昨天一樣分步驟實作完了三角函數的位置編碼,也就是 transformer 當初提出來所用的方法,
參考文章&圖片來源:
https://www.cnblogs.com/rossiXYZ/p/18785615
今天來點比較輕鬆的,講講如何簡單的資源估計。
如果有學過 c 或 c++ 的朋友一定不陌生,但如果一開始學 python 就比較沒那麼熟悉。
在 c 或 c++ 很常會有 int8_t, int16_t, uint8_t 之類的,那在 python 模型當中常見如圖,那當然還有 microsoft 1.58bit
觀念可參考這篇
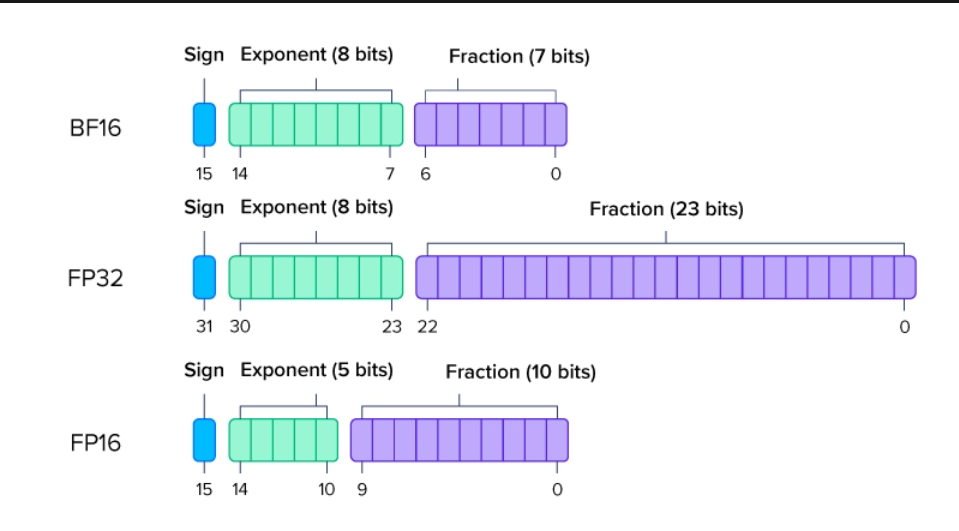
圖片來源: https://www.exxactcorp.com/blog/hpc/what-is-fp64-fp32-fp16
其中 FP16,是拿16個位元來儲存一個數值,而8個位元 = 一個位元組(Byte),所以 FP16 需要 2 Byte。
以下記憶體都是指 GPU memory
採用什麼樣的數據類型就需要多少的記憶體,其中"B"這個單位在 LLM 很常看到,他代表 1000M,已就是十億,那對應顯卡就是G (1024M),所以簡單可將 1B 視為 1G
| 數據類型 | 每 1B 參數量需要多少記憶體 |
|---|---|
| fp32 | 4G |
| fp16/bf16 | 2G |
| int8 | 1G |
| int4 | 0.5G |
那記憶體需要在 training 跟 inference 又不同
Training:模型參數 + activation + 梯度 + 優化器狀態
Inference:模型參數 + activation + KV cache (自回歸模型)
| 類別 | Training | Inference |
|---|---|---|
| 模型本身 | Conv, Linear, Embedding, BatchNorm | Conv, Linear, Embedding, BatchNorm |
| 計算暫存 (Activation Memory) | 需要保留所有 layer 的中間輸出 (供反向傳播用) - 大小 ≈ batch size × seq_len × hidden_dim | 只需保留當前步驟的中間輸出 - 大小較小 (但 seq_len 很大時,仍會佔用不少) |
| 梯度需求 | - 每個參數對應一份梯度 (≈ 參數量的 1 倍) - 優化器狀態 (如 Adam 需 2 倍參數大小) - Dropout mask 需暫存 | - 不需要梯度 - 不需要優化器狀態 - 不需要 Dropout mask |
更詳細的看: 模型參數、前向計算過程中產生的中間激活、後向傳播計算所得到的梯度、優化器狀態。

所以在沒有任何優化,採用上面的數據類型的話,假設參數量為Φ 的大模型,模型參數、梯度和優化器狀態佔用的顯存大小為20Φ bytes 。
