資料只是素材,知識才是品牌的靈魂。
在前面幾天,我們學會了透過爬蟲、RSS 等方式,把資料從網路上抓下來,變成我們可以操作的資料流。
但對於做內容行銷、社群經營的人來說,還有另一件更重要的事,讓 AI 說話時,能保有我們的品牌特性,而不是像在網路上隨便找答案。
這時候,「知識庫(Knowledge Base)」 就登場了。
本篇的工作流範本可在此下載。(下載連結)
你可以想像它像 NotebookLM 這種工具一樣,先讓 AI 讀過你上傳的文章、教學、品牌內容,之後 AI 就會根據這些資料來回答問題或生成內容,而不是胡亂回答。
不過也有人會好奇:
「那 AI 要一直讀整份資料嗎?這樣不是會超慢又很花費?」
其實不用。這裡會用到一個叫 「嵌入式模型(Embedding Model)」 和 **「向量資料庫(Vector Database)」**的概念:
今天這篇,我們會把資料轉成向量資料,做出專屬知識庫;
明天(Day 23)才會教你如何使用這個知識庫來生成內容。
雖然前面教過用爬蟲收集資料,但這次我們改用更輕鬆的方法:RSS
RSS 是什麼?
RSS 是一種可以訂閱網站更新的格式。
例如 iThome 提供我們這一系列文章的 RSS,我們可以輕鬆抓到全部文章的內容。
