在今天的文章中,我們就接續昨天的「垃圾郵件分類」學習,
還沒閱讀過前一天文章的讀者可以先移駕到前一篇文章,
有對於該實作題目的詳細說明。
那我們就繼續開始了!
# 使用更高的學習率
optimizer = keras.optimizers.Adam(learning_rate=0.002)
model.compile(
optimizer=optimizer,
loss='binary_crossentropy',
metrics=['accuracy',
tf.keras.metrics.Precision(name='precision'),
tf.keras.metrics.Recall(name='recall')]
)
我們在昨天把模型建好了,但它還不知道應該「怎麼學」。
所以我們這裡要設定三個重要的東西:
第一個是「優化器」,我們用之前講過很多次的 Adam。
可以把它想像成一個教練,它會告訴模型「往這個方向調整會更好」。
學習率設定為 0.002,這個數字決定模型每次調整的幅度,
太大的話會像無頭蒼蠅亂撞,太小的話又學得太慢,
而0.002 是經過實驗找到的一個不錯的平衡點。
第二個是「損失函數」,我們使用 binary_crossentropy,
這個函數的工作是告訴模型「你這次答對了多少」,
答對了損失就小,答錯了損失就大。模型的目標就是讓這個損失越來越小。
第三個是追蹤哪些指標。準確率當然要追蹤,但我們還要看精確率和召回率。
假設模型說 100 封郵件是垃圾郵件,但其中只有 95 封真的是,那精確率就是 95%;
如果真正的垃圾郵件有 100 封,模型只抓到 90 封,那召回率就是 90%。
這兩個指標可以讓我們知道模型是「誤判多」還是「漏掉多」。
print("\n[Step 5] Training model...")
# 計算類別權重
class_weights = class_weight.compute_class_weight(
'balanced',
classes=np.unique(y_train),
y=y_train
)
class_weight_dict = {0: class_weights[0], 1: class_weights[1]}
print(f" Class weights: Ham={class_weight_dict[0]:.2f}, Spam={class_weight_dict[1]:.2f}")
# 添加早停機制
early_stopping = keras.callbacks.EarlyStopping(
monitor='val_loss',
patience=3,
restore_best_weights=True
)
print("=" * 60)
history = model.fit(
X_train_vec,
y_train,
epochs=20,
batch_size=64,
validation_split=0.2,
class_weight=class_weight_dict,
callbacks=[early_stopping],
verbose=1
)
在開始訓練之前,我們要先處理前面提到的「數據不平衡」問題。
我們用「類別權重」來解決。
什麼意思?就是告訴模型:
「如果你漏掉一封垃圾郵件,罰你 6.5 分;但如果你誤判一封正常郵件,只罰 0.75 分」。
這樣模型就會更努力去抓垃圾郵件,不會只想著偷懶全部猜「正常郵件」。
另外我們還加了一個「早停機制」(Early Stopping)。
這是什麼?想像你在練習投籃,一開始越練越準,但練太久反而開始亂投。
早停機制會監控你的表現,如果連續 3 次都沒進步,就會說「好了,休息吧,別練了」,
並且把你最好的那次成績記下來。
專業一點來說就是:當驗證損失連續 3 個 epochs 沒有改善時,自動停止訓練。
這樣可以避免「過度訓練」,讓模型在真實情況下也能表現好。
訓練過程中,模型會看數據 20 遍(20 個 epochs),
每看一遍,它就會調整自己的參數,讓預測越來越準,
我們把數據分成一批一批(每批 64 個),一批一批餵給模型,這樣比較有效率。
print("\n[Step 6] Evaluating model on test set...")
test_results = model.evaluate(X_test_vec, y_test, verbose=0)
test_loss = test_results[0]
test_acc = test_results[1]
test_precision = test_results[2]
test_recall = test_results[3]
print("\nTest Set Performance:")
print(f" Accuracy: {test_acc:.4f} ({test_acc*100:.2f}%)")
print(f" Precision: {test_precision:.4f}")
print(f" Recall: {test_recall:.4f}")
print(f" Loss: {test_loss:.4f}")
# 計算 F1 分數
if test_precision + test_recall > 0:
f1_score = 2 * (test_precision * test_recall) / (test_precision + test_recall)
print(f" F1-Score: {f1_score:.4f}")
訓練結束,接著就是真正的「考試」了...
