昨天我們已經在 Google Colab 準備好環境,
今天就要正式踏出深度學習的第一步 - 認識 「張量」 (Tensor)。
很多人第一次聽到這個詞都會覺得很抽象,甚至會想:「這東西我真的懂得了嗎?」,
這東西聽起來又要勾起大家高中數學不好的回憶了...
但其實不用害怕,張量大概的意思其實是 「資料在電腦裡的表現形式」 。
可以把它想像成表格或 Excel 裡的資料,只是形狀不同而已。
下面就來稍微介紹一下什麼是「張量」吧。
張量(Tensor)這個詞聽起來很專業,但其實背後的意思並非大家想的複雜。
可以把它想像成 「裝數字的盒子」 ,
這個盒子可以是一顆小球、一條線、一張表,甚至是一個立體方塊,
差別就在於它能裝多少層數字。
我們先來根據不同的維度介紹一下他們的名詞:
0 維(Scalar,純量) :
就像一顆小球,裡面只有一個數字,例如 7。
1 維(Vector,向量) :
把很多小球排成一條線,就變成一組數字,例如 [1, 2, 3]。
2 維(Matrix,矩陣) :
如果把這些數字排成一張表格,就變成像 Excel 的表,例如: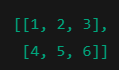
3 維以上(Tensor,張量) :
想像一下,把很多張表格一疊一疊疊起來,變成立體的方塊。
這時候它就叫做 「張量」 。如果再多疊幾層,就是 4 維、5 維,一直往上加。
所以根據我們上方的描述,你可以這樣記:
張量就是一種 「數字的集合」 ,形狀可能是一顆球、一條線、一張表,甚至是一個方塊。
而在深度學習中,所有資料最後都會變成張量:
舉例來說: 一張圖片就是一個三維的張量(高 × 寬 × 顏色)。
一段文字也會變成數字序列,組成張量。
甚至 Excel 裡的行銷數據,也能轉成向量或矩陣,交給 AI 使用。
在開始前,我們先來說清楚 NumPy 是什麼:
NumPy 這個名字來自 Numerical Python,也就是「數值運算的 Python」。
它是一個專門幫 Python 處理數學計算的函式庫。
就像平常我們在 Excel 裡面可能會用加總、平均或矩陣公式一樣,
NumPy 就是給 Python 一整套更快、更方便的 「數學工具包」 。
NumPy 最厲害的地方在於,它處理大量數字的效率非常高。
因為 NumPy 背後其實是用 C 語言實作的,
換句話說,它在運算時比單純用 Python 內建功能快很多。
如果你要操作一個幾千乘幾千的矩陣,
用 Python 內建的 list 來跑,可能會慢到讓你懷疑人生,
但如果用 NumPy,只要一行程式就能瞬間完成。
參考資料:
https://zh.wikipedia.org/zh-tw/NumPy
那為什麼在學深度學習的第一步,我們要用 NumPy 呢?
原因主要有以下幾點:
深度學習裡所有的模型,最後都是在處理矩陣和向量的運算。
NumPy 就像是一個訓練場,你可以先用它來熟悉加法、乘法、轉置這些基本操作,
這樣等你進入 TensorFlow 或 PyTorch 這些框架時,就不會一頭霧水。
如果你要自己寫程式去處理數字,不僅麻煩而且速度慢;
但用 NumPy 只要一行程式碼就能完成,而且執行速度非常快。
這讓我們可以更專心在理解 AI 的邏輯,而不是被程式細節卡住。
NumPy 幾乎是所有資料科學與 AI 函式庫的基礎。
像 Pandas(資料處理)、Matplotlib(繪圖)、
甚至 TensorFlow 和 PyTorch,底層都是靠 NumPy 來進行數值運算。
也就是說,你現在學會了 NumPy,等於在未來學其他工具時,已經打好基礎。
在 Colab 新建一個 Notebook,然後輸入以下程式碼:
import numpy as np
# 0 維:純量
scalar = np.array(7)
print("Scalar:", scalar)
print("Shape:", scalar.shape)
# 1 維:向量
vector = np.array([1, 2, 3])
print("\nVector:", vector)
print("Shape:", vector.shape)
# 2 維:矩陣
matrix = np.array([[1, 2, 3], [4, 5, 6]])
print("\nMatrix:\n", matrix)
print("Shape:", matrix.shape)
# 3 維:張量
tensor = np.array([[[1, 2], [3, 4]], [[5, 6], [7, 8]]])
print("\nTensor:\n", tensor)
print("Shape:", tensor.shape)
你會看到執行的結果如圖:
而這個結果中的 「Shape」 就是張量的形狀,來描述它的維度。
也許你會問:張量這麼數學化的東西,和職場有什麼關係?
但其實他可以運用在很多不一樣的地方,以下我就來舉幾個例子:
在行銷分析裡,一份顧客的資料(年齡、收入、購買紀錄),
其實就是一個向量;
而在客服領域,一段文字(例如顧客留言)也會被轉換成詞向量(Word Embedding),
這也是一種張量;
最後在製造業中,產品拍攝下來的影像,
其實就是一個三維張量: 高度 × 寬度 × 顏色 。
所以當你看過這些例子後你會發現,其實你每天看到的數據,背後其實都能用張量來表示。
到這裡,我們就已經成功邁出了深度學習的第一步 - 了解張量。
未來我們要訓練的模型,大部分處理的就是這些張量資料。
掌握好它,離成功學習AI就又向前了一大步。

