我的日記系統原本就支援語音輸入(錄音 → 自動轉文字)。今天把這條流程升級成「雙軌並行」:
錄音一次 →
這樣使用者不只留下內容,也能看到自己當下的情緒輪廓
既有的 Web Speech API 繼續負責把語音變成文字(zh-TW),我維持原本的流程:輸入框 → 儲存到 Firestore。
同一段錄音檔同時送到 Hugging Face Spaces 上我部署的 情緒推論 API(FastAPI + Docker Runtime),API 回傳每一類情緒的機率分布:
{
"pred": "positive",
"probs": { "positive": 0.72, "neutral": 0.18, "negative": 0.10 }
}
前端用 MediaRecorder 取到 Blob,不同瀏覽器會給不同格式(常見是 audio/webm 或 audio/m4a)
為了穩定推論,我把前端盡量轉成 WAV 16kHz mono 上傳,後端統一用 librosa 讀入,再重採樣到 16kHz(和模型訓練一致)
先前碰過一次「Format not recognised」的錯誤(音檔解不開),關鍵就是 正確封裝檔案 + 不要硬蓋 Content-Type。現在已能穩定通過。
我把 API 回傳設計成固定欄位,方便前端渲染:
{
"pred": "neutral",
"probs": {
"positive": 0.35,
"neutral": 0.55,
"negative": 0.10
}
}
前端只需要讀取 pred,顯示一個情緒標籤,就能即時呈現結果
在日記列表中,每篇(不管是文字輸入或語音輸入)都顯示:日期 | 內容摘要 | 情緒標籤 (Top-1 + 百分比)
這樣語音日記和文字日記在 UI 上完全一致,不需要額外存語音檔,也不會讓畫面複雜
送出音檔後會先顯示「分析中…」的 loading 狀態,等 API 回傳後再更新標籤
若 API 失敗,則顯示「無法取得情緒結果(可稍後重試)」,但仍然會存下文字內容
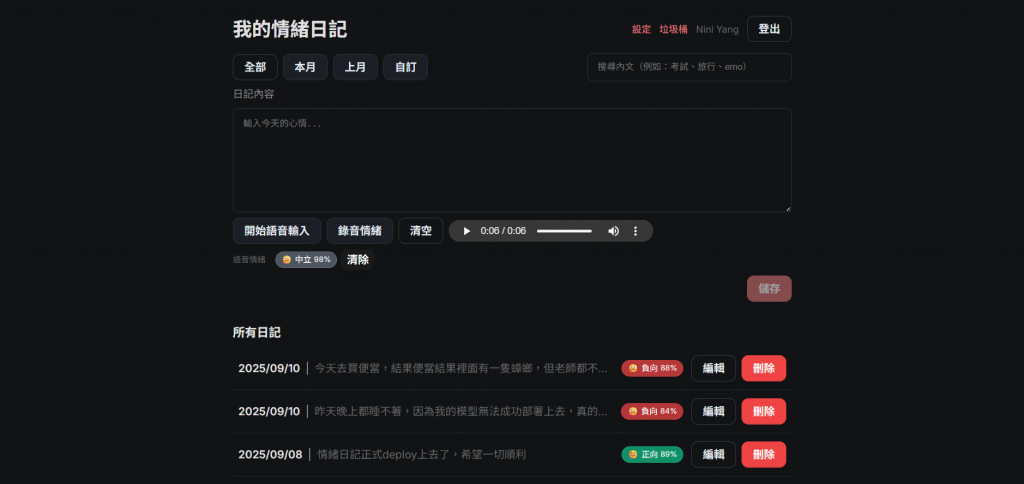
不過目前遇到的問題是,結束錄音後會在畫面顯示一個音檔,但播放卻沒有聲音,不知為何
雖然測試集的 UAR 已經驗證過,但我要檢查「真實場景」的表現:
這樣才能確認系統不只是「數字好看」,而是真的能在日常使用中發揮作用!

