昨天把簡單的 MoE 觀念介紹完了,主要就是三個部分專家, 門控, 選擇器。
參考文章 & 圖片來源
https://www.cnblogs.com/rossiXYZ/p/18800825
等下實作 block 分成三部分
會分成 training 跟 inference,主要是 inference 不用計算 loss,所以程式精簡很多,我們先從 inference code 看起。
先看一下整個流程圖,我們再依照流程一一講解
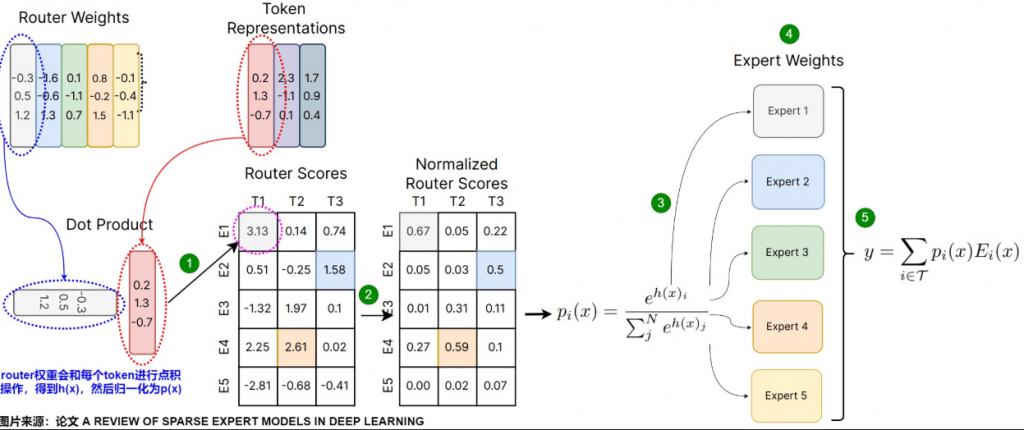
上圖對應的 pesudo code 如下

門控網路 (Gating Network)
門控網路負責將每個輸入的 token 選擇一個稀疏的專家組合,然後這些專家會參與到當前的計算當中。典型的門控網路如下,是一個帶有 softmax 函數的簡單網路。
x: 經過 nn.embedding 將 token 轉成 embedding
W: 門控權重 (可以用 nn.Parameter 或者 nn.Linear 不帶 bias)
G(x): 每個專家的機率分布
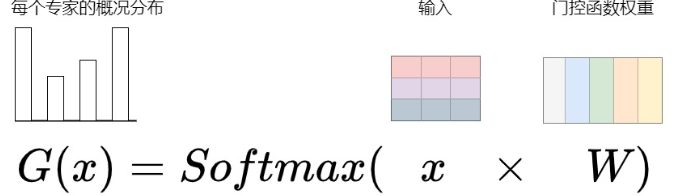
實際訓練會有 batch size,所以維度上操作如下
B: batch size
L: seq len
D: embedding dimension
程式片段如下
self.gate = nn.Linear(hidden_size, n_routed_experts, bias = False)
# step 1: 攤平
x_flat = x.view(-1, D)
# step 2: 透過 linear 計算 logits
logits = self.gate(x_flat)
# step 3: 利用 softmax 計算 scores
scores = F.softmax(logits, dim = -1)
top_k
然後我們會選取前 k 高的,比如說下圖藍色字的部分以及紅色字的"激活",選擇了前兩高的 Expert 2 跟 n-1,分數分別為 0.1 及 0.9 (加總起來為一,有經過 Normalize)。
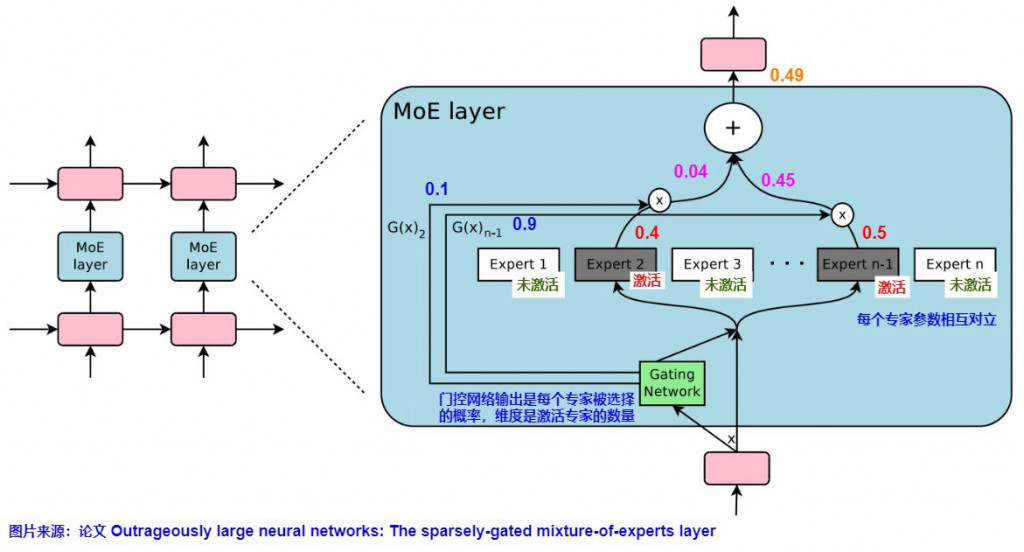
接續剛才的程式,流程及程式如下
4. 從剛才的 score 選取 top_k
5. Normalize 讓總和為 1
# step 4: 選取 top_k
topk_scores, topk_idx = torch.topk(scores, k = self.top_k, dim = -1)
# step 5: Normalize, 讓總和為 1
topk_scores = topk_scores / (topk_scores.sum(dim = -1, keepdim = True) + 1e-6)
return topk_scores, topk_idx
這裡也可先對 logits 取 top_k 然後再 softmax,這樣子就不用 step 5 了。
包含以下元素:
從 MoEGate 得到 topk_weight, topk_idx 之後,我們將接續 pesudo code 後 3 步
先給出跟才上面分步驟講解的 MoEGate 完整的 code
import torch
from torch import nn
import torch.nn.functional as F
class MoEGate(nn.Module):
def __init__(
self,
top_k,
hidden_size,
n_routed_experts
):
super().__init__()
self.top_k = top_k
self.gate = nn.Linear(hidden_size, n_routed_experts, bias = False)
def forward(self, x: torch.Tensor):
'''
x: (B, L, D)
'''
B, L, D = x.shape
# step 1: 攤平
x_flat = x.view(-1, D)
# step 2: 透過 linear 計算 logits
logits = self.gate(x_flat)