現在藏起來的那 20% 數據拿出來測試模型。(成果演示後面會呈現)
除此之外,我們還算了一個叫** F1 分數的東西,它是精確率和召回率的平均值**。
因有些模型可能精確率超高但召回率很低,或反過來。
F1 分數讓我們能一眼看出模型是否「均衡」。
print("\n[Step 7] Generating predictions and classification report...")
y_pred_prob = model.predict(X_test_vec, verbose=0)
y_pred = (y_pred_prob > 0.5).astype(int).flatten()
print("\nDetailed Classification Report:")
print("-" * 60)
print(classification_report(y_test, y_pred, target_names=['Ham (Normal)', 'Spam (Junk)']))
現在要仔細分析模型的表現。
我們使用 classification_report 這個工具,它會告訴我們:
對於正常郵件,模型的精確率、召回率、F1 分數各是多少;
而對於垃圾郵件,這些數字又是多少。
這樣我們才可以知道模型在哪種類別上表現比較好。
print("\n[Step 8] Creating visualizations...")
fig, axes = plt.subplots(2, 2, figsize=(15, 12))
fig.suptitle('Spam Classification Model - Training Results', fontsize=16, fontweight='bold', y=1.00)
# 子圖 1:準確率
axes[0, 0].plot(history.history['accuracy'], label='Training Accuracy', linewidth=2, marker='o')
axes[0, 0].plot(history.history['val_accuracy'], label='Validation Accuracy', linewidth=2, marker='s')
axes[0, 0].set_title('Model Accuracy', fontsize=14, fontweight='bold', pad=10)
axes[0, 0].set_xlabel('Epoch', fontsize=12)
axes[0, 0].set_ylabel('Accuracy', fontsize=12)
axes[0, 0].legend(fontsize=10)
axes[0, 0].grid(True, alpha=0.3)
# 子圖 2:損失
axes[0, 1].plot(history.history['loss'], label='Training Loss', linewidth=2, marker='o')