操作步驟
https://ithelp.ithome.com.tw/rss/series/8470
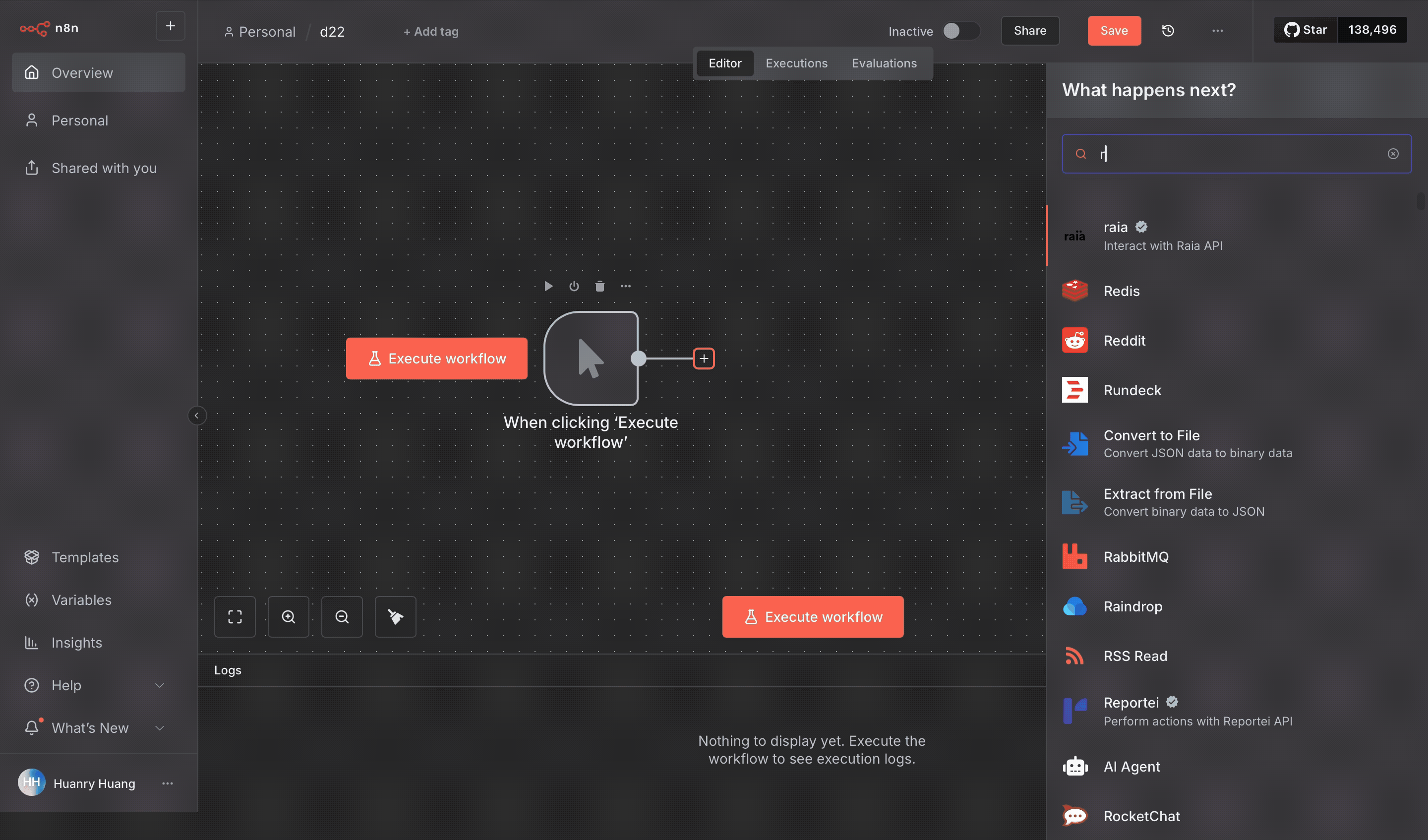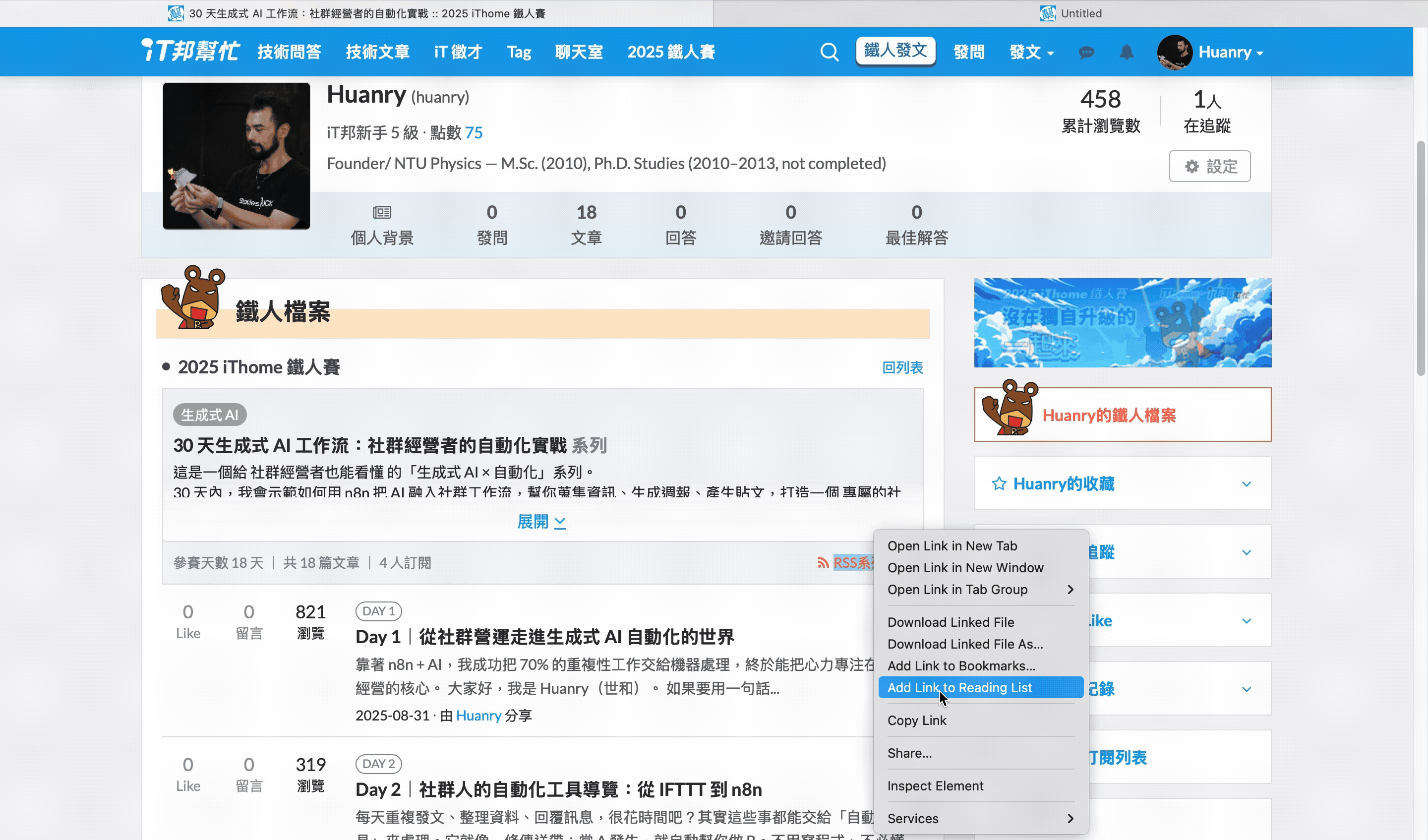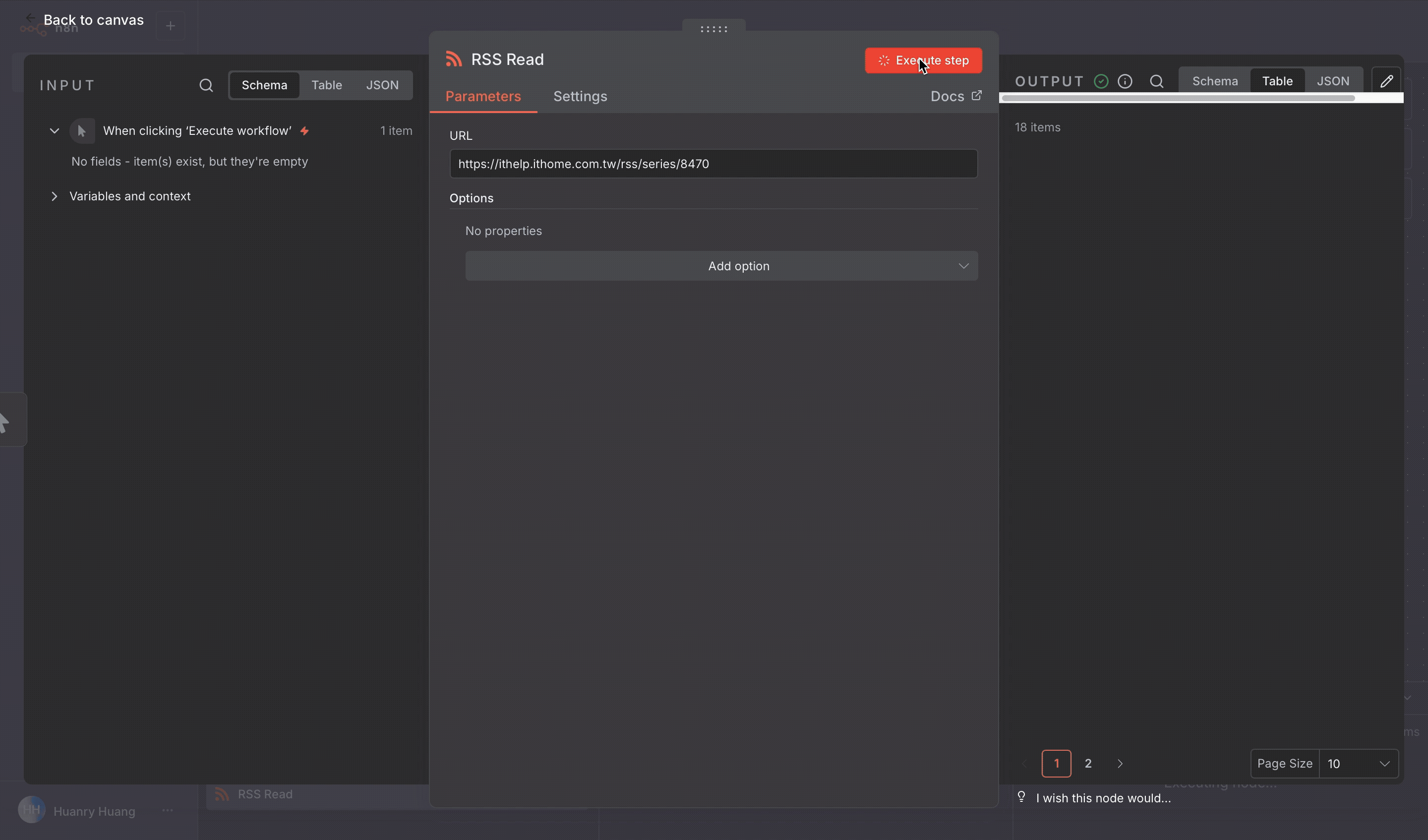