昨天我們提到 LLM 有三個限制:資料過時、資料來源有限,以及容易產生幻覺。今天要介紹的 RAG(Retrieval-Augmented Generation),就是為了補上這些缺口而設計的。
要理解 RAG,我們先來看一下它的 架構圖: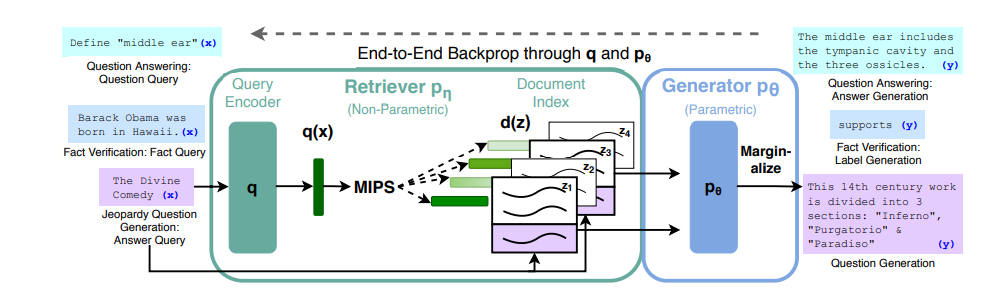
圖片來源:Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
這張圖可能一開始看起來有點複雜,不過不用擔心,接下來我們會一步一步拆解,慢慢解釋 RAG 想要傳達的概念。
這邊說明一下為什麼會用向量資料庫,因為電腦不像人類一樣能直接理解文字的意思,但它能處理數字,所以我們會把文字轉成向量。這裡先簡單點到,之後我會再介紹更詳細完整的內容~
簡單讓大家知道 RAG 的整體架構後,明天我們就要進一步學習如何建立知識庫。這個過程的第一步,就是 Chunking(文件切分)——把長長的文件切成 AI 可以理解的小片段。