axes[0, 1].plot(history.history['val_loss'], label='Validation Loss', linewidth=2, marker='s')
axes[0, 1].set_title('Model Loss', fontsize=14, fontweight='bold', pad=10)
axes[0, 1].set_xlabel('Epoch', fontsize=12)
axes[0, 1].set_ylabel('Loss', fontsize=12)
axes[0, 1].legend(fontsize=10)
axes[0, 1].grid(True, alpha=0.3)
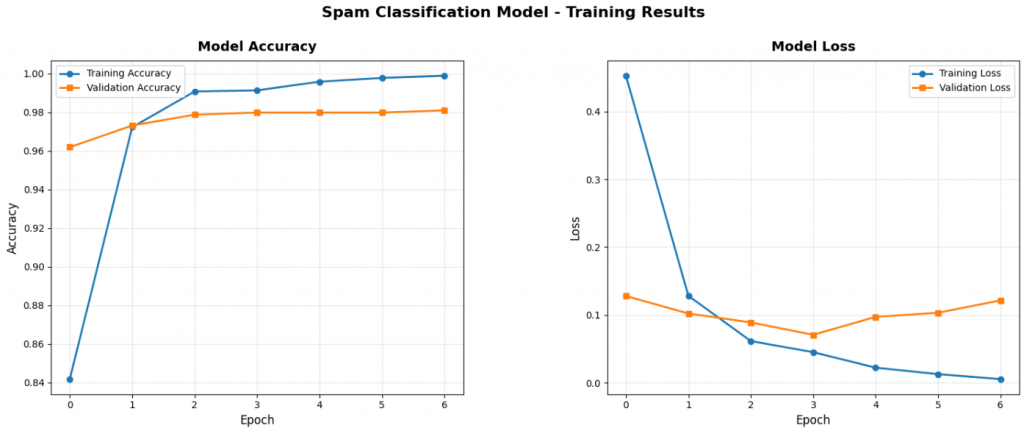
每當數字太多的時候我們都會看得眼花撩亂,但如果畫成圖就清楚多了。
我們在這次實作中畫了四張視覺化的圖表:
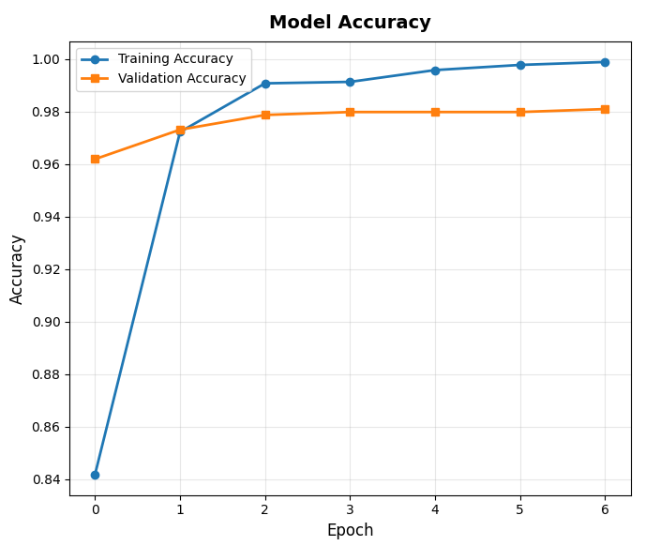
第一張是「準確率曲線」。橫軸是訓練的次數(epoch),縱軸是準確率。
這張圖最重要的是看兩條線:「訓練準確率」和「驗證準確率」。
如果訓練準確率一直漲但驗證準確率開始掉,那就是「過擬合」。
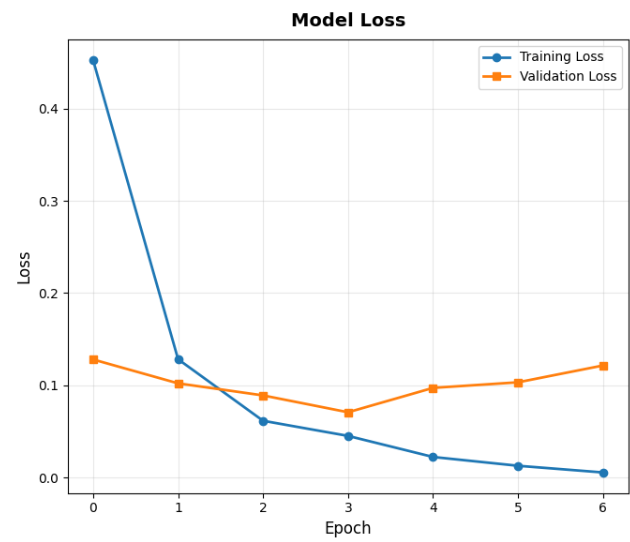
第二張是「損失曲線」。損失就是「錯誤程度」,越低越好。
理想的曲線應該是穩定下降,就像你練習某個東西,後期的錯誤也應該越來越低(你沒偷懶的話)。
# 子圖 3:混淆矩陣
cm = confusion_matrix(y_test, y_pred)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', ax=axes[1, 0],
xticklabels=['Ham', 'Spam'], yticklabels=['Ham', 'Spam'],
cbar_kws={'label': 'Count'}, annot_kws={'size': 14})
axes[1, 0].set_title('Confusion Matrix', fontsize=14, fontweight='bold', pad=10)
axes[1, 0].set_ylabel('True Label', fontsize=12)
axes[1, 0].set_xlabel('Predicted Label', fontsize=12)
# 添加統計資訊
tn, fp, fn, tp = cm.ravel()
accuracy_text = f'Accuracy: {(tp+tn)/(tp+tn+fp+fn)*100:.2f}%\nTrue Positives: {tp}\nTrue Negatives: {tn}\nFalse Positives: {fp}\nFalse Negatives: {fn}'