所以在 LLM fine-tune 或者是 AED based 的 ASR 模型,如果資料量不是很多,那麼會採用類似 Lora 的技術,會凍結我們原本的模型,額外增加簡單的 layer ,此時就可以大量減少所需的 memory,可以參考 unsloth。
或者採用 8-bit optimizers,只需要原先標準 32-bit optimizers 的 25% 記憶體就行。 (這裡分享我自己訓練 nemo asr 模型的經驗,人家大公司通常都是拿 80G 記憶體在做訓練,但我只有 24G,所以我的目標是盡量節省記憶體,才能提高 batch size,所以我採用 adamw8bit,實際訓練效果差不多,也沒出現 loss 曲線突然 nan 的問題)
以下皆考慮 bias
Linear:
我們從最簡單的 linear 開始,當中包含 weight 以及 bias。
weight: 是一個矩陣,其參數量 = 輸入維度 * 輸出維度
bias: 是一個向量偏移,其參數量 = 輸出維度
所以一個 linear,輸入輸出維度皆為 d 的參數量(含 bias) → d^2 + d
MHA:
有 Q, K, V, O 四個 linear,輸入輸出皆為 d ,所以是 4d ^ 2 + 4d
FFN:
升維: d(輸入) → 4d (輸出) → d * 4d + 4d
降維: 4d (輸入) → d (輸出) → 4d * d + d
總和: 8d^2 + 5d
LayerNorm:
有縮放的參數和平移參數,維度皆為 d,所以總和: 2d
另外 MHA 和 FFN 各有一個 LayerNorm,所以總和: 4d
所以我們單考慮一層 transofrmer,需要 12d^2 + 13d,看你模型有幾層就再乘以層數,以下是更詳細的部分。
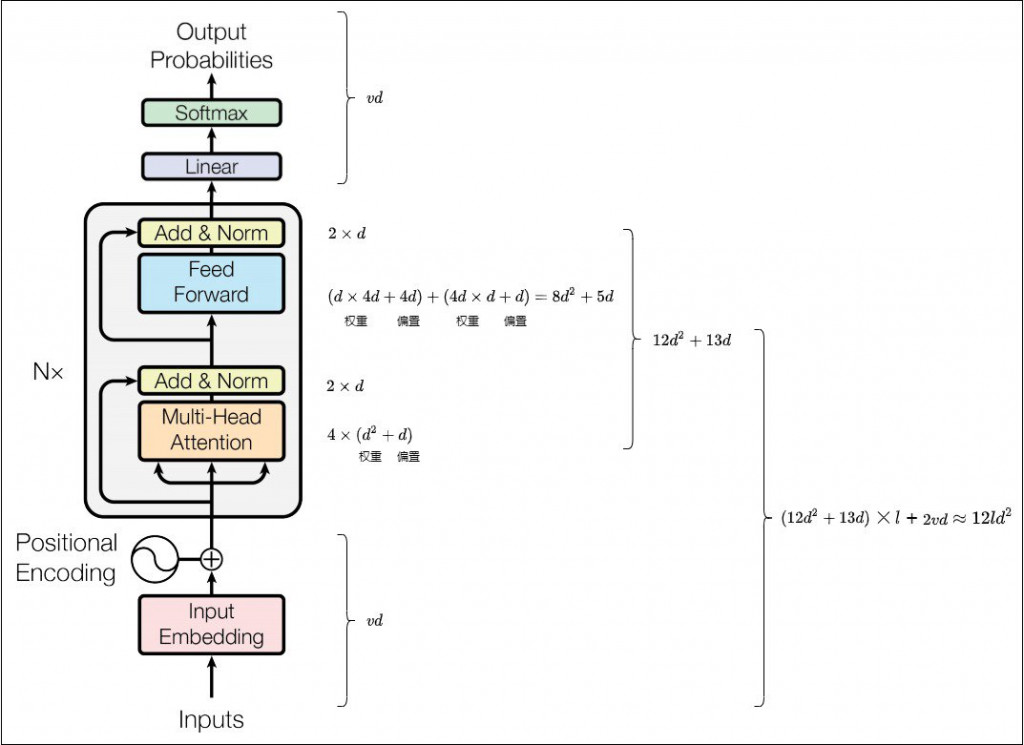
實際在訓練時我們不用自己估算,torch 可以直接得到,或者 lightning 在訓練開始前會直接顯示出參數量,不過至少有個概念。
在 1.3 當中有提到 Activation Memory,指的是前向 (forward) 傳播計算得到的,並在反向 (backward) 傳播中需要用到的所有 tensor。 比如說一個 query = self.linear_q(x),當中的的 query 就是中間激活值。
與輸入數據大小關係
有關: 中間激活值與 batch size 和 seq_len 成正比相關,所以如果訓練時有發生 OOM (Out Of Memory),通常會先調小 batch size,看會不會再遇到問題,其實就是在減少中間激活值。
無關: 模型參數與數據類型有關,跟數據大小無關。 優化器與選擇的優化器有關,與模型參數有關,但與數據大小無關。
今天就先到這裡囉~


 iThome鐵人賽
iThome鐵人賽