
MySQL 跟 PostgreSQL (PG) 都是主流的關聯式資料庫,但在儲存結構他們卻選擇了不同的策略,MySQL 以 B+Tree 為主,PG 則用 Heap,但什麼是 Heap 結構,為什麼要用 Heap?
這裡的 Heap 並非 priority queue ,而是形容資料是用無序的結構隨意堆疊起來的:

(圖來源:https://andrewlock.net/an-introduction-to-the-heap-data-structure-and-dotnets-priority-queue/)
舉例來說,MySQL 用 B+Tree 儲存資料,建立資料時,需要 traversal tree 找到插入 Page,如果 Page 有空間就直接寫入,如果沒有要透過 Tablespace 的 extent 管理要一整塊 Page 空間,建立新節點後寫入資料。
而 PG 用 Heap 儲存資料,建立資料時,會透過 Free Space Map (FSM) 從多個 Page 中找到 Free Space 夠塞新資料的 Page,並將資料放進去,找不到合適 Page 就換建立新 Page 後把資料放進去。
因此,若建立多筆資料時,MySQL 的 B+Tree 會把 primary key 連續資料放進相同 Page,除非 Page 不夠塞才會分裂,但 PG 的 Heap 會依照 FSM 裡面 Page 的 Free Space 分佈選擇 Page,資料散落到不同 Page 機率更高。
而 FSM 結構是 Max Segment Tree,Leaf Node 是 Page,Non-Leaf Node 紀錄該區段 Page 中最大的 Free Space,如圖:
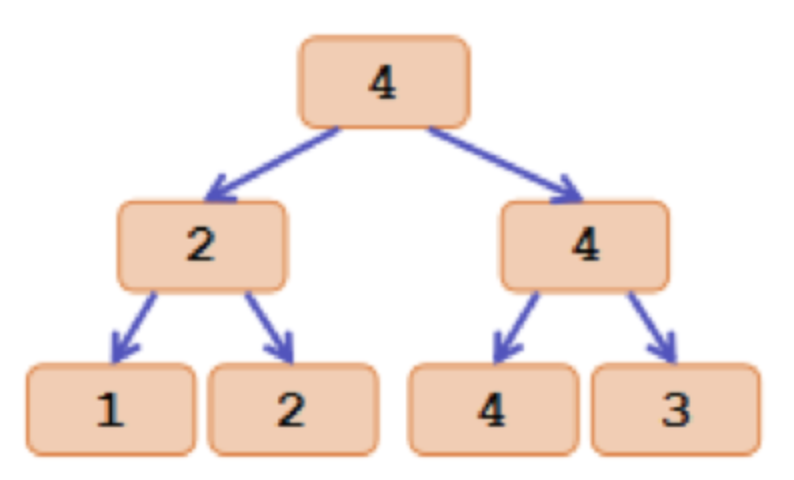
(圖來源:https://codeforces.com/blog/entry/62528)
透過 FSM 可用 O(logN) 時間複雜度找到 Free Space 最小但大於新資料 size 的 Page ,此外 PG 也此用 File Per Table 模式,每個 Table 有獨立的 FSM 管理 Page,如果建立資料是依照 primary key 有序建立,連續資料高機率會放到相同 Page 中。
如果建立資料 primary key 是無序的,MySQL 的 B+Tree 能保證連續資料在相同 Page,PG Heap 無法,但 MySQL 用無序資料塞入 B+Tree,任意 Page 都會觸發分裂,分裂變得頻繁,要多花 I/O 搬移資料,Page 空間利用率也會變差。
因此當 primary key 是無序的情況下,PG 的 Heap INSERT 效能更好,但是範圍查詢效能差,因為資料散落在不同 Page 增加隨機 I/O,而 MySQL 的 B+Tree INSERT 效能差,但是有序資料集中在相同 Page,範圍查詢效能好。
而 primar key 有序的情況下,MySQL 的 B+Tree 只有最右邊的 Node 會分裂,INSERT 不會差 PG 的 Heap 太多,而 PG 的 Heap 也高機率把連續資料都放在相同 Page,範圍查詢效能也不會比 MySQL 差太多。
資料儲存的 Page 雖然是 Heap 結構,但可用 B+Tree 建立 Primary key 的 Index Tree,但與 MySQL 的 Clustered Index & Secondary Index 不同的是,PG B+Tree 的 Leaf Node 是儲存 CTID。
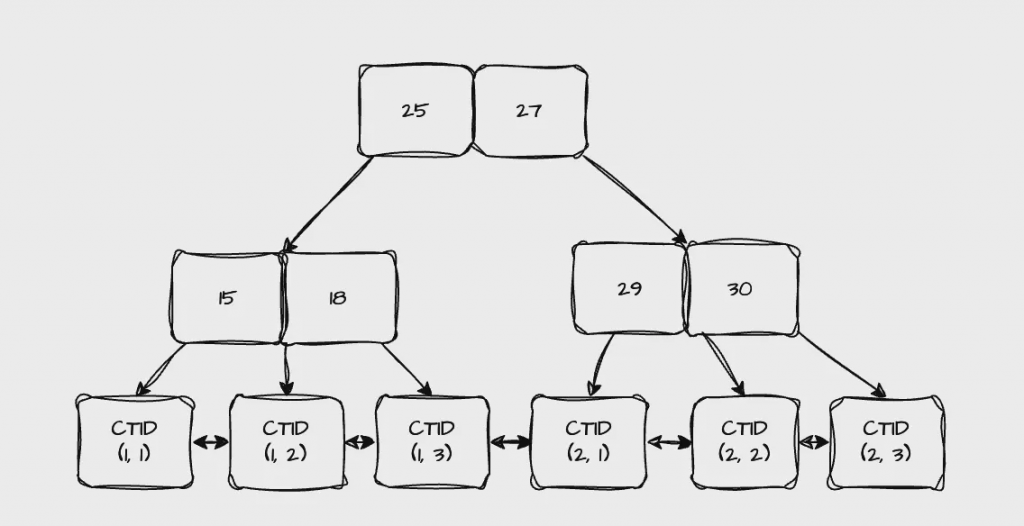
(作者產圖)
CTID 會紀錄資料的物理位置,例如 (page_no, tuple offset),tuple 為一筆完整資料,因此用 Primary Key 的 B+Tree,可在 O(logN) 時間複雜度內找到 CTID 後,直接從 Heap 定位 Page 找到資料。