axes[1, 0].text(2.5, 0.5, accuracy_text, fontsize=10, ha='left', va='center',
bbox=dict(boxstyle='round', facecolor='wheat', alpha=0.5))
# 子圖 4:精確率和召回率
axes[1, 1].plot(history.history['precision'], label='Training Precision', linewidth=2, marker='o')
axes[1, 1].plot(history.history['val_precision'], label='Validation Precision', linewidth=2, marker='s')
axes[1, 1].plot(history.history['recall'], label='Training Recall', linewidth=2, marker='^')
axes[1, 1].plot(history.history['val_recall'], label='Validation Recall', linewidth=2, marker='d')
axes[1, 1].set_title('Precision and Recall', fontsize=14, fontweight='bold', pad=10)
axes[1, 1].set_xlabel('Epoch', fontsize=12)
axes[1, 1].set_ylabel('Score', fontsize=12)
axes[1, 1].legend(fontsize=9)
axes[1, 1].grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
接下來就是後面兩張了:
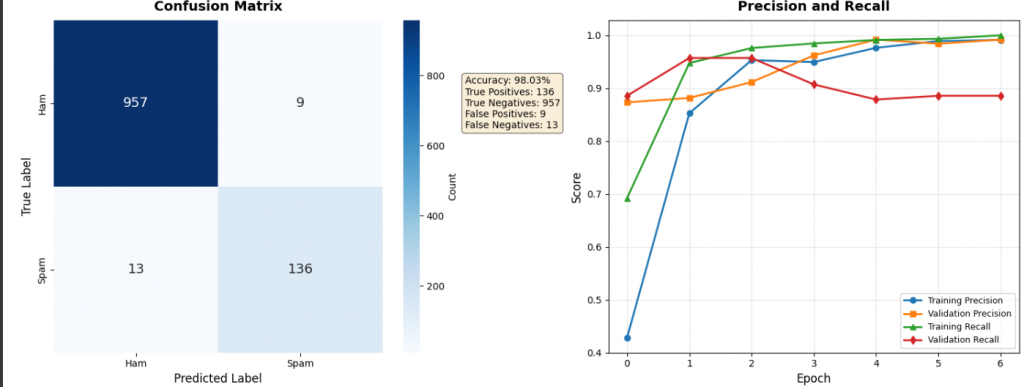
第三張圖是「混淆矩陣」,這個名字聽起來很學術(高中數學的死穴深深刻在我腦子裡),
但講起來其實不到那麼複雜。
它是一個 2x2 的表格,
對角線是正確預測(True Positives 和 True Negatives),
非對角線是錯誤(False Positives 和 False Negatives)。
如果是在理想情況下,對角線的數字會最大。
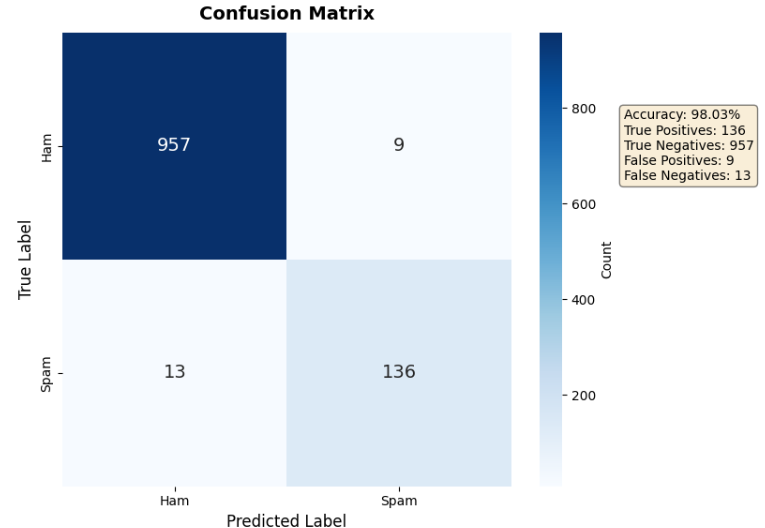
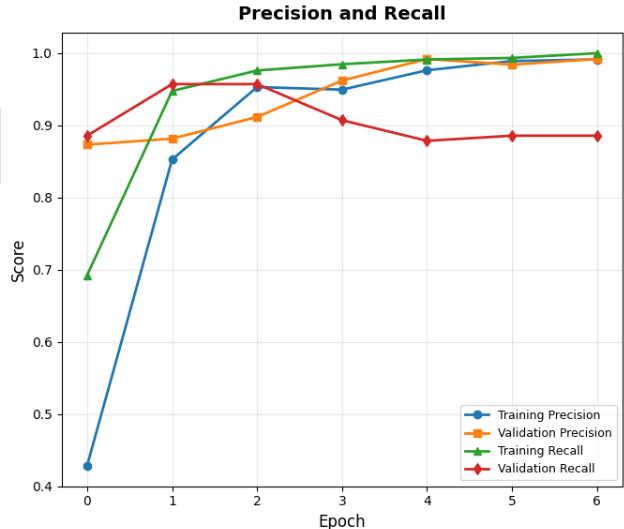
第四張圖是「精確率和召回率曲線」。
這張圖顯示模型在訓練過程中,這兩個指標如何變化。
你可能會看到一開始召回率比較低(只有 70%),但很快就提升到接近 100%。
這就表示模型一開始很保守,不敢亂判,後來越來越有自信,也能抓到更多垃圾郵件。
而上面講到的這四張圖合起來,就像是給模型做全身健康檢查,從各個角度評估它的表現。
print("\n[Step 9] Testing with practical examples...")
