昨天看到 RAG 架構,今天要更深入,看看如何建立知識庫。
我們先看這張圖來逐一拆解他的步驟: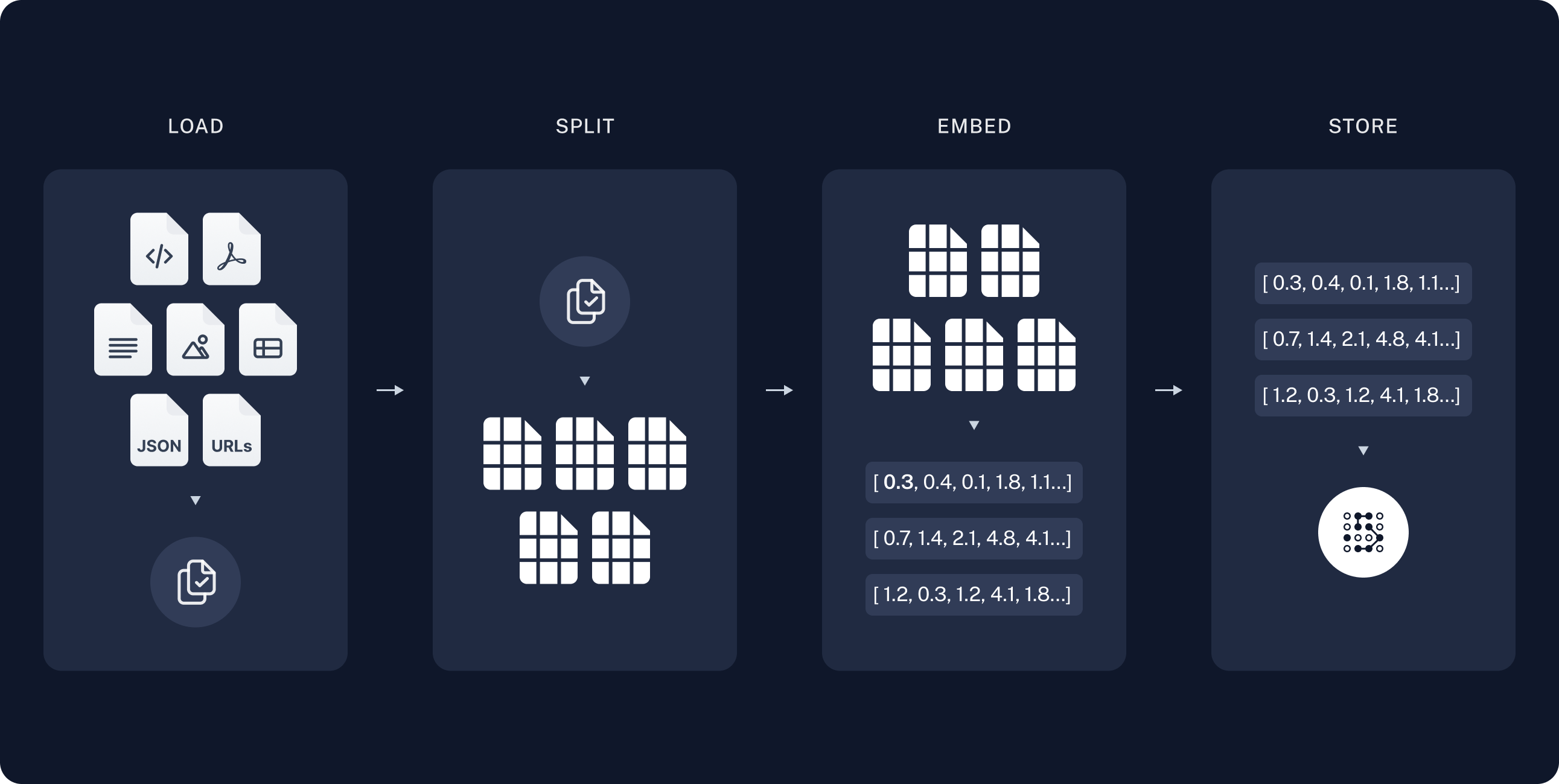
來源:Build a Retrieval Augmented Generation (RAG) App: Part 1
這邊我們可以稱之為 Indexing pipeline
他的流程是這樣:
資料載入(Loading)
其實這邊可以再細分成四個步驟:
連接資料來源 -> 擷取文字內容 -> 審查及補上必要的 metadata ->清理或轉換資料
因為資料的來源可能有很多,光是檔案類型就有pdf、doc...說不清的類型了,所以也務必記下自己所使用的資料來源及檔案類型,選取好資料後,我們必須要擷取到自己需要的資料,之後加上檔案來源、作者、日期、標籤等資訊,方便後續檢索,最後再將不必要文字訊息進行清理與轉換,就跟我們學習一樣我們不能只是一昧地把書本內容往腦袋裡塞,而是需要消化過後標記好重要的部分。
文本切分(Chunking)
再來我們要將過長的文字進行拆分,就像是你跑去問 chatGPT 一樣,他會有文字數量限制,他能夠處理的內容有限。
詳細的來說,這邊可以歸咎到幾點問題:
第一, LLM 技術的限制,導致他不能吸收這麼大量的文字,你丟給他多又雜的資訊他也很難消化。
第二, LLM 在你給他一大段文字過後,他其實只會注重前後文,中間段落他會是模糊的。
所以這個步驟,我們會把長篇文字拆成有意義的小單位(如句子或段落),逐步合併成特定大小的區塊,最後再將這些區塊逐步連接保持語意的通順。
想像你在整理一本厚厚的教科書,不可能一次全塞給模型讀,所以要先把它切成章節或段落,再把段落拼成適合大小的筆記,最後還要留一點重疊,像書籤一樣,讓上下文能接得上。
如果還要再細部說明其實他還有很多種拆分方式最常見的方式是 Split by character 和 Recursively split by character,可以是使用特殊字元像是 \n 作為斷點切割這些文字,簡單來說就是用字元或斷行符號來切割文字,這個我們日後可以再繼續探討。
轉換向量(Embeddings)
我們先前也提到過了,電腦是學不懂這些文字的,所以我們要文字轉為向量,也就是所謂的 embeddings,其實就是把這些文字轉成 n 維矩陣,當我們的矩陣越大,就可以越精準的表示這個詞的意義,但需要花費的計算成本也比較高。
向量儲存(Vector DB)
最後,將向量存進 向量資料庫(Vector Database),例如 FAISS、Chroma、Pinecone、Weaviate 等。
資料庫會支援 相似度搜尋(cosine similarity、dot product、L2 distance)。也能透過 metadata 過濾,例如「只搜尋 2023 年之後的文件」。這讓我們可以快速找到與查詢最相關的 chunks,成為 RAG 的基礎。
今天跟往常一樣,先讓大家有個基本的概念,明天會再細部補充 pipeline 的內容!!