用 CTID 好處是,不論是 Primary Key 還是其他欄位的 Index,Leaf Node 都是儲存 CTID,透過 Index 找到完整資料的時間複雜度都是 O(logN),反觀 MySQL 如果用非 Primary Key 的 Secondary Index 查完整資料,就會有 2 * logN 的複雜度跟更多的 I/O。
此外 PG 除了 B+Tree 結構的 Index 還支援 Hash Index & GIN (Inverted Index) 等多種索引結構,例如用 Hash Index 可用 O(1) 時間找到 CTID 跟完整資料 ,但即便 MySQL 支援 Hash Index ,也只能透過 O(1) 找到 primary key,還要另外用 O(logN) 找到完整資料,無法完全發揮 Hash Index 效能優化。
PG 的 Heap 不僅可搭配不同結構的 Index,且不同欄位 Index 也可較快找到完整資料。
雖然用 index 查詢完整資料不用兩次 O(logN),但範圍查詢時,連續資料可能散落在不同 Page ,導致回 Heap 查詢時,要在不同 Page 反覆跳躍查詢,效能較差。
為了解決該問題,PostgreSQL 使用 Bitmap Scan,會用兩層 map 結構暫存查詢命中的 page_no 跟 tuple offset,回 heap 查詢時會透過 map 結構一次從 page 中找出所有命中的 ctid 不會來回跳躍。
Bitmap Scan 用到的 map 分成兩種模式:
int64 來紀錄,例如 101 代表 page_no 0 & page_no 2 有命中。理論上用 bitmap 結構能節省很多空間,但若總 page 數量很大 (e.g 10w) 但命中的 page 不多,使用 bitmap 要一筆筆 (1 ~ 10w) 檢查有無命中,效能差,所以在稀疏模式下用 hash table 不會佔用太多空間查詢效能也較好。
CTID 會儲存 (page_no, tuple offset),page_no 實際上是整個 File 的 offset,例如 page 大小為 16 KB 且 page_no 為 3 就代表資料在 (32 KB, 48 KB] 區塊間。
那 tuple offset 是代表從 Page 起點開始移動多少 bytes 就能定位到資料嗎?
假設 Page 中有兩筆資料,前 100 bytes 是第一筆後 100 bytes 是第二筆 ([100 bytes | 100 bytes]),可以把第二筆資料的 tuple offset 設成 100,並搭配 page_no 就能快速找到資料,但如果第一筆資料長度有異動,這樣第二筆資料的 CTID 內容就要修改,且還要同步到所有 Index 中,會多很多寫入 I/O,效能太差了。
因此 tuple offset 實際是用來定位 Page 結構中的 Tuple Pointer Array 位置。
PG 的 Page 結構為:
|header|tuple pointer array|...|free space|data 2|data 1|tailer|
Tuple Pointer Array 是一個 Item 位置永不改變的陣列,Item Value 會儲存指向實際資料的 offset 指標,而 CTID 中的 tuple offset 是指向 tuple pointer array 的 Item,因此當 Page 中資料長度改變時,只要修改 Tuple Pointer Array 中 Item 的指摽內容,不會影響到其他資料的 CTID。
因此 PG 的 Page 寫入跟查詢效能基本上都是 O(1),寫入只要新增資料到 free space 和 append 新 item 到 Tuple Pointer Array,而查詢就是透過 ctid 中 tuple offset 找到 Tuple Pointer Array 中資料的 offest 就能定位到資料。
相反地,MySQL 的 Page 寫入跟查詢都要依賴 page directory 和有序的 Linked List,因此時間複雜度為 O(logN),但如果是順序查詢 MySQL Page 效能較好。

 iThome鐵人賽
iThome鐵人賽