def predict_spam(text):
"""預測單一文本是否為垃圾郵件"""
text_vec = vectorize_layer([text])
prediction = model.predict(text_vec, verbose=0)[0][0]
label = "SPAM" if prediction > 0.5 else "HAM"
confidence = prediction if prediction > 0.5 else (1 - prediction)
return label, prediction, confidence
# 測試範例
test_messages = [
"Congratulations! You've won a $1000 gift card. Click here to claim now!",
"Hey, are we still meeting for lunch tomorrow?",
"FREE entry to win £1000! Text WIN to 12345",
"Can you pick up some milk on your way home?",
"URGENT! Your account will be suspended. Click link to verify",
"Thanks for the meeting today. Let's catch up next week."
]
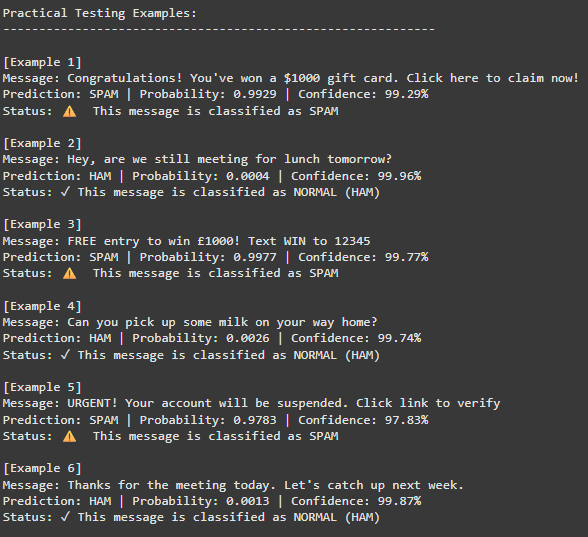
print("\nPractical Testing Examples:")
for i, msg in enumerate(test_messages, 1):
label, prob, confidence = predict_spam(msg)
print(f"\n[Example {i}]")
print(f"Message: {msg}")
print(f"Prediction: {label} | Probability: {prob:.4f} | Confidence: {confidence*100:.2f}%")
理論歸理論,但實際用起來怎麼樣才是重點。
在這裡我們寫了一個 predict_spam 函數,你輸入任何一段文字,
它就會告訴你:這是垃圾郵件嗎?有多少信心?
我覺得最有趣的是看它的判斷邏輯。
例如有垃圾郵件像「Congratulations! You've won a $1000 gift card」,
模型給出 99.29% 的信心說這是垃圾郵件,
為什麼它可以那麼肯定?
