
PG 也是用 MVCC 實作 Isolation 機制,但卻沒有像 MySQL 的 Undo Log 結構。
不像 MySQL UPDATE 資料是用覆蓋的方式,PG 是新增新版本資料到 Heap 中,因此 PG 不用 Undo Log 結構儲存 Rollback 資訊,而是直接把不同版本的完整資料儲存在資料庫裡。
雖然UPDATE 直接寫新版資料,少了查詢原有位置的 I/O,寫入效能較好,但也因此查詢 id=1 資料會發現不同版本的多筆資料。
PG 每筆資料會有兩個 system 隱藏欄位:
DELETE,而是指 Transaction 執行 UPDATE 會將舊版資料變無效,如果 xmax 等於 0 代表這筆資料不是無效。CREATE TABLE test (
id int primary key,
a int,
b int
);
INSERT INTO test (id, a, b) VALUES (1, 1, 1);
SELECT xmin, xmax, ctid, * FROM test WHERE id = 1;
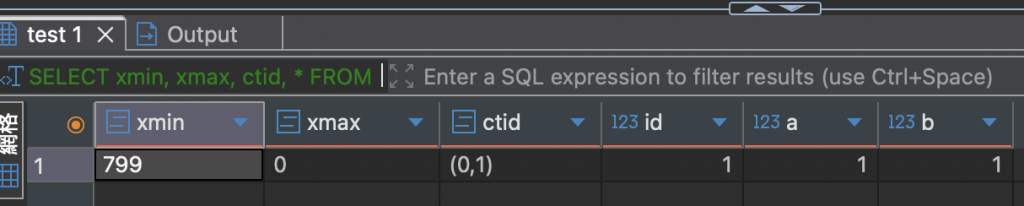
(作者產圖)
UPDATE test SET a=2, b=2 WHERE id = 1;
SELECT xmin, xmax, ctid, * FROM test WHERE id = 1;

(作者產圖)
更新後會發現 ctid & xmin 都會改變。
使用 pageinspect 插件實際觀察 page 中的資料會發現有兩筆紀錄:
create extension pageinspect;
SELECT * FROM heap_page_items(get_raw_page('test', 0));

(作者產圖)
Transaction 未 Commit 的 UPDATE 也會寫入 Heap 並更新 xmax,如果 Rollback UPDATE xmax 不會歸 0,而是標記狀態為 Abort,避免還要回去更新受影響的資料:
BEGIN;
UPDATE test SET a=3, b=3 WHERE id = 1;
ROLLBACK;
SELECT xmin, xmax, ctid, * FROM test WHERE id = 1;
SELECT txid_status('801');

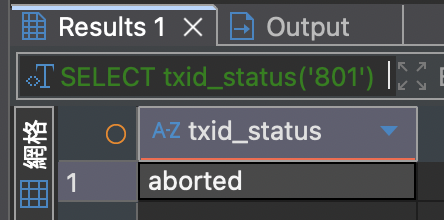
(作者產圖)
PG MVCC 機制在選擇可讀版本時,會先建立 Snapshot object :
資料量會放大,不像 MySQL Undo Log 只儲存 Rollback 用的部分資料,PG 即便 UPDATE 一個欄位也會複製整個資料,且資料物理位置 (CTID) 會變化, UPDATE 還會導致原本連續插入的資料會散落到不同 Page,範圍查詢就變成隨機 I/O。
更新 tuple CTID 會變動,就要同步更新其他 Index 結構,避免 Index Leaf Node 只能找到舊版資料,因此即便更新欄位跟 Index 值無關,都需要更新 Index 內容,更新 I/O 也變多,且 Index 更新方式也是新增一個 CTID 不覆蓋舊 CTID,Index 資料量也會變大。
由於 xmin & xmax 欄位儲存在 Heap 中的 Tuple,如果 SELECT name FROM users WHERE name = 'vic' name 有 Index Tree,即便在 Index Tree 就能找到資料,但為了判斷 name 值是否可見,還是要回到 Heap 找到 xmin & xmax 欄位,多一次 I/O。
不像 MySQL 是從最新版本資料透過 Undo Log Rollback 到前一個版本,大部分情況不用 Rollback 或只要一次就能找到可視版本,PG 要把所有版本 tuple 找出來執行可視判斷後選擇 xmax=0 資料,如果資料在不同 Page 會增加 I/O 次數,影響查詢效能。
為了減少資料量,PG 有 auto vacuum 功能,會定期在 background 清除無效 tuple,例如當 無效 tuple > autovacuum_vacuum_threshold + (autovacuum_vacuum_scale_factor × 表行數) 時觸發 vacuum。
vacuum 會 scan Heap 中所有 page 若 tuple 為無效且沒有被任何 alive transaction 使用,就標記可回收讓 Free Space Map 能分配這些空間給其他資料,此外當 vacuum 發現 page 中所有 tuple xmax=0 代表該 tuple 所有資料為可視,會在 Visibility Map 結構標記 page_no 為 all-visible ,下次 vacuum 會跳過 all-visible 的 page,可以減少 I/O,當其他寫入影響 Page all-visible flag 才會清除,。
另外 all-visible flag 還能幫助 Index 查詢,如果 SELECT name FROM users WHERE name = 'vic' Index Tree 的 Leaf Node (Page) 有 all-visible flag,就不用回 Heap 檢查可視,可直接回傳資料。
由於無效 tuple 只是標記可用,不會刪除空間,如果發現 table 佔用空間太多,或範圍查詢效能太差,可以手動執行 VACUUM FULL,會建立新檔案並重建資料,同時把連續資料放到相同 Page,舊檔案會刪除空間還給 OS,但 VACUUM FULL 會 Lock Table,auto vacuum 不會 Lock Table 卻會吃 CPU 。
最後為了優化 UPDATE 非 index 欄位還要去修改 Index 的問題,PG 使用 Heap-Only Tuple (HOT),會在 Heap 更新舊 ctid 資料,加上 t_ctid 指標關聯下一個版本的 ctid,建立 HOT Chain,當 index tree 查到舊的 ctid,可透過 HOT Chain 不斷前進並找到最新版資料。
但要觸發 HOT 有條件:
有了 HOT 不僅 UPDATE 能減少 I/O,也能避免在 Index Tree 中建立太多無效 ctid 資料,減緩 vacuum 的掃描壓力。

 iThome鐵人賽
iThome鐵人賽