隨著系統業務量增加,即便將查詢優化到極致,系統仍會負荷不了瞬間大量查詢,此時只剩垂直與水平擴充兩個選項,垂直擴充相對簡單,提升硬體 CPU 和記憶體,但缺點是升級時需要停機,因此水平擴充較為常見,MySQL 常見的 Cluster 架構就是 Master-Slave 架構,一台 Master 處理寫入請求並同步給多台 Slave,而多台 Slave 負責查詢請求。
多 Master 的 Cluster 架構較複雜且容易出錯,例如:
那麼 Master 如何向 Slave 同步資料?
當 Master 收到更新請求 (e.g INSERT, UPDATE, DELETE ) 時,需要即時將修改內容同步給 Slave,同步方式有兩種,Push & Pull:
Master Push 方式 - Master 主動推送更新資料給 Slave
優點
Slave Pull 方式 - Slave 向 Master 拉取更新資料
優點
在單 Master 架構中,Master 是唯一寫入點,其穩定性與效能很重要。為了降低 Master 的複雜度與負載風險,MySQL 採用 Slave 主動拉取資料 的設計,雖然資料同步會有些許延遲,但優點是:
而在拉取模式下,Master 要將變更資料先寫入一個暫存區,讓不同的 Slave 依照其進度拉取資料,而這個暫存區就是 Binlog!
既然所有寫入都會先寫到 Redo Log 中,Slave 不能直接去 Redo Log 拉資料同步嗎?然而,直接用 Redo Log 同步資料有兩個缺點:
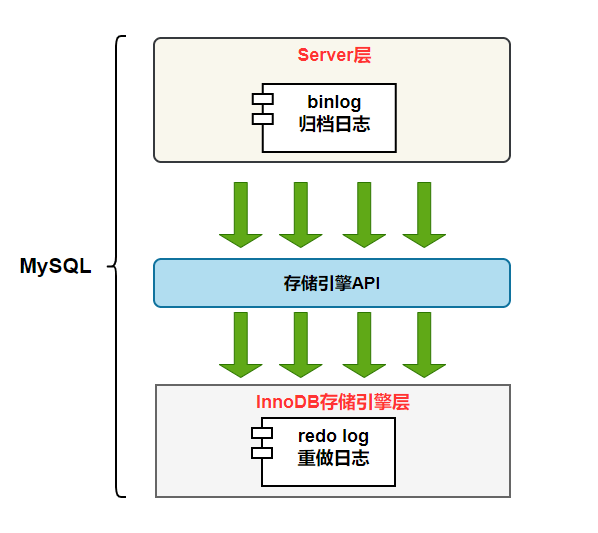
(圖來源:https://javaguide.cn/database/mysql/mysql-logs.html#%E5%89%8D%E8%A8%80)
而 Binlog 的儲存格式有分:
STATEMENT:直接儲存 SQL 指令內容 (e.g INSERT )
NOW(), RAND() )會導致 Master Slave 資料不一致ROW:直接儲存修改後的完整資料內容
MIXED:結合 Statement & Row 依照 MySQL 自行判斷何時要用哪個
如果 Redo Log 成功 Binlog 失敗會造成 Master 和 Slave 資料不一致,因此 MySQL 透過 2-Phased Commit 解決 Redo Log & Binlog 同步議題:
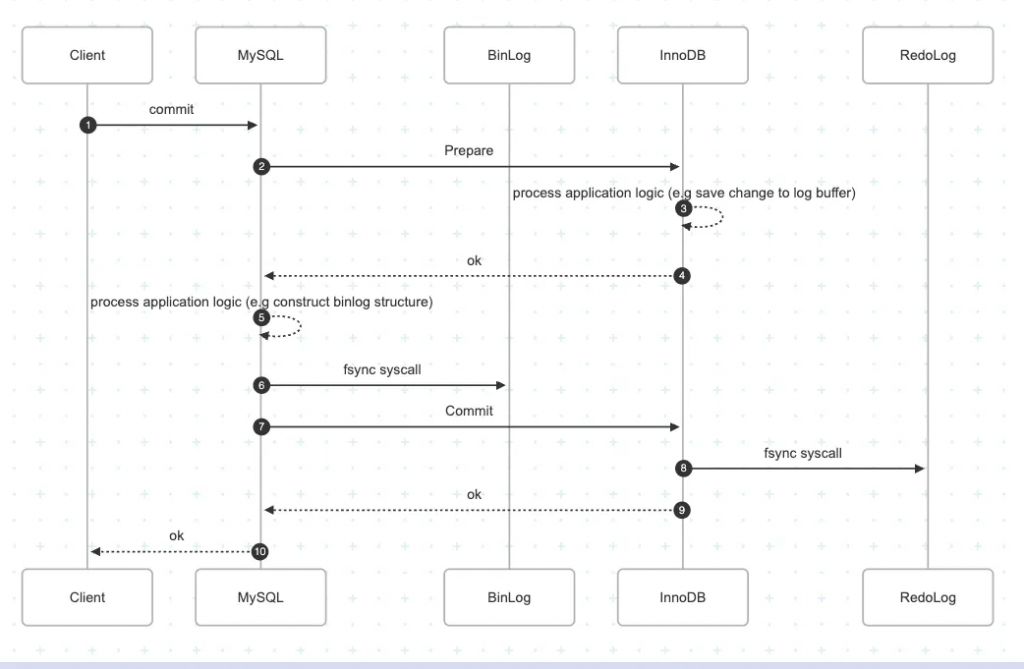
(作者產圖)
其核心精神是;
而 2-Phased Commit 也有 Group Commit 技術,但實作方式 SQL Layer 層聚合多筆 Transaction Commit 後的內容,透過 2-Phased Commit 流程,用一個 Prepare 送出多筆變更,最後執行一個 fsync 寫入多筆內容。
可透過下面參數控制 SQL Layer 聚合方式:
首先 Slave 要知道從 Binlog 哪個起點開始同步,且避免故障重啟要重頭同步,Slave 要記住上次同步的進度。
傳統是 Binlog File Location & Position 方式 (執行 SHOW MASTER STATUS;):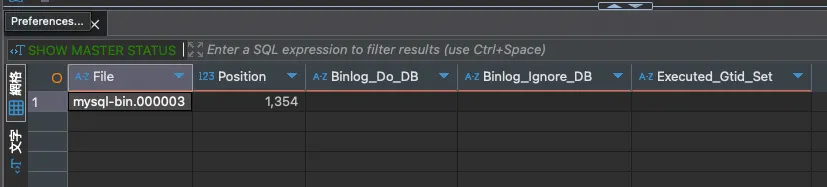
(作者產圖)
File: Binlog 檔案名稱,後面數字為遞增數字,越大代表資料越新
Position:代表 Binlog 寫入進度,是 bytes 單位,也是下一個寫入的起始位置
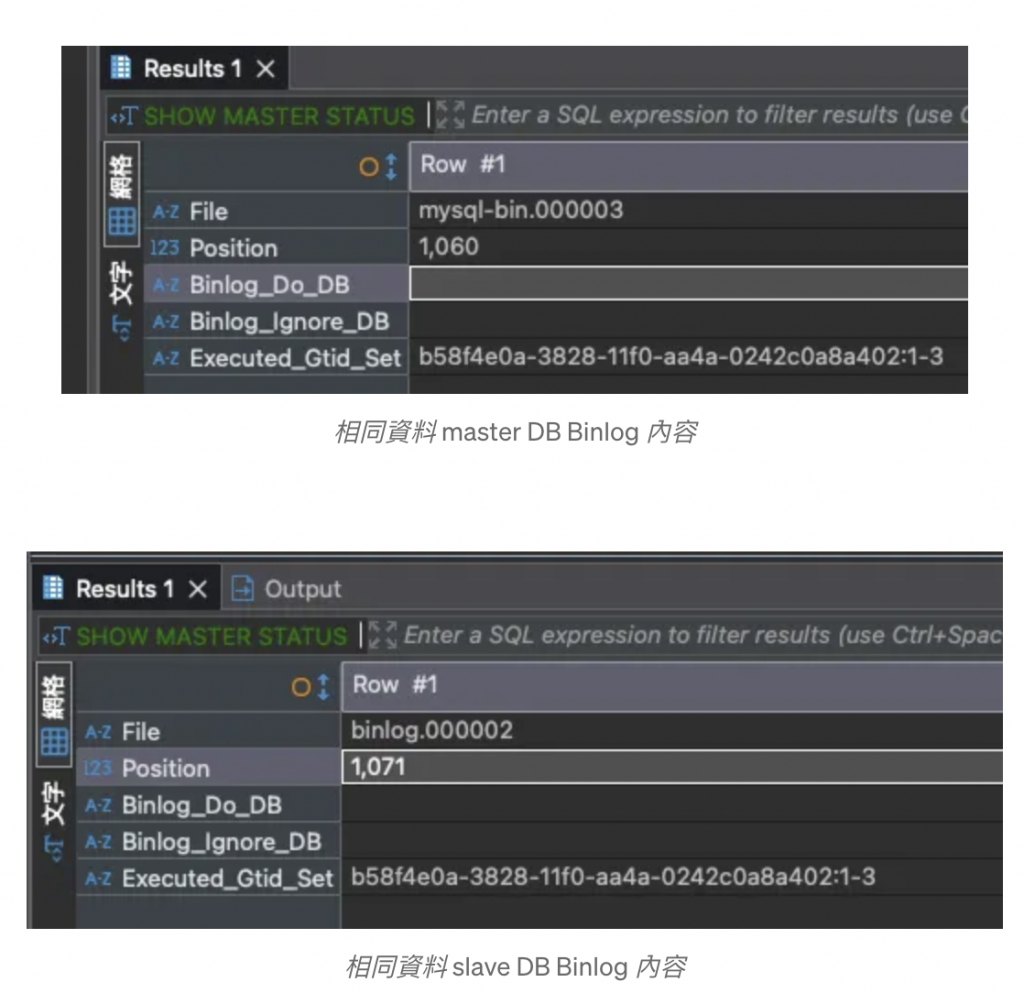
該方式好理解,但缺點是不同 DB 同步相同 Binlog 內容,但顯示出的 File Location & Position 卻不一定相同:
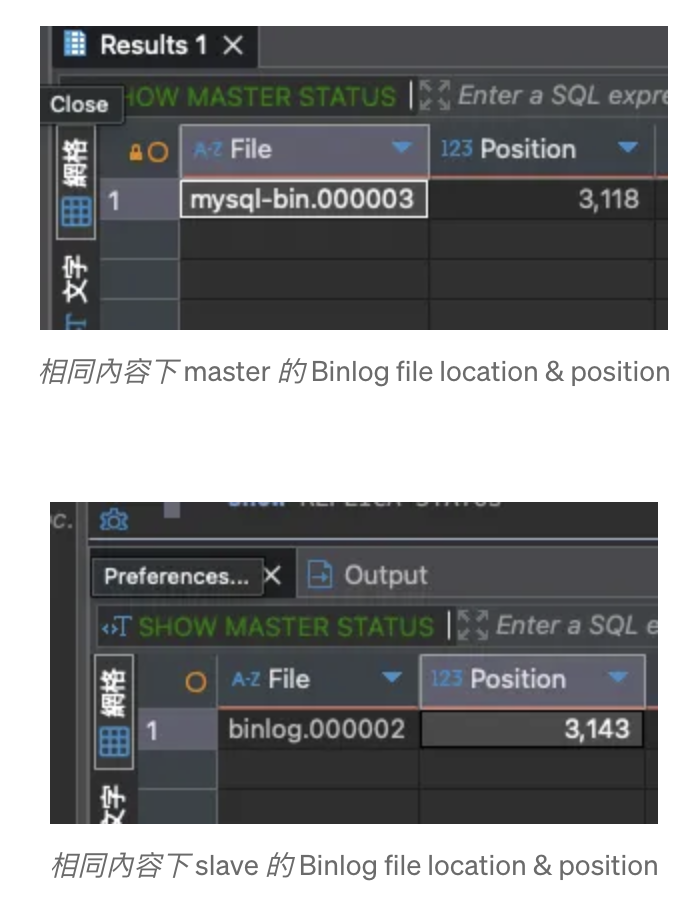
(作者產圖)
原因是不同 Server 有不同配置,例如不同 Binlog 檔名,是否要壓縮,Format 等等,就算配置都一樣, Binlog 紀錄的 Header 會依照不同 Server 有所差異,就會導致大小不依而產生不同的 Position。
而不同 File Location & Position 會帶來 Fail Over 的問題,假設 Master 掛了短時間無法恢復,必須把 Slave 轉成 Master,但轉換後卻發現新 Master 的 File Location & Position 的內容跟舊 Master 不一致,導致其他 Slave 沒法用目前進度來繼續同步新資料,因此需要人工介入,重新設定所有 Slave 的 Binlog 起始點,無法做到自動化 Fail Over。
