經過前幾天的修煉,我們有了數據(新石油),認識了數據英雄,也為數據蓋好了房子(資料庫、倉儲、資料湖)。但問題來了,當資料湖裡堆滿了成千上萬個檔案,一個新人進來,他怎麼知道 order_20231026.csv 裡的 col_A 欄位到底是什麼意思?是訂單金額還是數量?單位是台幣還是美金?
如果沒有一份「說明書」,這些數據就像一本天書,難以解讀和利用。這份說明書,就是我們今天要談的主角 — Metadata (詮釋資料)。
圖片參考來源: https://www.braintraffic.com/blog/an-introduction-to-metadata-and-taxonomies
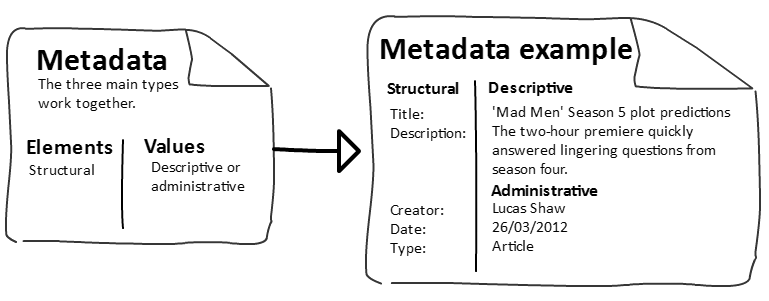
簡單來說,Metadata 就是「描述資料的資料」(Data about Data)。
就像一本書的封面和版權頁,它告訴你書名、作者、出版社、出版日期等資訊,讓你不用讀完整本書,就能對它有基本的了解。在數據世界裡,Metadata 扮演著同樣的角色,它就是數據的「身分證」。
Metadata 可以包含:
rev 是指 含稅後的營收)、資料擁有者 (哪個部門負責)、資料來源。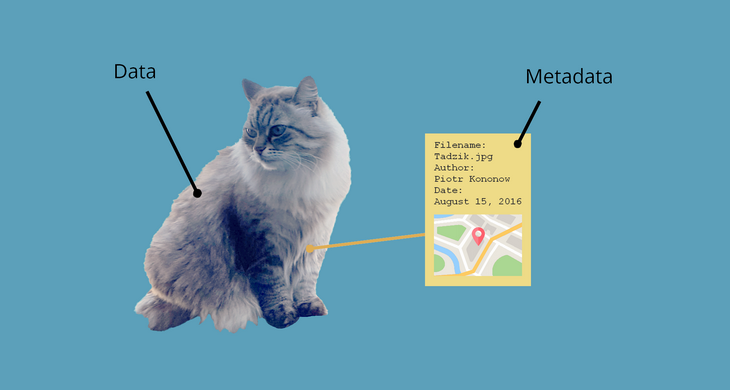
圖片參考來源: https://dataedo.com/kb/data-glossary/what-is-metadata
在傳統作法中(例如一個 Excel 檔案),數據和 Metadata 經常混在一起。欄位名稱(Metadata)和儲存格內容(Data)都在同一個檔案裡。
但現代資料架構,特別是在資料湖的場景下,強調一個核心原則:將數據與 Metadata 分離儲存。數據本體(例如 Parquet 檔案)存放在物件儲存中,而描述這些檔案的 Metadata,則集中存放在一個稱為 Data Catalog (資料目錄) 的地方。
為什麼要這樣做?
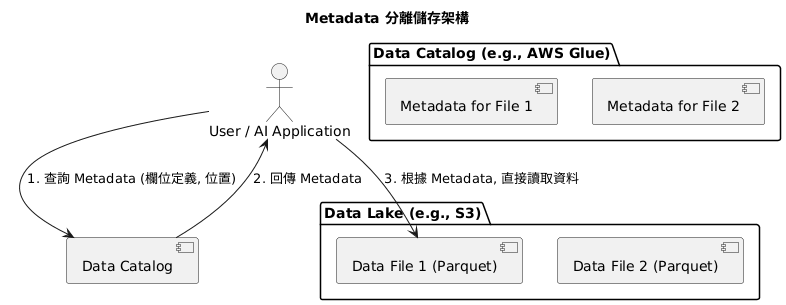
Metadata 看似不起眼,卻是現代資料治理與自動化的基石。如果沒有良好的 Metadata 管理機制,你的資料湖最終只會變成誰也看不懂、誰也不敢用的「資料沼澤」(Data Swamp)。
為數據建立清晰的身分證,不僅能讓團隊協作更順暢,更是讓 AI 應用得以規模化、可信任的關鍵。從今天起,養成記錄 Metadata 的好習慣,是每位數據修煉者的必修課。

