今天正式踏進「語音情緒」的世界。之前文字情緒分類已經走過一輪,這次要挑戰的是聲音,要讓系統能聽懂我說話裡的情緒!!
一開始我想用 ASIC (Affective Speech in Chinese) 這個資料集,因為它是專門做中文語音情緒的 benchmark。但我並沒有找到ASIC 公開的下載入口,好像需要研究單位授權,我覺得有點太麻煩了只好放棄
我改用 Emotional Speech Dataset (ESD),這個資料集有中英文版本,我選用中文子集,因為我目前的目標就只是想辨識中文而已,並自己整理成一個 esd_cn.csv 檔案來做訓練。
類別原本有多種(快樂、悲傷、生氣、害怕、驚訝、中立…),我重新 mapping 成 三類:正向 / 中立 / 負向 (暫時只分三類,先建立 baseline,之後再細分成更多情緒類別)
錄音品質乾淨,標註完整,方便直接訓練 baseline,HuggingFace datasets 就能直接處理,挺方便的~
我選擇了 TencentGameMate/chinese-wav2vec2-base。這是一個針對中文語音訓練的 Wav2Vec2 模型,可以直接從 raw waveform 學習,不需要額外算 MFCC 特徵,非常省事
好處是 HuggingFace 上可以直接載入並 fine-tune,對我這種 side project 來說超方便
載入音檔時透過 librosa.load(..., sr=16000) 統一成 16kHz 單聲道,符合 Wav2Vec2 的輸入要求,然後用 HuggingFace 的 Trainer 做 fine-tuning:
UAR (Unweighted Average Recall) 指的是「各類別 recall 的平均值」。在類別數量不平衡時,比單純 accuracy 更公平,因為每個類別的貢獻一樣大。
第一輪訓練結果完全超乎預期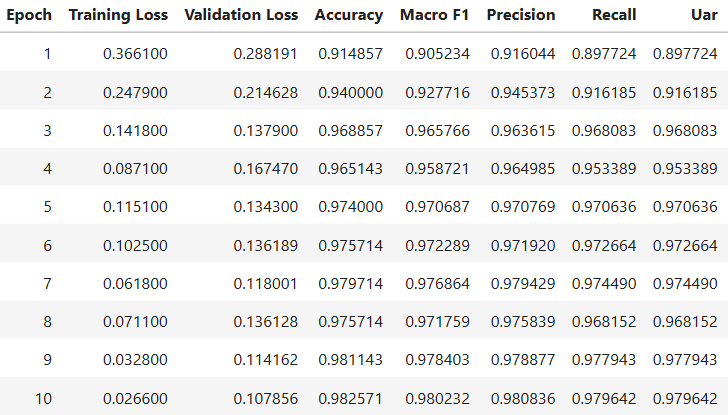
我原本設的驗收門檻是 UAR ≥ 0.6,結果拿到 UAR ≈ 0.97,大幅超標!
這也是 pretrained 模型的威力 —— 以前課堂上都是 from scratch,幾乎不可能看到這麼高的數字><
不過也確實跑了滿久,大概四個小時(GPU 訓練,樣本量也不少)
丟了一條語音進去,可以看到模型很明確地抓到「正向」情緒。這樣的結果比單純看文字更貼近直覺,因為聲音的情感表達往往比文字更豐富
('positive',
[9.348189632873982e-05, 0.00012997715384699404, 0.9997765421867371])
今天的重點是把 pipeline 跑通,而這點我已經達成,甚至結果遠超預期!!
明天 Day 27,我就要把這個模型包成 API,實際串到前端 demo,錄音 → 傳到後端 → 回傳情緒分布 → 在網頁顯示

