
前幾天我們探討了 Copilot Studio Full Experience 的核心功能,並延伸出多種實際應用情境與潛在解決方案,然後今天會將焦點放在更深一層的主題為建立角色的「大腦」。
這不僅是為了打造更廣、更細緻的解決方案思維,也是為了培養一種面對高速變化世界所必備的關鍵思維習慣。
如果說過去幾年是大型語言模型 (LLM) 技術的萌芽期,那麼 2025 年無疑標誌著我們進入了一個 LLM 技術多元化、供應商充分競爭的成熟階段。
在這個時期市場上出現了眾多優秀的選擇,例如 OpenAI 的 GPT 系列持續創新,Anthropic 的 Claude 家族提供了強大的替代方案,Google 的 Gemini 整合了龐大的生態系,Grok 急起直追像是火箭般發展的新生態系,同時還有眾多開源模型在特定領域表現出色。
就像是這張圖一樣,每隔幾個月新的大型語言模型一推出所以跟 AI 相關的服務很快就可以使用這些模型
對企業而言意味著更多的選擇和更大的彈性,在此背景下 Microsoft Copilot Studio 的定位也日益清晰,它不僅只是一個開發工具,更是一個能夠整合並調度多種 AI 服務的核心平台,接著來探討 Copilot Studio 在這個多模型共存的未來中所扮演的角色與潛在應用。
要有效利用當前的 AI 能力,首先需要了解關鍵模型的具體進展。
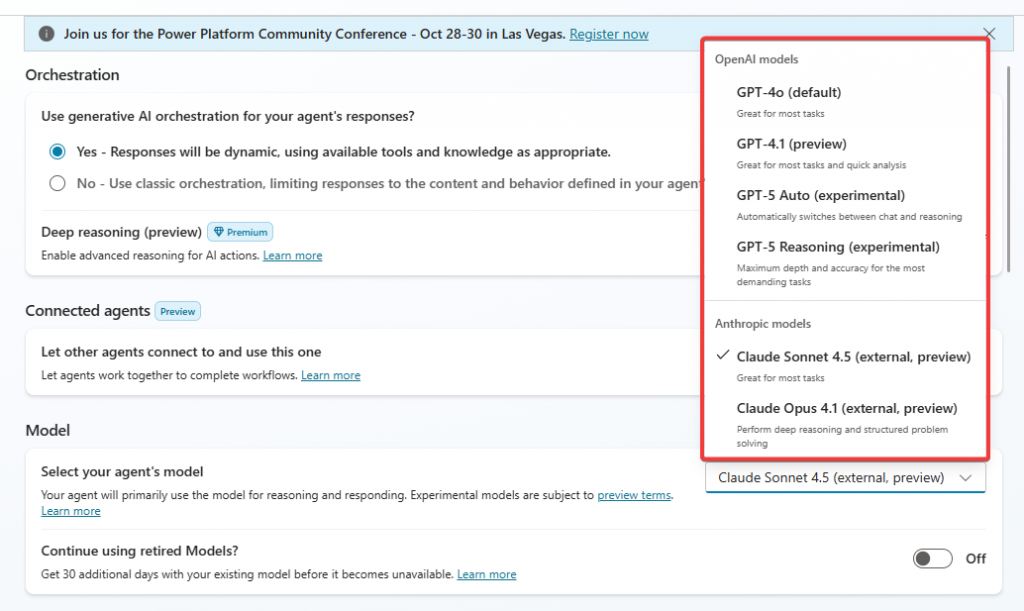
在快速迭代的人工智慧領域,Microsoft Copilot Studio 始終走在技術整合的前沿,其核心大型語言模型(LLM)的演進與擴展,直接定義了平台的應用深度與廣度。
從最初以 GPT-4o 為基礎,到8月的時候導入 GPT-5 的創新架構,接著很快的在9月宣布整合 Anthropic Claude 系列模型,Copilot Studio 已從單一模型依賴轉變為一個靈活、高效的雙供應商(Dual-Vendor)生態系統,為企業提供前所未有的選擇性與任務適應性。
