | 高 | 完整 | 中 | 生產環境、需要網路策略 |
| Cilium | 極高 | 非常完整 | 高 | 高效能要求、需要 L7 策略 |
| Weave | 中等 | 完整 | 低 | 簡單部署、多雲環境 |
容器編排平台的選擇不是一次性決策,而是隨著業務發展不斷演進的過程:
初期快速驗證階段
使用 Docker Compose 進行本地開發和測試,快速驗證架構可行性。這個階段的重點是業務邏輯驗證,而非基礎設施優化。
成長期平穩過渡階段
當需要生產環境部署時,可以先採用 Docker Swarm 作為過渡方案。它提供了基本的叢集管理能力,同時保持了 Docker 的使用習慣,降低了團隊的學習成本。
成熟期全面升級階段
當業務規模達到一定程度,微服務數量超過 50 個,日部署次數超過 10 次時,遷移到 Kubernetes 成為必然選擇。這時需要投入資源建立完整的 DevOps 流程和監控體系。
過早採用複雜架構
忽視網路設計
資源配置不當
案例一:Netflix 的 Titus 平台架構演進
Netflix Tech Blog - Titus Platform
初期(2016-2017)
成長期(2018-2019)
成熟期(2020-2023)
案例二:Reddit 的 Kubernetes 遷移之旅
Reddit Engineering Blog - K8s Migration
初期(2017-2018)
轉型期(2019-2020)
現狀(2021-2024)
Kubernetes 的核心設計模式,確保實際狀態與期望狀態一致:
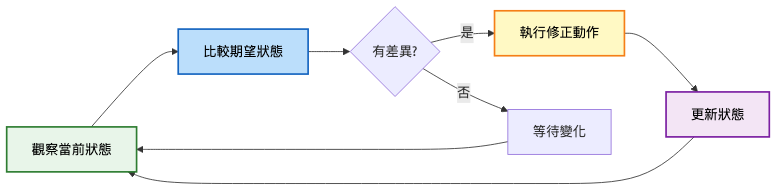
實施方式:
最大化資源利用率的調度策略:

資源管理策略:
高可用部署模式:
技術指標:
業務指標:
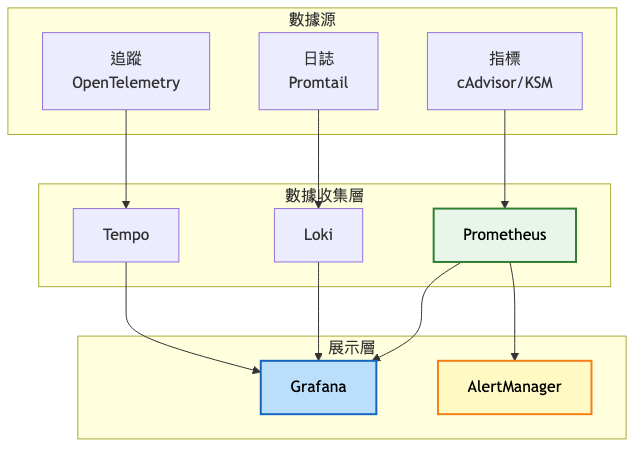
自動化升級策略
故障排查流程
成本優化措施
針對今日探討的容器編排平台系統設計,建議可從以下關鍵字或概念深化研究與實踐,以擴展技術視野與解決方案能力:
Service Mesh 架構:透過進一步學習 Istio、Linkerd 等服務網格技術,能加強對微服務通訊、流量管理的理解與應用。
GitOps 實踐:這部分涉及的 ArgoCD、Flux 等工具,適合深入掌握以提升部署自動化和配置管理能力。
eBPF 技術:探索 Linux 內核可編程性及其在容器網路、監控、安全的應用,幫助設計更高效能的系統架構。
Operator 模式:關注 Kubernetes Operator 開發,學習如何將運維知識編碼化,實現應用的自動化管理。
混沌工程:研究 Chaos Monkey、Litmus 等混沌工程工具,提升系統韌性和故障恢復能力。
可根據自身興趣,針對上述關鍵字搜尋最新技術文章、專業書籍或參加線上課程,逐步累積專業知識和實踐經驗。
明天我們將探討「資料倉儲系統」的設計。從傳統的 ETL 到現代的 ELT 架構,從批次處理到即時分析,我們將深入理解如何構建支援大數據分析的資料基礎設施。這個主題將帶領我們進入數據工程的世界,理解如何處理 PB 級資料的存儲、處理與查詢挑戰。


 iThome鐵人賽
iThome鐵人賽