在學深度學習之前,我們先要認識 「資料處理」 這件事。
因為 AI 模型吃的是資料,如果原始資料是亂七八糟的,
模型再聰明也只能學到一堆垃圾。
就像你在做一份財務報表,如果數字和日期都填錯了,最後的結論一定不可靠。
而在 Python 的世界裡,最常用來處理資料的工具就是 「pandas」。
pandas 是 Python 的一個函式庫,專門用來處理表格型態的資料。
你可以把它想像成 「升級版的 Excel」 ,
但它更強大、更快速,而且能處理更龐大的資料。
舉例來說:
在 Excel 裡,你可能需要拉一堆公式來做加總、篩選。
但在 pandas 裡,只要一行程式,就能做出同樣甚至更複雜的結果。
而且,pandas 可以直接把 CSV、Excel、SQL 資料庫的資料載入,
讓我們可以快速開始分析。
這就是為什麼職場上很多數據分析師、AI 工程師,都離不開 pandas。
在開始操作之前,要先搞清楚 pandas 的 「靈魂角色」 :
Series 可以想像成 「一欄 Excel 的資料」 。
例如一組「員工年齡」:
25, 30, 28, 35, 40
在 pandas 裡,這就是一個 Series。
DataFrame 則可以想像成 「整張 Excel 表格」 ,裡面有多個欄位。
例如一份「員工資料表」:
姓名 年齡 部門
田一明 25 行銷
陳小華 30 財務
梅帥哥 48 IT
在 pandas 裡,這張表格就會是一個 DataFrame。
我們也可以這樣理解:
Series = 一欄
DataFrame = 多欄組成的一張表格
這兩個就是我們在處理資料的兩個核心重要物件。
現在我來做一個簡單的實例操作,我建立了一個類似部門人員資料的 CSV 檔,
內容如下(work.csv):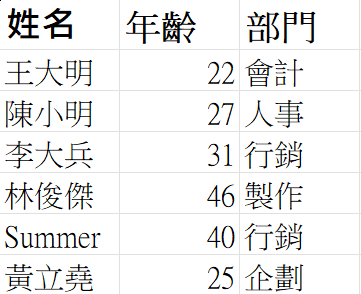
而我們今天的目標要用 pandas 做以下三件事:
讀取資料、篩選出「行銷部門」的員工、算出所有員工的平均年齡。
以下是我們要執行的程式碼:
import pandas as pd # 載入 pandas
from google.colab import files
uploaded = files.upload()
# 1. 讀取 CSV 檔
df = pd.read_csv("work.csv")
print("=== 原始資料 ===")
print(df)
# 2. 篩選出行銷部門
marketing = df[df["部門"] == "行銷"]
print("\n=== 行銷部門 ===")
print(marketing)
# 3. 計算平均年齡
avg_age = df["年齡"].mean()
print("\n所有員工的平均年齡:", avg_age)
這邊簡短對程式碼進行解釋:
我們要先創立一個資料上傳的地方,讓網頁可以正確地讀取到我們的csv檔案,
再來就是很基礎的程式碼概念,並利用了pandas的計算函數「mean」,
就可以很輕鬆地把年齡平均計算出來了。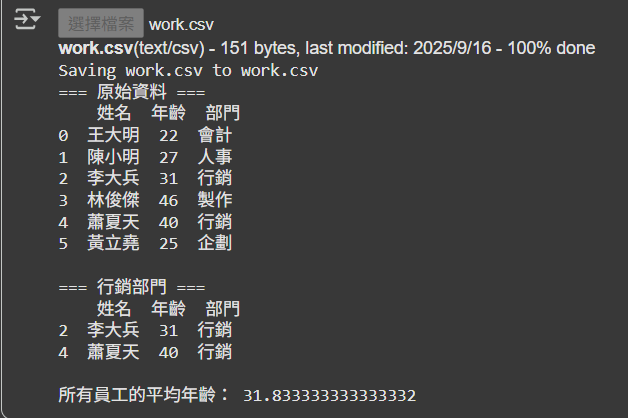
未來我們在做深度學習之前,都會先用 pandas 把資料整理好,
再交給模型去學習。這一天的學習,就是打好使用pandas的基礎,
讓我們之後的操作可以更得心應手。

