當你的電商平台每天產生數十億筆交易記錄、使用者行為日誌和庫存變化時,傳統的報表系統已經無法應對。業務團隊需要在幾秒內獲得即時的銷售趨勢分析,行銷部門希望快速理解使用者偏好變化,營運團隊需要預測性的庫存管理洞察。這不只是一個技術挑戰,更是企業競爭力的核心。
現代資料倉儲系統已經從傳統的批次處理報表工具,演進為支援即時分析、機器學習預測和業務智能的複合平台。 雲端原生架構、資料湖屋概念、流批一體化處理,這些不再是未來趨勢,而是今天企業數位轉型的必要元件。
今天我們將深入探討如何設計一個能夠處理 PB 級數據、支援毫秒級查詢回應、同時具備成本效益的現代資料倉儲系統。 從架構選型到技術實施,從成本優化到效能調優,我們會一步步建構出適合不同企業規模的完整解決方案。
以一家快速成長的跨國電商平台為例,每日處理來自全球 15 個國家的交易數據。系統需要同時服務於多個利害關係人:財務團隊需要即時的營收分析、行銷團隊要求使用者行為洞察、營運團隊依賴庫存預測、客服團隊需要客戶互動歷史,而高階主管希望獲得整合的企業儀表板。
這個平台每天新增 100GB 的結構化交易數據、500GB 的半結構化使用者行為日誌,以及來自第三方 API 的外部數據源。數據需要支援從即時警報(30 秒內)到複雜分析報告(數小時的計算)等不同時效性需求。
系統還需要滿足法規遵循要求,包括 GDPR 的資料隱私保護、SOX 法案的財務數據審計追蹤,以及各國稅務機關的交易記錄保存規定。
功能性需求
非功能性需求
技術挑戰 1:雲端原生 vs 混合部署的架構選擇
純雲端部署提供最佳的彈性和成本效益,但可能面臨數據主權限制和網路延遲問題。混合架構能滿足法規要求並利用既有投資,但增加了複雜度和維護成本。關鍵考量包括數據傳輸成本、延遲敏感性、法規限制,以及團隊的雲端技術成熟度。
技術挑戰 2:批次處理 vs 流處理的架構統一
傳統資料倉儲以批次處理為主,但現代業務需求要求即時洞察。Lambda 架構雖能同時支援,但維護兩套代碼庫成本高昂。現代流批一體化技術如 Apache Flink 和 Delta Lake 提供了統一處理模式,但需要考慮技術成熟度和團隊技能轉換成本。
技術挑戰 3:資料湖 vs 資料倉儲 vs 湖倉一體的選擇
資料湖提供靈活性和成本效益,但查詢效能和資料治理是挑戰。傳統資料倉儲效能優異但靈活性有限。資料湖屋架構結合兩者優勢,但技術相對新穎,需要評估風險和實施複雜度。
| 維度 | 純雲端倉儲 | 湖倉一體 | 混合架構 |
|---|---|---|---|
| 核心特點 | 完全託管、Serverless | 統一存儲、開放格式 | 雲地整合、漸進遷移 |
| 優勢 | 快速部署、自動擴縮、低運維 | 成本效益、格式靈活、避免鎖定 | 法規遵循、既有投資保護 |
| 劣勢 | 供應商鎖定、成本可預測性 | 技術複雜度、治理挑戰 | 運維複雜、延遲問題 |
| 適用場景 | 快速成長、雲端優先 | 大數據量、多樣化工作負載 | 嚴格法規、既有投資 |
| 複雜度 | 低 | 中高 | 高 |
| 總擁有成本 | 中 | 低 | 高 |
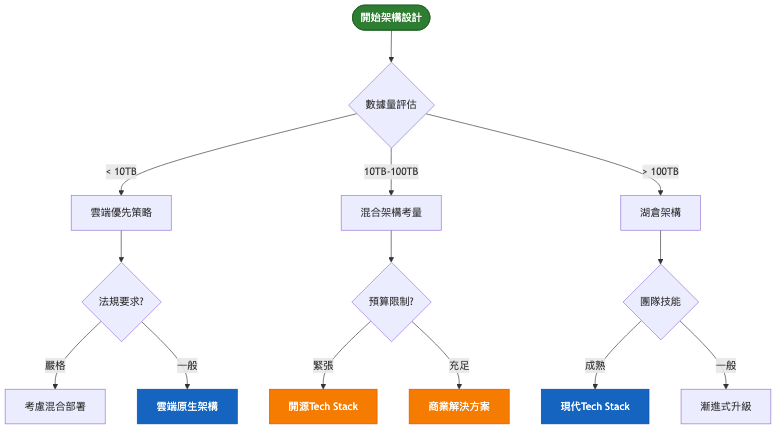