Copilot Studio 的發展根基於 OpenAI GPT 系列模型的持續突破,每一代模型的更新都為平台帶來了質的飛躍。
Copilot Studio 曾經的預設模型,GPT-4o 以其原生的多模態處理能力奠定了平台的核心功能。
然而其在處理大規模資料時受限的上下文視窗,使其功能逐漸被後續更強大的版本所超越,成為技術演進光譜中的一個重要起點。
此模型的發布標誌著一次全面的效能升級。它在三個關鍵領域實現了顯著提升:
編碼能力: 在 SWE-bench 測試中準確率提升了 21.4%,大幅增強了程式碼生成與除錯的可靠性。
指令遵循精確度: 更精準理解並執行複雜指令,減少了誤解與偏差。
長文本處理: 上下文視窗擴展至 100 萬 tokens,使其能夠處理極長的文檔與複雜對話,為深度分析任務鋪平了道路。結合其優越的成本效益,GPT-4.1 迅速成為執行多數高要求任務的可靠首選。
GPT-5 的推出帶來了革命性的架構突破 : 即時路由 (Real-time Router) 機制。此機制能根據任務的複雜度,動態選擇最合適的處理模式,實現了速度、成本與準確性的最佳平衡。
2025年9月,Microsoft 宣布將 Anthropic Claude 模型整合至 Copilot Studio,此舉標誌著平台從單一供應商依賴走向雙供應商並行的戰略轉型。
這不僅為開發者提供了更多元的選擇,更透過引入具備獨特優勢的 Claude 模型,補足了特定高風險、長文本分析場景的需求。
Copilot Studio 的演進路徑清晰地展示了一個從「單一強大模型」邁向「多元化、專業化模型組合」的戰略思維。透過 GPT-5 的智慧路由與 Anthropic Claude 系列的專業分工,Microsoft 成功地為企業打造了一個高度靈活的智慧平台。
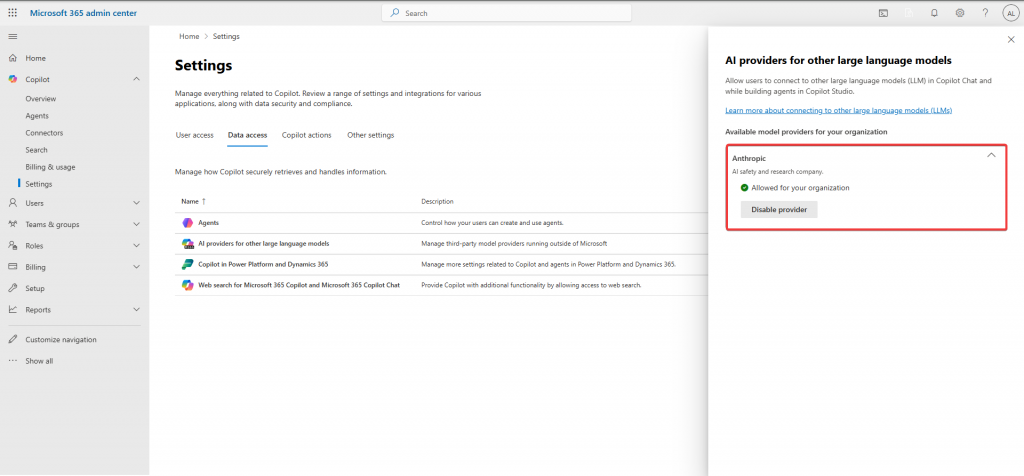