為了解決該問題,MySQL 使用 Gtid 的出現,跨 DB 的唯一 Transaction ID,其格式為 _source_id_:_transaction_id :
(作者產圖)
如圖,相同的 Binlog 內容,雖然 File Location & Position 不同,但 Executed_Gtid_set 相同,Gtid Set 是用來表達多個 Gtid 的格式 ( source_id:begin_transaction_id-last_transaction_id ),例如:
Slave 從 Master Binlog 拉取資料後不會馬上寫入 Redo Log,而是先同步到 Relay Log 中,原因在於:
Relay Log 作為中繼檔案可避免每次讀取後需馬上解析並更新所帶來的延遲與風險,單純同步 Binlog 資料到 Relay Log,寫入成本低、邏輯單純,能提高拉取效能並保證系統異常後可回溯。
有 Relay Log 後可將純寫入 & SQL 執行邏輯解耦,實現雙執行緒模型,Replica I/O Thread 負責拉取資料並寫入到 Relay Log,Replica SQL Thread 負責讀取 Relay Log 並寫入到 InnoDB,好處是錯誤隔離且能針對彼此情境做單獨優化。
說到優化,Replica I/O & SQL Thread 作為同步兩大核心,其效能會影響 Slave 同步速度,首先:
Replica I/O Thread 負責連上 Master 後不斷拉取資料,為確保 Relay Log 順序跟 Binlog 順序一致因此無法並行處理,不過 I/O Thread 只負責同步資料,其效能瓶頸在於網路吞吐量,需要能內拉取大量資料並一次執行 fsync ,因此可透過 binlog_transaction_compression 參數壓縮 binlog 內容提高吞吐。
Replica SQL Thread 需解析 Binlog 並透過 Storage Engine 寫入資料,其邏輯較複雜且耗時,需透過並行處理提高同步速度,因此 MySQL 使用了 Multi-Threaded Replica (a.k.a MTS) 技術。
要並行執行 SQL 首先要確保 SQL 之間沒有依賴關係,例如:
transaction A