我們將展示資料倉儲系統如何從基礎 MVP 逐步演進到企業級規模化架構,每個階段都有明確的技術特徵和適用場景。
架構重點:
系統架構圖:
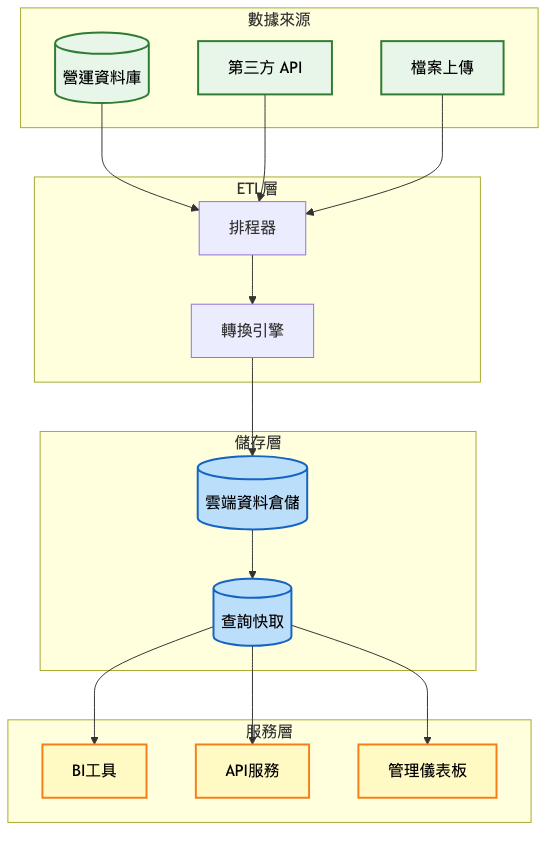
架構重點:
關鍵架構變更:
數據攝取現代化
儲存架構分層
系統架構圖:
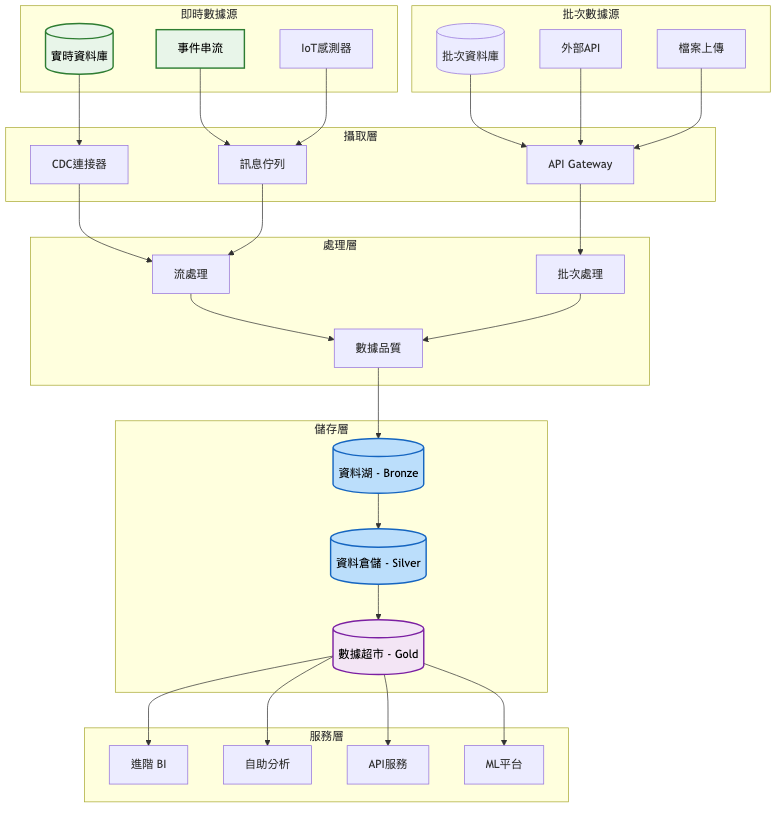
架構重點:
關鍵架構變更:
雲原生微服務架構
多雲數據平台
企業級治理
演進決策指南表:
| 觸發條件 | 採取行動 | 預期效果 |
|---|---|---|
| 查詢回應時間 > 30 秒 | 引入分散式查詢引擎 | 10x 查詢效能提升 |
| 數據攝取延遲 > 5 分鐘 | 實施即時流處理 | 近即時數據可用性 |
| 儲存成本佔總成本 > 60% | 實施分層儲存策略 | 40-50% 儲存成本降低 |
| 數據品質問題 > 5%錯誤率 | 部署自動化品質監控 | 95% 數據品質保證 |
| 使用者等待報表 > 1 小時 | 實施自助式分析平台 | 80% 報表需求自助化 |
基於最新的技術發展和實際效能測試,我們提供詳細的技術選型分析。
| 技術選項 | 優勢 | 劣勢 | 適用場景 |
|---|---|---|---|
| Snowflake | 真正的多雲部署、卓越查詢效能(8.21秒 TPC-DS)、零拷貝數據共享 | 成本可預測性、特定工作負載的定價 | 高並發分析、多雲策略、複雜查詢需求 |
| BigQuery | 完全 Serverless、內建 ML 能力、標準 SQL、無限併發 | Google 生態鎖定、複雜定價模型 | 變動工作負載、ML 整合、免運維需求 |
| Redshift Serverless | AWS 深度整合、AI 驅動擴縮、成本優化 | 效能相對較低、AWS 生態依賴 | AWS 環境、成本敏感、傳統遷移 |
| Databricks | 統一分析平台、Delta Lake 湖倉架構、協作環境 | 學習曲線、複雜定價 | 數據科學、湖倉架構、團隊協作 |
現代資料湖屋架構的成功關鍵在於選擇合適的開放表格格式。
Apache Iceberg 在企業級部署中表現優異,特別是其隱藏分區和分區演化功能,讓數據工程師能夠透明地優化查詢效能。Netflix 在生產環境中每日處理 500 億事件,驗證了 Iceberg 在 PB 級數據上的穩定性。其引擎無關性意味著同一份數據可以被 Spark、Flink、Presto 等不同引擎查詢。
Delta Lake 憑藉與 Spark 生態的深度整合和最活躍的開源社群,在傳統 ETL 工作負載中佔據優勢。其 Z-ordering 優化和 ACID 事務支援,使得批處理場景下的查詢效能優異。Databricks 的商業支援也為企業提供了額外保障。
Apache Hudi 的流媒體優先設計和先進的增量處理能力,特別適合需要頻繁更新和 CDC 重度使用的場景。Uber 透過 Hudi 將每日數據處理量從 TB 級降低到 GB 級,顯著降低了基礎設施成本。