Copilot Studio 整合 Claude 模型需要經過「雙層管理啟用機制」,首先由全域管理員在 Microsoft 365 Admin Center 啟用 Anthropic 供應商,接著在 Power Platform Admin Center 進行環境層級的控制,最後在 Copilot Studio 的 Agent 設定中選擇 Claude Sonnet 4.5 或 Claude Opus 4.1 作為主要模型。
小提醒 : 當前連接到 Claude 的模型時將傳送至 Anthropic 進行處理,所以如果想要體驗 Claude 模型可以使用微軟的沙箱帳號。
在 Microsoft 365 admin center 開啟的步驟如下
接下來會以統一的指令與問題,快速比較不同模型的回答,並由 Gemini pro 2.5 擔任第三方評審,分析它們在敘述清晰度、邏輯深度與表達風格上的差異,找出各自的亮點與特點。
備註:由於這是基於單一 Prompt 的結果,因此僅是初步觀察,實際的模型表現仍需依照不同場景與多輪對話來進行更細部的比較。
同時,本次評比不會對模型的不足部分作出直接評論,而是著重於各自的優勢與表現特點。
測試的問題集
問題:
一個團隊正在設計一個能回答公司內部常見問答(FAQ)的智慧助理,並決定完全透過 Copilot Studio 來建立。
在設計過程中,他們希望這個助理不只會回覆文字,還能根據使用者的提問主題,自動選擇最合適的回答來源與回應策略。
假設團隊內的 Copilot Studio 具備以下設定:
已建立多個 Topics(主題流程),例如:「差勤規定」、「報銷流程」、「設備報修」。
已匯入兩種 Knowledge Sources:FAQ 文件與 SharePoint 頁面。
啟用了 Generative Answers(生成式回答) 功能。
請回答以下問題:
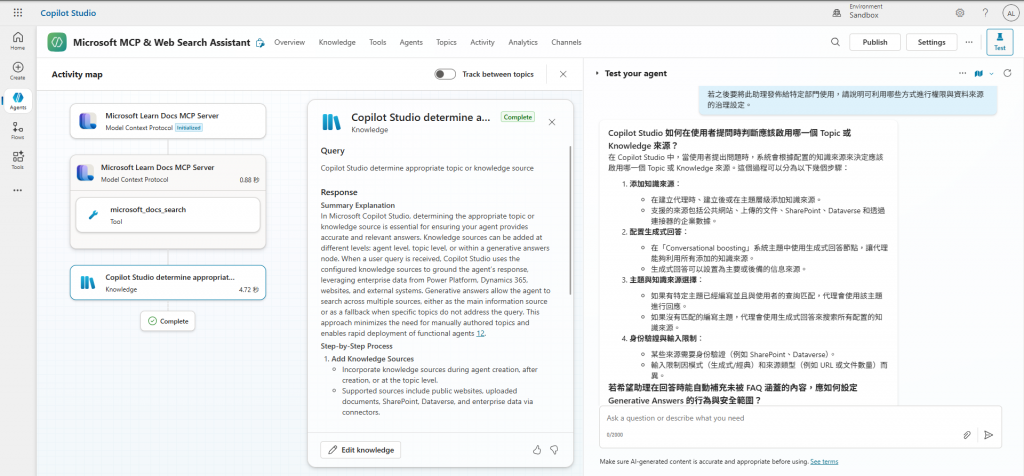
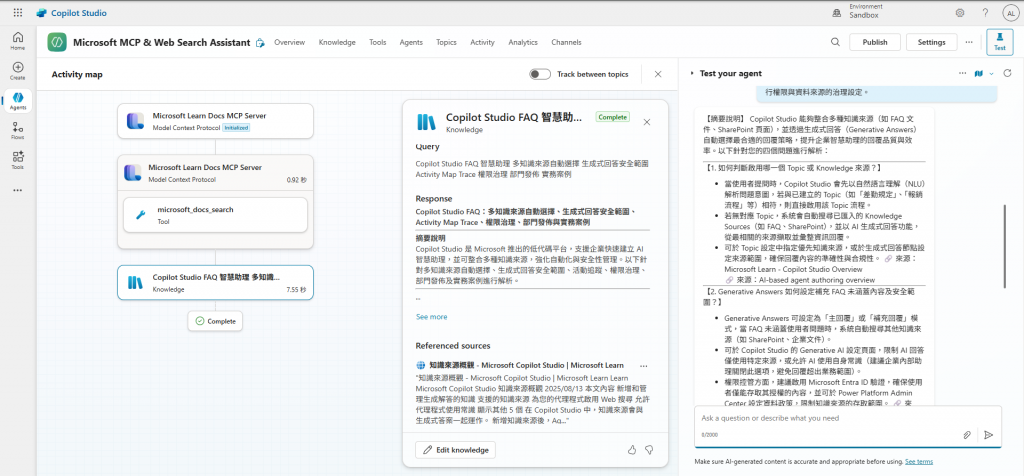
Copilot Studio 如何在使用者提問時判斷應該啟用哪一個 Topic 或 Knowledge 來源?
