在 Day02 的篇章,簡單探討了 LLM 理解、記憶限制,以及讀取長文本內容時要注意的問題後,你有發現嗎?不論是溝通到它開始失憶,或是一次丟入太多內容導致它消化不良,行為的背後共通點都跟 Prompt 有關。
當發現LLM 回覆開始鬼打牆時,以我自己的經驗來說,我會採取
長文本指的是很長的 Prompt 內容,通常這類的內容會容易觸發 Lost in the middle 現象 ,為了減輕 LLM 對於頭尾重的理解影響,你可以以下列方法處理:
實際舉例來說,假設我收到的 Jira 任務單內容是
JIRA 12394324: 處理代理商頁面按鈕失效
- 問題描述:當使用者登入後點擊「搜尋」按鈕無反應
- 相關頁面:/agent/:id
- 相關元件:AgentManagementDetail,
因為不理解元件內容,所以請 AI 協助快速的介紹元件內容,若是以簡單的 Prompt
@元件
請幫我分析這個元件
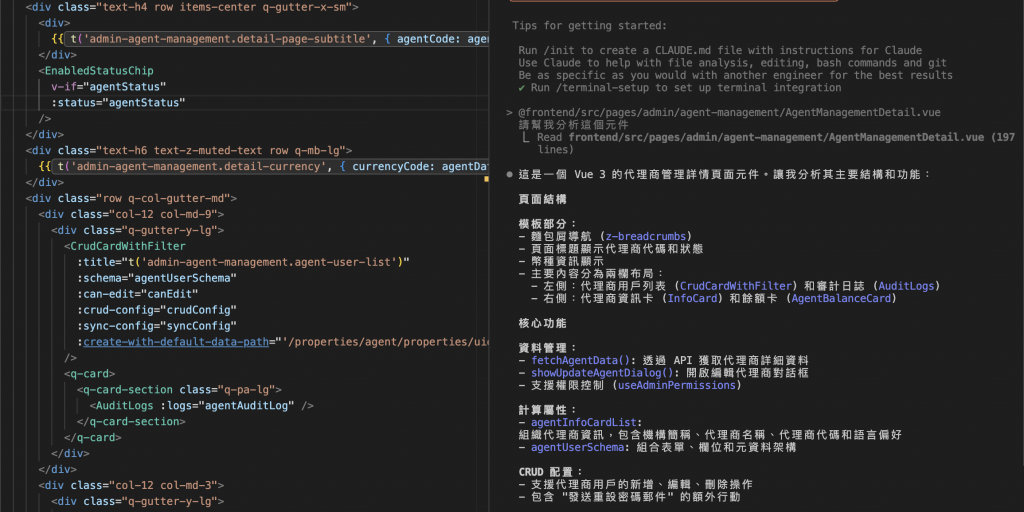
以現在模型的成熟度,是能解讀一定程度的元件內容(如上圖)
簡單來說就是先幫它列出重點,專注在你最在意的內容
@元件
請依序告訴我:
1. 主要的 props 有哪些
2. 使用了哪些 hooks
3. 有哪些主要的事件處理函數
4. 依賴了哪些外部元件
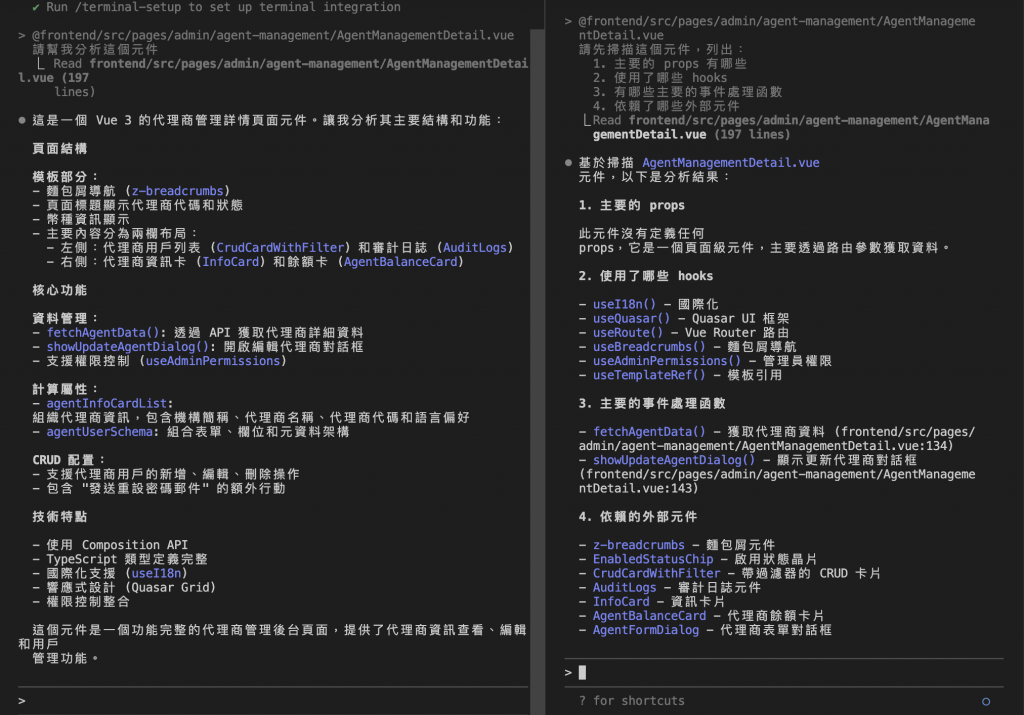
小提醒:這個優化技巧用於 GPT, Claude 這類 AI 聊天平台,若是使用 Claude code , Cursor 則相對不需要理解
LLMs 被訓練能夠理解 XML 標籤,我們能透過標籤標示出 Prompt 架構,提升 LLM 閱讀的精確度,常見的架構包含
<document>
// 長文本內容
</document>
{查詢行為}
文件推薦先放長文本內容,再放查詢行為,因為測試顯示,將查詢放在末尾可以將回應品質提升高達 30%,尤其是在處理複雜的多文件輸入時。
賦予身份的用途在於,它會把自己帶入那個角色,並以角色相關的知識去回答你的問題,例如:
假設你今天提交功能給 QA 前,最後想再測試功能狀況
@元件
你今天是 QA 身份
請依序告訴我:
1.這個功能你會測試哪些情境?
2.目前測試起來功能是能正常運行的嗎?
又或者設計共用元件時,也請它當資深前端同事給你回饋。
這部分或許不完全算是優化 Prompt ,而是 用可程式化的專案上下文,降低對單次 prompt 精度的依賴,對我來說是從另一個面向來提升 Prompt 的精確度,這邊以 Claude code 為例
/init
該指令的用途是:能讓它初步掃視整個專案並記錄下專案中的關鍵內容,讓後續回答更貼近專案上下文進行。
下方兩個連結分別是收集了 Claude、Cursor 等公司內部成員的 Prompt ,包含系統性、產生新功能性等面向的 Prompt 範例,以及 Google 開設的 Prompt engineering 學程
因為自認為是初階 Prompt engineer(?),所以寫這篇文章的初衷是:所以目標是尋找初階開發者通用的提升技巧,希望大家都能有所收穫!
那麼,明天見。
-- to be continued --