Apache Flink 2.0 在 2025 年帶來了革命性提升。新的分離式狀態管理實現了 75-120% 的吞吐量提升,流批統一架構透過物化表格提供聲明式的實時和歷史數據管理。自適應批執行在 TPC-DS 基準測試中展現 8-16% 的效能提升。
Apache Spark 仍然是批處理工作負載的首選,其自適應查詢執行(AQE)和增強的 Delta Lake 連接性使其在湖倉架構中表現優異。Structured Streaming 的改進為近實時處理提供了穩定可靠的選擇。
雲端託管服務如 AWS Kinesis Analytics、Google Dataflow、Azure Stream Analytics 為不同雲端環境提供了免運維的流處理選項,特別適合中小型企業和雲端優先策略。
過早優化的陷阱
數據孤島問題
忽視數據治理
成本控制不當
案例名稱:Netflix 的統一數據架構(UDA)轉型
參考文章
初期(2015-2018)
成長期(2018-2022)
近期狀態(2022-現在)
案例名稱:Uber 的 DataMesh 雲遷移策略
參考文章
內部部署時期(2015-2020)
雲遷移期(2020-2023)
技術指標:
業務指標:
自動化監控與告警
預測性維護
持續優化流程
現代資料倉儲系統的成功關鍵在於平衡技術先進性、成本效益和組織能力。雲端原生架構提供了前所未有的彈性和效能,但需要配合適當的治理框架和成本控制機制。資料湖屋架構代表了未來趨勢,能夠統一批次和流處理工作負載,但實施需要謹慎的技術選型和分階段部署策略。
成功的現代資料倉儲系統不僅僅是技術平台,更是企業數據文化和決策流程的重要組成部分。從 Netflix 的大規模工程化實踐到 Uber 的成本優化策略,這些業界案例都強調了漸進式演進、開源技術投資和自動化優先的重要性。
基於深入的技術分析和實際案例研究,我們可以歸納出五個核心設計原則:雲端優先但避免鎖定、自動化一切可自動化的流程、數據治理從第一天開始實施、成本意識貫穿整個架構決策、以及採用開放標準確保互操作性。這些原則將指導我們在快速變化的技術環境中做出正確的架構選擇。
針對今日探討的「資料倉儲系統」設計,建議可從以下關鍵字或概念深化研究與實踐,以擴展技術視野與解決方案能力:
雲端原生數據架構:透過進一步學習 Serverless 計算、容器化部署和微服務架構,能加強對現代數據平台設計的理解與應用。
資料湖屋架構實踐:這部分涉及的 Apache Iceberg、Delta Lake 和數據治理技術,適合深入掌握以提升數據平台的靈活性和效能。
流批一體化處理:探索 Apache Flink、實時分析引擎及其最佳實踐,幫助設計更具即時性和可維護性的數據管道。
DataOps 和 MLOps 整合:關注數據營運自動化和機器學習工作流程,保持技術與時俱進,尋找數據驅動決策的創新解決方案。
可根據自身興趣,針對上述關鍵字搜尋最新技術文章、專業書籍或參加線上課程,逐步累積專業知識和實踐經驗。
明天我們將探討「身份認證授權系統」的設計。從單點登入(SSO)到細粒度權限控制,從 OAuth 2.0 到零信任架構,我們將深入了解如何建構安全可靠的企業級身份管理平台。這個系統將是我們三十天旅程中安全性設計的重要里程碑,為最後兩天的整合型系統設計做好準備。


 iThome鐵人賽
iThome鐵人賽