昨天我們完成了探索性資料分析(EDA),對資料的特徵與分佈有了初步理解。今天,我們要先建立第一個簡單的模型,也就是 Baseline Model。這個模型不會針對前面提到的類別不平衡去做任何調整,建立Baseline Model的目的不是要追求一口氣衝上高分,而是先提供一個基準點,方便我們在後續優化模型時,能比較改進前後的差異。
小提醒: 每次重新打開程式,都要記得把所有程式碼區塊「從頭到尾執行一次」,這樣才不會出現錯誤喔!
因為在前幾天,我們已經先用 One-Hot Encoding 對資料做了前處理,如果不重新執行這些前處理步驟,後面的訓練模型就會找不到正確的輸入格式,導致程式出錯。
在建模之前,我們要把 train.csv 再拆成兩部分-
1.訓練集 (Training Set):用來讓模型學習參數
2.驗證集 (Validation Set):不參與訓練,用來檢查模型在沒見過的資料上的表現
from sklearn.model_selection import train_test_split
# 分離特徵與標籤
X = train.drop("y", axis=1)
y = train["y"]
# 切分資料(80% 訓練,20% 驗證)
X_train, X_val, y_train, y_val = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
print("訓練集大小:", X_train.shape)
print("驗證集大小:", X_val.shape)
小提醒: 這裡使用 stratify=y,是為了確保訓練集與驗證集的正負樣本比例一致,避免驗證集出現嚴重偏差。
我們先用最基礎的邏輯迴歸(Logistic Regression) 來建立模型,看看它的分數。
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_auc_score
# 建立模型
model = LogisticRegression(max_iter=1000)
#max_iter=1000 代表模型訓練時最多跑 1000 次迭代。
#迭代的概念是指重複進行一個過程或一組指令,以逐步逼近或達成最終目標的活動。
邏輯迴歸常用於二元分類問題,例如「會不會買產品」(Yes/No)。
# 訓練模型
model.fit(X_train, y_train)
# 預測機率
y_pred_prob = model.predict_proba(X_val)[:, 1]
#[:, 1] 表示只取屬於類別 1 的機率,我們關注「會定期存款」的機率。
# 計算 ROC AUC
auc_score = roc_auc_score(y_val, y_pred_prob)
print(f"Validation ROC AUC: {auc_score:.4f}")
# 5. 把「驗證集」的機率存起來
np.save("/content/y_val_pred_prob.npy", y_pred_prob)

輸出結果會得到一個 ROC AUC 分數 = 0.9185,這就是我們的 baseline model的分數。未來的目標就是要讓這個數字更高!
除了觀察剛剛跑出來的 ROC AUC 分數,我們也可以把預測結果輸出成 submission.csv 並提交到 Kaggle,看看在官方排行榜上的表現如何,這樣更能確認我們的模型真正的分數,因為我們現在看到的 ROC AUC 分數,只是用「我們自己切出來的資料」去驗證的結果,就像自己在家寫考卷練習題目。而 Kaggle 的排行榜分數,則是用「官方保留的測試資料」計算,就像真正的期末考。兩者可能會有落差,所以我們需要上傳 submission.csv 到 Kaggle,確認模型在「真正的考試」上表現如何。
import numpy as np
import pandas as pd
# 路徑依自己的環境調整
sample = pd.read_csv("/content/playground/sample_submission.csv")
test = pd.read_csv("/content/playground/test.csv")
# 建立 X_test
X_test = test.drop(columns=["id"]) #移除 id 欄位,因為它不是特徵
# 測試資料也要做 One-Hot Encoding
X_test = pd.get_dummies(test.drop(columns=["id"]))
# 對齊欄位,訓練模型時使用的是 X_train,所以現在必須讓 X_test 的欄位順序和內容完全對齊
X_test = X_test.reindex(columns=X_train.columns, fill_value=0)
# 預測機率
y_pred_prob = model.predict_proba(X_test)[:, 1]
# 儲存「測試集」機率
np.save("y_test_pred_prob.npy", y_test_pred_prob)
# 建立提交檔案
pred_df = pd.DataFrame({
"id": test["id"].astype(int),
"y": y_pred_prob.astype(float)
})
pred_df.to_csv("submission.csv", index=False)
#下載檔案
from google.colab import files
files.download("submission.csv")
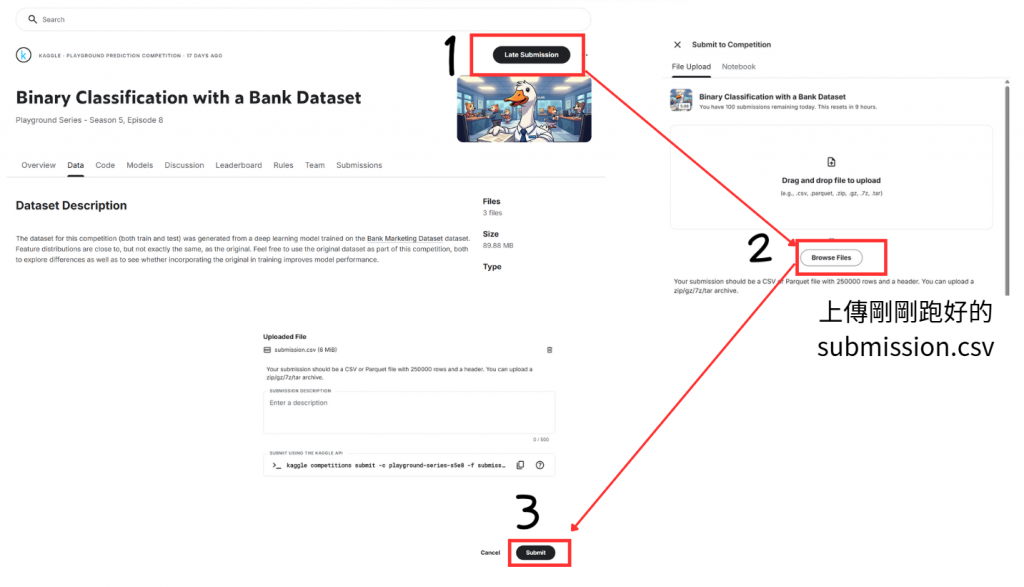
根據下面步驟就可以上傳到kaggle上查看自己的分數,可以看到有Public Score跟Private Score
Public Score
上傳 submission.csv 後立即看到的分數,用的是主辦單位測試集的一部分,比賽進行期間,排行榜(Leaderboard)的名次會依此分數做排序。
Private Score
比賽結束後才會公布的最終分數,用的是測試集剩下的大部分,最終名次會根據 Private Score 決定,因此常見「榜單大洗牌」。
Q:為什麼我現在看得到 Private Score?
A:因為這場比賽已經結束,Kaggle 會解鎖Private Score並計算最終成績,所以同時會看到 Public 與 Private 分數與名次的差異。



 iThome鐵人賽
iThome鐵人賽