在現代的許多企業中,客服每天都會處理成千上萬條訊息,
但這些問題往往非常相似,例如:
「我忘記密碼了」
「可以退貨嗎?」
「我的包裹寄到了嗎?」
「太陽餅裡面有太陽嗎」
「冷凍的魚可以放生嗎?」
如果在傳統上,這些訊息就需要人工閱讀與判斷,再手動轉交到不同部門做分類。
但這樣不僅浪費人力,也會很容易發生問題,被老闆罵臭頭。
而如果能讓電腦自動判斷每個問題的「類別」,
例如「帳號問題」、「退貨問題」、「出貨查詢」、「白癡問題」等等,
那麼客服系統就能自動分配工單,大幅提升效率。
這就是今天的主題:「客服常見問題自動分類系統」。
我們將用 自然語言處理(NLP) 技術訓練一個模型,
讓它能「讀懂問題的意思」並自動判斷該屬於哪個分類。
那就讓我們直接開始吧!!!
問題分類(Question Classification 或 Intent Detection)是 NLP 的一個經典任務。
它的目標是讓電腦理解「使用者想做什麼」,
並幫助系統做出正確回應。
我也用chatGPT幫我生成了一個解釋的表格,讓大家可以看得更明白:

當我可以妥善使用這種分類後就可以幫助像是
「客服系統自動將問題分配給不同部門」
「商業分析系統統計各類問題比例」等等問題,
讓效率提高的同時辦事更輕鬆。
參考資料:
https://research.aimultiple.com/intent-classification/
一般來說,要讓模型學會分類,必須先收集大量訓練資料。
但現實中,我們常常沒有足夠的客服資料集可用。
這時候就可以使用 Zero-Shot Learning(零樣本學習) 。
它的概念是:
「即使模型沒看過這個任務的訓練資料,也能根據語意去推測最合理的分類」
因此我們只要提供一些「候選類別」標籤,
模型就能利用語言理解能力去預測哪一類最符合,
減少我們收集資料的時間。
過去我們可能使用 BERT 或 DistilBERT 進行情感或分類任務,但這些模型多以英文為主。
而客服訊息往往是「中英夾雜」或多語言的,例如:「我想退貨,Please help me!」之類的。
這時候,傳統英文模型的表現就會不理想。
而我們今天要使用的 XLM-R(XLM-RoBERTa) 是由 Facebook AI 提出的多語言預訓練模型,
就支援超過 100 種語言,其中就包含中文,同時也保留了 RoBERTa 的強大語言理解能力。
因此它在跨語言任務(如情感分析、文本分類、翻譯對齊)上表現相當優異,
也是我們今天選擇它的原因。
以下是完整的 Colab 實作版本,使用的是
Hugging Face Transformers 提供的 pipeline() 工具,
而這一版本我們就會使用剛剛說到的 XLM-R 基礎模型,
並且讓它可以在 Colab 環境直接執行。
接著我們就直接來看程式碼吧!!
# 安裝套件(只需在第一次執行時執行)
!pip install transformers torch --quiet
# 匯入 pipeline
from transformers import pipeline
# 使用多語言的 XLM-R 模型進行 Zero-shot Classification
classifier = pipeline("zero-shot-classification", model="joeddav/xlm-roberta-large-xnli")
# 定義候選分類標籤
candidate_labels = ["退款問題", "帳號問題", "商品問題", "服務問題"]
# 測試輸入文本
texts = [
"我想退貨,請問流程是什麼?",
"我登入帳號一直顯示錯誤。",
"客服都沒回覆我,太誇張了!",
"這件衣服收到時破掉了。"
]
# 執行分類
for t in texts:
result = classifier(t, candidate_labels)
print(f"問題:{t}")
print(f"預測分類:{result['labels'][0]}(信心分數:{round(result['scores'][0], 3)})\n")
針對這段程式我想主要可以介紹幾個大重點:
在這一行中,它會自動幫你載入 XLM-R 模型與對應的 tokenizer,
並建立一個「零樣本分類」任務環境,達到減少收集資料的需求。
而在這段程式碼中,我們則是去手動定義可能的客服類別,
例如像是退款、帳號、商品、服務等等。
而模型就會根據語意去判斷哪一個最接近輸入內容。
而最後這段,其實才是這份程式碼的核心:
模型會對每一句話與所有標籤做「語意比對」,計算出每個標籤的相似度分數。
如此我們就可以透過相似度分數來判斷它的信心程度,以此來看看他是不是分對了。
最後,我們就來看看輸出的結果:
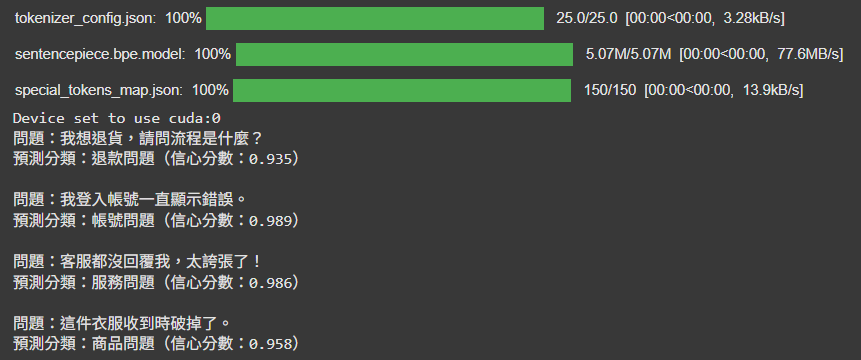
可以看到信心程度都達到了至少93%,實際驗證後的答案也都沒有錯,
代表我們今天的實作,大.成.功!
以上就是今天的內容了,明日會繼續帶來程式內容,敬請期待。