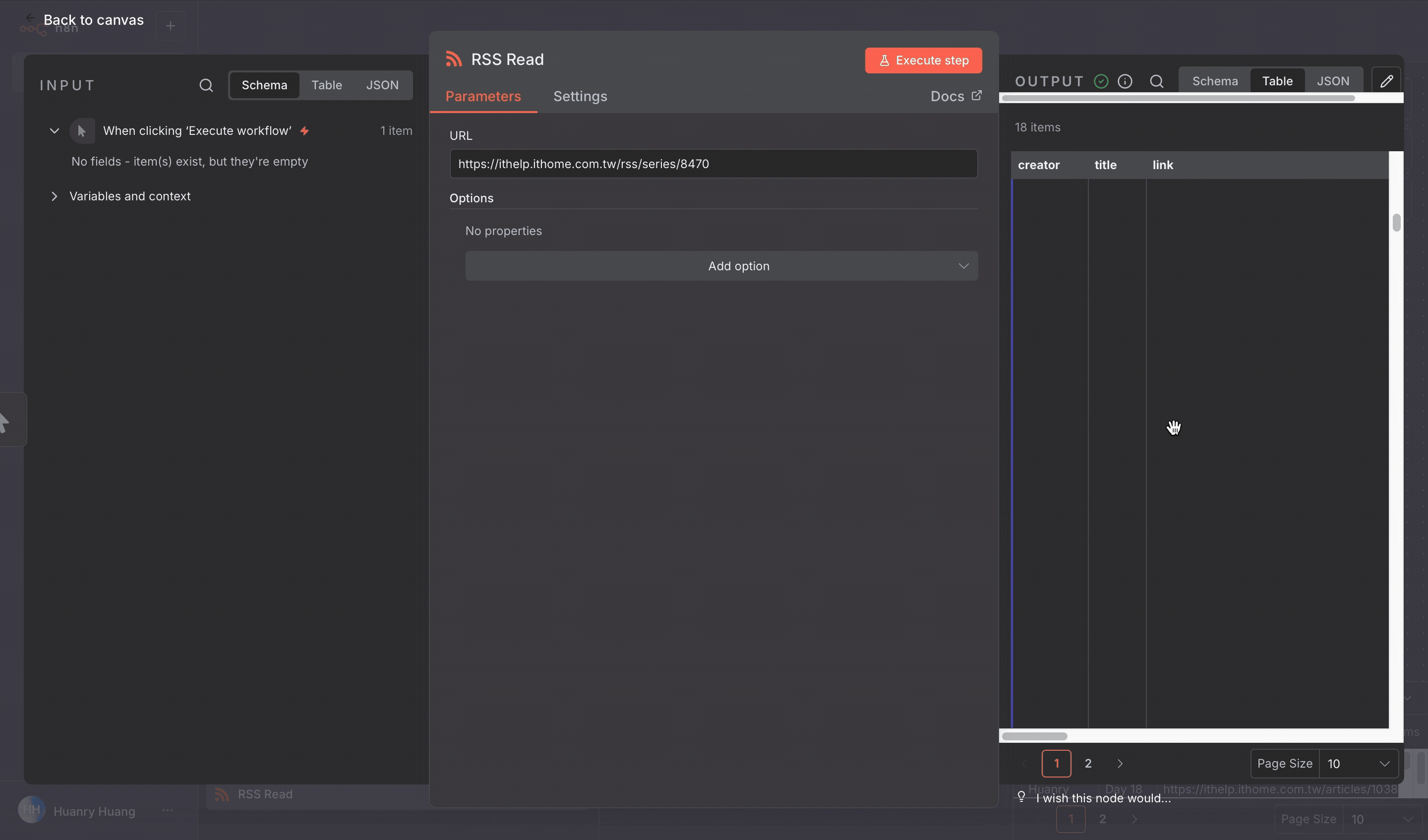
data
title, link, content:encodedSnippet
執行後,我們就會得到一筆包含所有文章資料的 JSON,可以準備送進向量資料庫了。
有很多種向量資料庫可以選,我們用之前 Day 5 安裝過的 Supabase,因為它內建支援向量儲存,非常適合入門。