UPDATE users SET status = 2 WHERE user_id = 1;
transaction B
UPDATE users SET status = 1 WHERE status = 2;
上面案例執行順序不同,產生結果就會不相同,因此有依賴關係。
最簡單的判斷邏輯就是不同 DB 的 Transaction 彼此絕對沒有依賴關係:
transaction A
UPDATE db_a.users SET status = 2 WHERE user_id = 1;
transaction B
UPDATE db_b.users SET status = 1 WHERE status = 2;
這也是 MySQL 5.6 引進的 Per-Database Replication,但實用性太低,大部分情況都是單一 DB 就需要有好的同步效能,因此 MySQL 5.7 開發了 Logical_clock Replication:
其概念是 Master 並行執行了哪些 Transaction,Slave 就也可以並行處理,而 Master 實際並行執行的 Transaction 就是 Group Commit 中的Transaction,因此 MySQL 在 Binlog 內容中加入了 Group Commit 的邊際值,而 Logical_clock Replication 會透過分析 Group Commit 邊際值來判斷哪些 Transaction 是可以並行執行的:
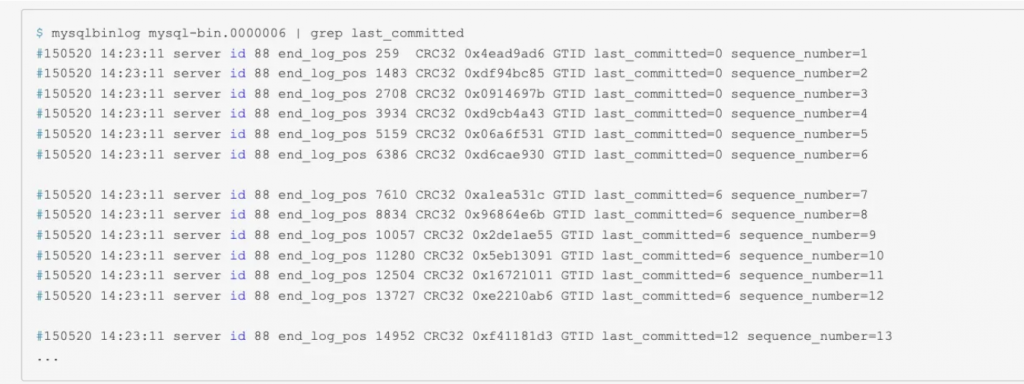
(圖來源:https://www.cnblogs.com/konggg/p/16359474.html#%E6%94%AF%E6%8C%81%E5%B9%B6%E8%A1%8C%E5%A4%8D%E5%88%B6%E7%9A%84gtid)
上面 Binlog 內容的 last_committed 代表 transaction 執行時前一個完成的 transaction 序號,因此相同時 last_committed 值的 transaction 代表是同時執行的,Logical_clock Replication 會解析該內容找出可並行處理的 transaction。


 iThome鐵人賽
iThome鐵人賽