因為它學到了這些關鍵模式:誇張的獎勵、驚嘆號、金錢符號、要求點擊連結。
這些都是垃圾郵件的經典套路。
而正常訊息像「Hey, are we still meeting for lunch tomorrow?」,
模型給出 99.96% 的信心說這是正常郵件。
它知道這種疑問句、日常詞彙(lunch、tomorrow)、朋友間的語氣,都是正常對話的特徵。
print("\n[Step 10] Saving model...")
model.save('spam_classifier_model.keras')
print("Model saved successfully as 'spam_classifier_model.keras'")
vocab = vectorize_layer.get_vocabulary()
with open('vocabulary.txt', 'w', encoding='utf-8') as f:
for word in vocab:
f.write(f"{word}\n")
print("Vocabulary saved as 'vocabulary.txt'")
print("\n" + "=" * 60)
print("ALL STEPS COMPLETED SUCCESSFULLY!")
print("=" * 60)
我們用 .keras 格式儲存模型,這是 TensorFlow 推薦的新格式。
這個檔案包含了模型的「設計圖」(有哪些層、怎麼連接)和「訓練成果」(每個神經元的權重)。
以後只要用一行指令 load_model,就能把這個訓練好的模型叫回來用。
另外我們還儲存了詞彙表。
為什麼?因為新的文字進來時,要用同一套「翻譯規則」。
如果訓練時「free」是 245 號,預測時突然變成 567 號,那就亂套了,
所以詞彙表也要一起保存。
程式碼講解完畢,接著就是看成果的時間啦!
上圖就是我們視覺化所呈現出來的資料啦!
接著我們也看看測試範例呈現的結果:
準確率還不錯!(順帶一提,其實我測試了快10次才有這個數據,挺頭疼...)
以及最後還有訓練摘要:
以下就來對這次實作做個成果發表:
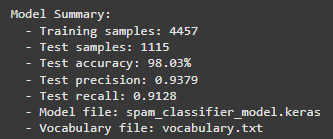
這個模型的表現非常出色,在 1,115 個測試樣本中達到 98.03% 的準確率,
也就是說每 100 封郵件只會判斷錯 2 封。
精確率 93.79%:模型說是垃圾郵件的,有 93.79% 真的是垃圾郵件。
換句話說,100 封被標記為垃圾的郵件中,大約有 6 封其實是正常郵件(誤判)。
召回率 91.28%:在所有真正的垃圾郵件中,模型成功抓到了 91.28%。
意思是每 100 封垃圾郵件,會漏掉大約 9 封。
雖然不是 100% 完美,但已經能過濾掉絕大多數垃圾郵件。
從混淆矩陣可以看到具體數字:
-957 封正常郵件被正確識別:模型對正常郵件的判斷很準確
-136 封垃圾郵件被成功攔截:在 149 封真實垃圾郵件中抓到了 136 封
-只有 9 封正常郵件被誤判:誤判率很低,不到 1%
-漏掉 13 封垃圾郵件:這是主要的改進空間
從訓練曲線可以看到,模型在第一個 epoch 後就快速進步,
從 84% 的準確率跳到 97%,之後穩定提升到 98%。損失值也持續下降,
訓練和驗證曲線保持接近,證明模型沒有過擬合問題。
精確率和召回率的曲線顯示,模型一開始比較保守(召回率只有 70%),
而隨著訓練逐漸變得更有信心,最終兩個指標都接近 100%。
6 個實際測試案例全部正確分類,且信心度都在 97% 以上:
- 3 封明顯的垃圾郵件(中獎通知、免費獎金、帳號警告)都被正確識別,信心度 97.83%-99.77%
- 3 封正常對話(約午餐、買東西、會議後續)都被正確放行,信心度 99.74%-99.96%
我覺得這份模型所交出的成績單我自己還蠻滿意的,很久沒有看到準確率這麼高的模型數據了,
雖然小缺點是還會漏掉約 9% 的垃圾郵件,聽起來還是挺多的,但考慮到我只用了 4,457 個訓練樣本,
這個結果我認為相當不錯了。(很主觀,說不定還可以更好)
以上就是我對於「垃圾郵件分類」實戰學習的全過程啦!
這次雖然說表面上看起來只是兩天的文章內容,
但我實際上大概也做了5-6天吧,從一開始發生過擬合,驗證準確率一直掉,
到後來數據雖然不好看但訓練區試是我要的,
再到最後可以呈現出準確率98%的模型,
實在是沒有很容易...
不過透過學習,我也對這種訓練模型的作品更有心得了,
之後應該還會有陸續幾個實作,
最後幾篇,還請大家繼續支持!!!