若希望助理在回答時能自動補充未被 FAQ 涵蓋的內容,應如何設定 Generative Answers 的行為與安全範圍?
在測試階段,應如何利用 Activity Map 或 Trace 功能 來觀察助理的決策過程?
若之後要將此助理發佈給特定部門使用,請說明可利用哪些方式進行權限與資料來源的治理設定。
相較於其他更複雜的版本,GPT-4o 的答案最為簡潔和直接。它沒有額外的框架或摘要,而是直接針對四個問題提供條列式答案,其突出之處在於:
此版本在 GPT-4o 的基礎上增加了結構性和實用性,其突出之處在於:
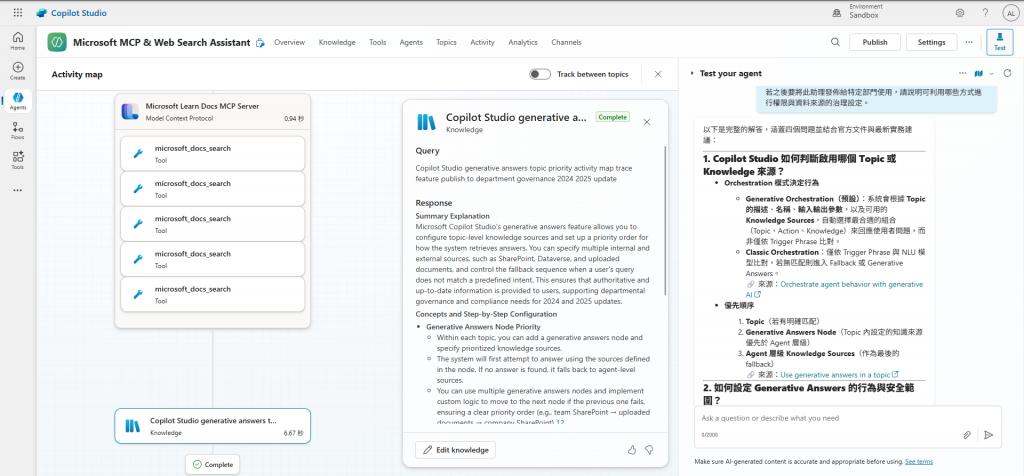
此版本展現了顯著的技術深度提升,是第一個明確引入核心概念的版本:
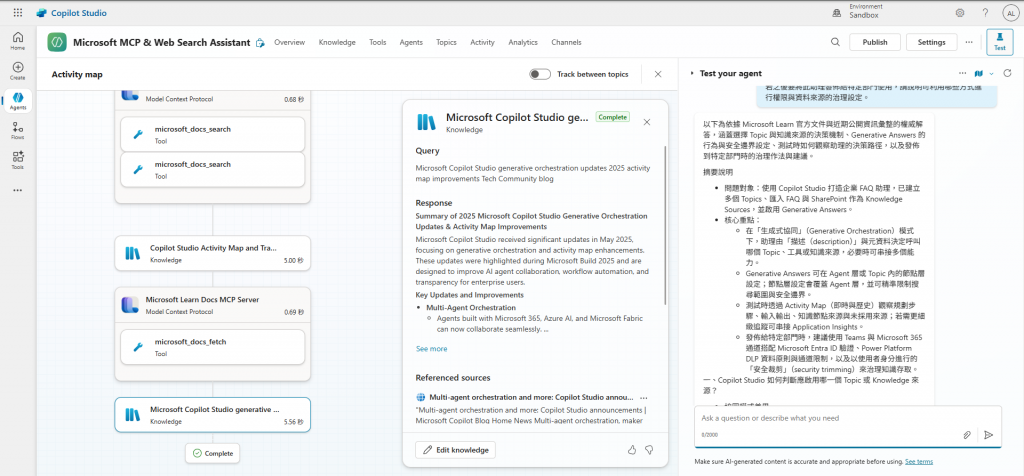
此版本堪稱一份權威的技術白皮書,其深度和嚴謹性超越了所有其他版本:
