今天首先會先講解資料夾放置的位置,再來把Phi-4的使用程式碼放上來。
首先是資料夾位置放置方式:
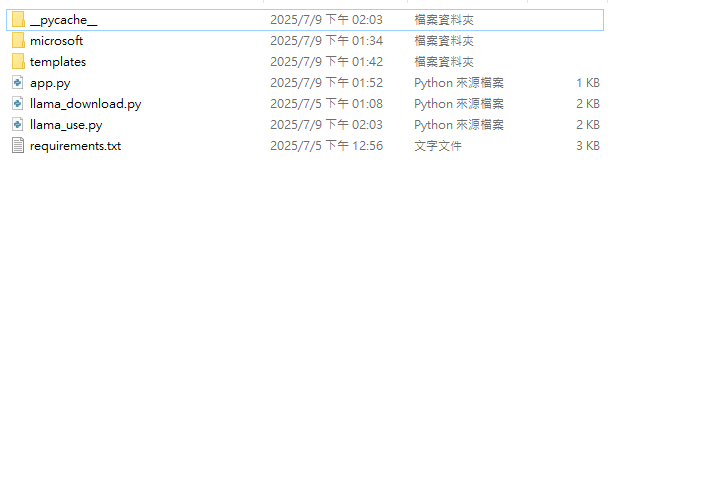
這個專案的結構,主要分為四個部分,分別負責不同的功能模組。首先,microsoft 資料夾中儲存的是 phi-4 模型的檔案,此模型為一個由微軟推出的語言模型,用於處理自然語言理解與生成的任務。這些模型檔案可以是經過微調的參數模型,供後續問答或對話系統調用。接著,templates 資料夾是專門用來放置網頁模板的地方,通常是 HTML 檔案,配合 Jinja2 模板引擎使用,來實現前端畫面的動態渲染,讓使用者能透過瀏覽器與系統互動。
而 app.py 是整個專案的主程式,用來啟動網頁伺服器,透過 Flask 或其他 Python 網頁框架處理路由請求、載入模板並回傳結果給用戶端。這支程式同時也是整合前後端的樞紐,連接使用者介面與後端語言模型。最後,llama_use.py 是與 phi-4 模型進行互動的主要程式,負責載入模型、處理使用者輸入、並回傳模型生成的回答,是核心的自然語言處理模組,實現模型問答與應用邏輯的功能。整體來說,此專案架構模組化明確,便於開發與維護,也具備擴充性,適合用於自然語言處理相關應用的開發。
再來是app.py程式碼的部分:
from flask import Flask, render_template, request
import llama_use
app = Flask(__name__)
@app.route('/page1', methods=['GET', 'POST'])
def submit_form():
if request.method == 'POST':
Q = request.form.get('Q')
ans = llama_use.chat(Q)
print(ans)
return ans
return render_template('page1.html') # Render an HTML form for GET requests
if __name__ == '__main__':
app.run(debug=True)
接下來是llama_use.py的程式碼部分:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
model_path = "microsoft/Phi-4-mini-reasoning"
model2 = AutoModelForCausalLM.from_pretrained(
model_path,
device_map="cuda",
torch_dtype="auto",
trust_remote_code=True,
)
tokenizer2 = AutoTokenizer.from_pretrained(model_path)
def chat(prompt):
inputs = tokenizer2.apply_chat_template([{
"role": "user",
"content": prompt
}],add_generation_prompt=True,
return_dict=True,
return_tensors="pt",
)
outputs = model2.generate(
**inputs.to(model2.device),
max_new_tokens=32768,
temperature=0.8,
top_p=0.95,
do_sample=True,
)
outputs = tokenizer2.batch_decode(outputs[:, inputs["input_ids"].shape[-1]:])
return outputs[0].split("</think>")[-1].split("<|end|>")[0].split("</response>")[-1].split("{Phi}")[0]
# while(True):
# inp = "hi"
# inp = input("enter text:")
# if(inp == "exit()"):
# break
# print(chat(inp))
明天的文章將會把程式碼進行細部的講解與分析。


 iThome鐵人賽
iThome鐵人賽