Insert Documents(代表要把資料存進向量資料庫)models/text-embedding-004,其向量維度是 768JSON
Load All Input Data
還沒建資料表,資料是無法存進去的,要先在 Supabase 建好。
vector(1536),這代表它預期你用的是 1536 維度的模型(例如 OpenAI 的 embedding)
1536 改成 768
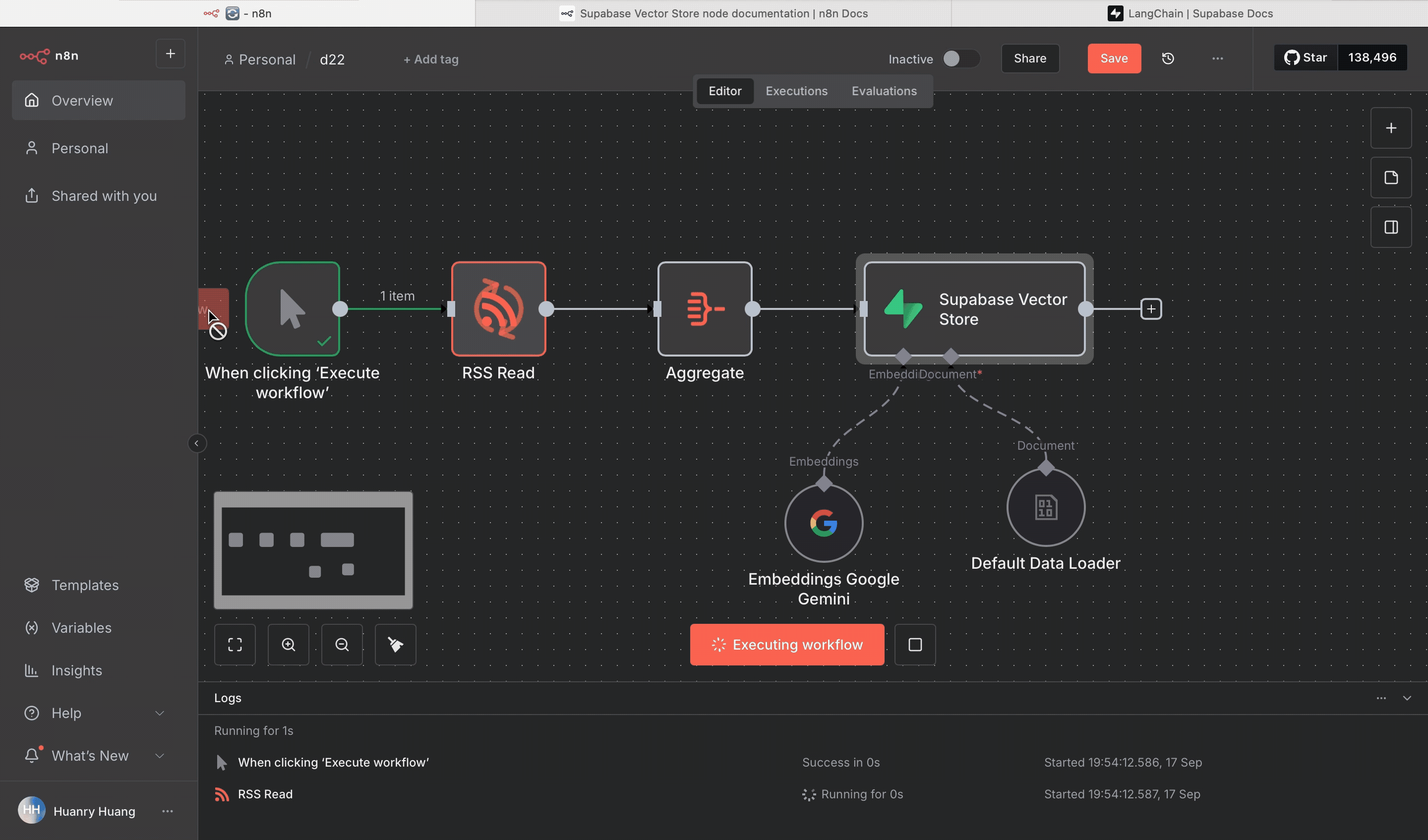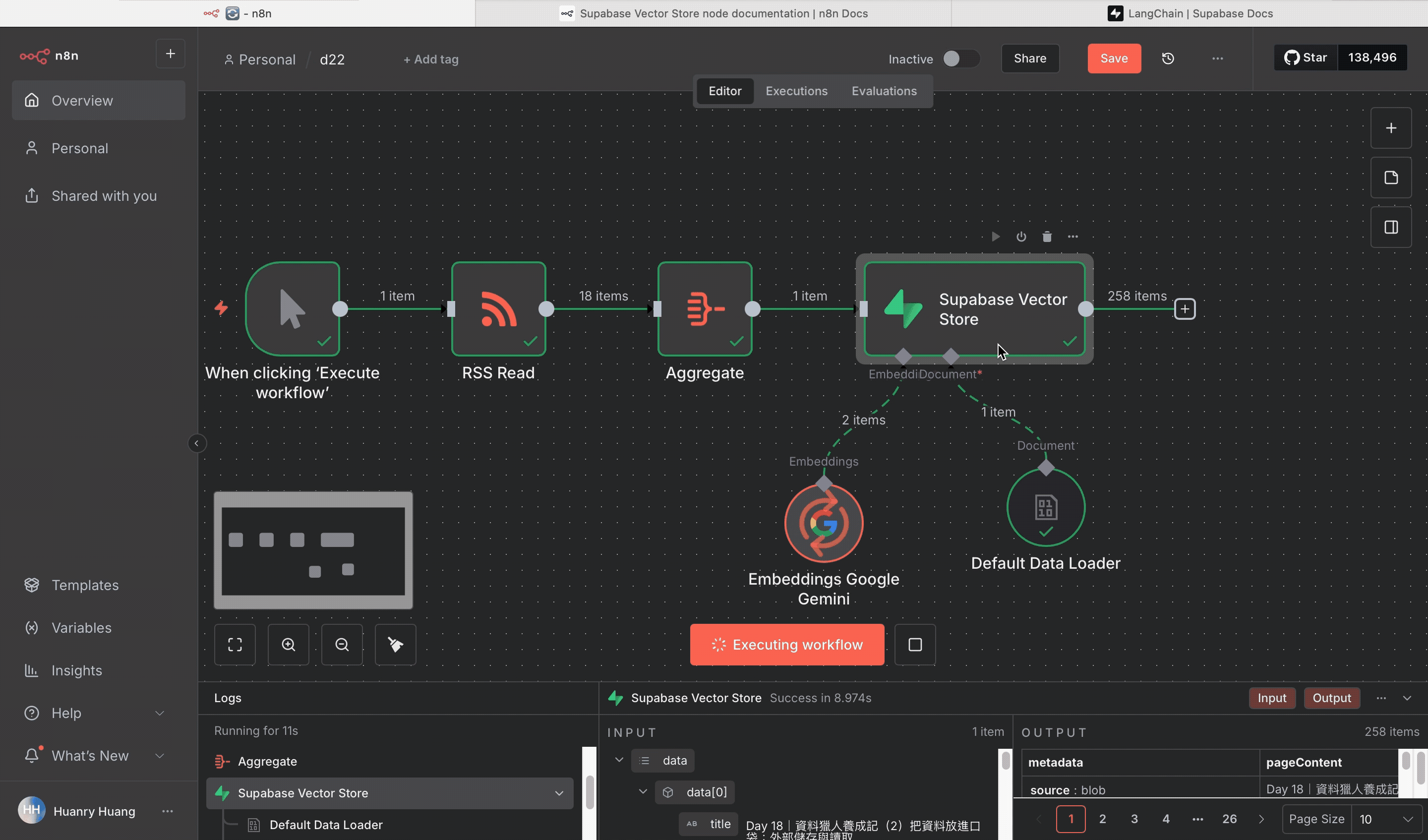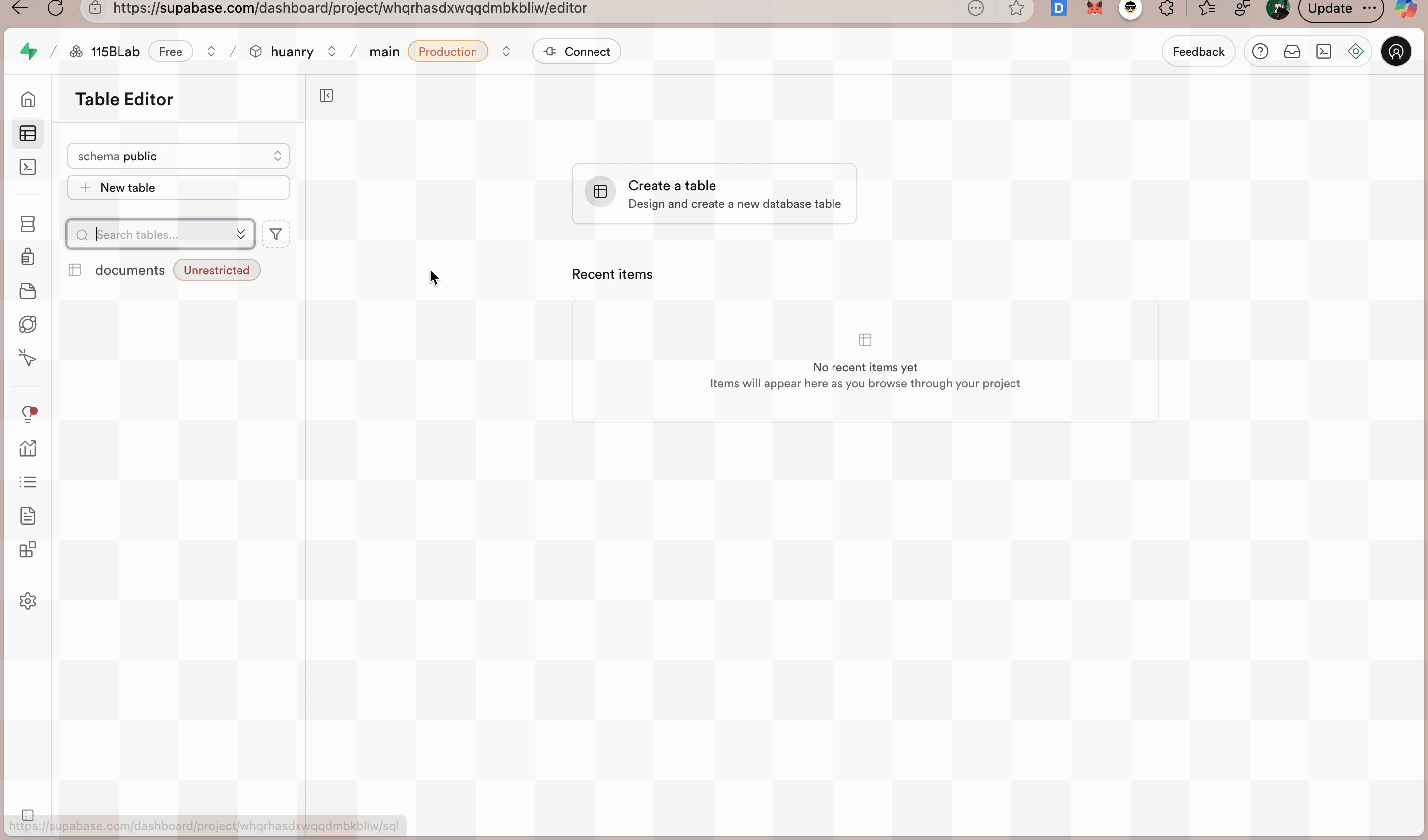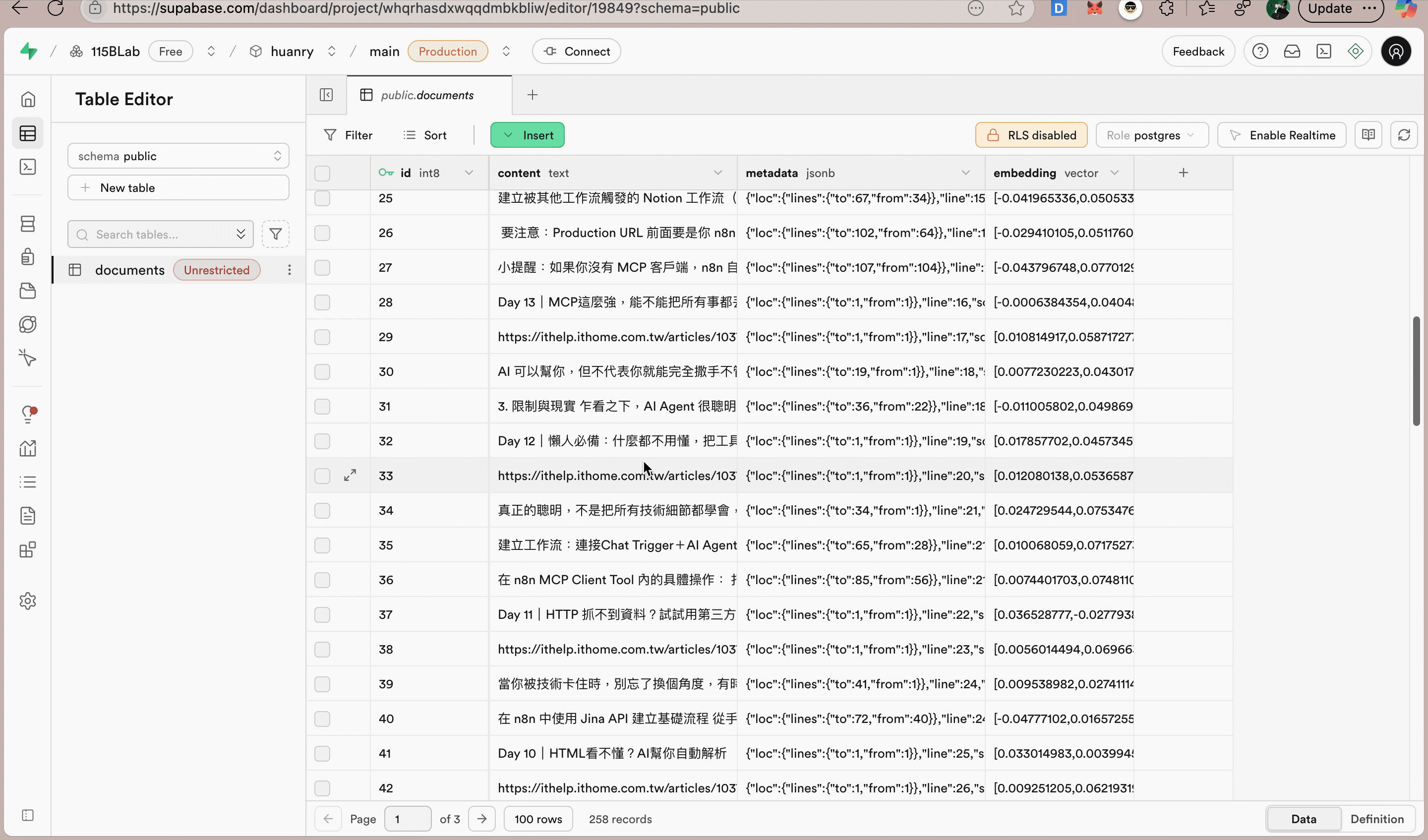
現在回到 n8n,執行整個工作流,
你就會看到所有 RSS 資料被轉換成向量資料,存進 Supabase 的資料表裡。
可以到 Supabase 的「Table Editor」中查看 documents 表,就會看到每篇文章的向量資料都在那裡。
我建立了一個行銷技術交流群,專注討論 SEO、行銷自動化等主題,歡迎有興趣的朋友一起加入交流。
掃QR Code 或點擊圖片加入