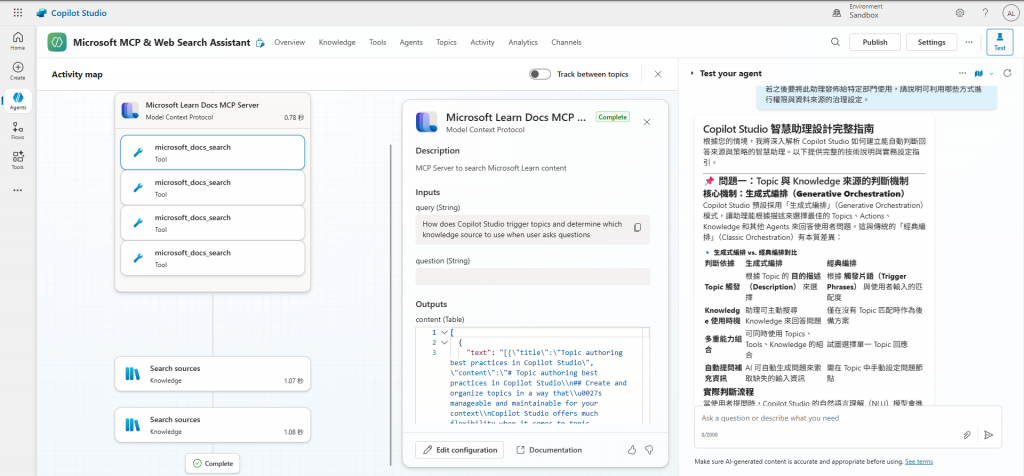
此版本在視覺化呈現和實戰部署方面最為突出,將答案組織成一份易於遵循的指南:
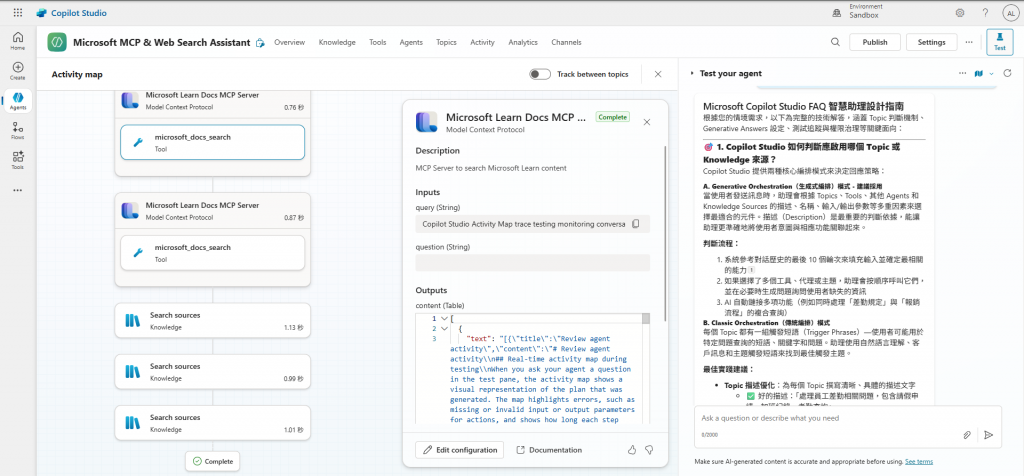
此版本是深度與實用性的強力結合,可以視為 GPT-5 Reasoning 的有力競爭者,並在某些方面更具操作性:
今天的分享我們快速了解了新模型的核心特質,並透過相同的指令、知識與提問進行了多模型比較。但最終的重點仍在於回歸到起點,就是先明確問題再對應目標,然後選擇最能發揮效益的模型,並以此為基礎快速構建出第一個 Agent 原型。
隨著大型語言模型不斷迭代,每一次模型的升級,幾乎都像是在重新認識一位「虛擬新同事」。了解它的強項、行為邏輯,並學會將這些能力與自身的建置技巧和創新思維結合,將會是未來最關鍵的 AI 核心競爭力。