# step 3: 利用 softmax 計算 scores
scores = F.softmax(logits, dim = -1)
# step 4: 選取 top_k
topk_scores, topk_idx = torch.topk(scores, k = self.top_k, dim = -1)
# step 5: Normalize, 讓總和為 1
topk_scores = topk_scores / (topk_scores.sum(dim = -1, keepdim = True) + 1e-6)
return topk_scores, topk_idx
底下一樣分步驟給出 MoELayer
# step 1 + step 2
class MoELayer(nn.Module):
def __init__(
self,
top_k,
hidden_size,
n_routed_experts,
):
self.top_k = top_k
self.experts = nn.ModuleList(
[MyFFN(hidden_size, hidden_size * 4, "relu") for _ in range(n_routed_experts)]
)
self.gate = MoEGate(
top_k,
hidden_size,
n_routed_experts
)
def forward(self, x: torch.Tensor):
'''
x: (B, L, D)
'''
return
class MoELayer(nn.Module):
def __init__(
self,
top_k,
hidden_size,
n_routed_experts,
):
super().__init__()
self.top_k = top_k
self.experts = nn.ModuleList(
[MyFFN(hidden_size, hidden_size * 4, "relu") for _ in range(n_routed_experts)]
)
self.gate = MoEGate(
top_k,
hidden_size,
n_routed_experts
)
def forward(self, x: torch.Tensor):
'''
x: (B, L, D)
'''
B, L, D = x.shape
topk_scores, topk_idx = self.gate(x)
x_flat = x.view(-1, D)
# step 1: 初始化一個維度為 (B*L, D) 全為 0 的矩陣,用於儲存每個 expert 的輸出
y = torch.zeros_like(x_flat)
# step 2: 遍歷 top_k expert indices
for k in range(self.top_k):
expert_idx = topk_idx[:, k] # (B * L)
weight = topk_scores[:, k].unsqueeze(-1) # (B * L, 1)
for i, expert in enumerate(self.experts):
mask = (expert_idx == i) # 哪些 token 分配到 expert i
if mask.any():
expert_inputs = x_flat[mask]
print(f'top_k: {k} 選取了 {i} 號專家, 輸入維度為: {expert_inputs.shape}')
experts_outputs = expert(expert_inputs)
# step3 : 每次用 gating score 乘上該 expert 的輸出,加回到 y
y[mask] += weight[mask] * experts_outputs
return y.view(B, L, D)
if __name__ == "__main__":
import random
seed = 42
random.seed(seed)
torch.manual_seed(seed)
x = torch.rand(2, 20, 8)
model = MoELayer(2, 8, 4)
y = model(x)
執行之後可以看到每次送進 expert 做運算時的維度。

最後可以對應回 pesudo code
MoE 的部分跟之前的 mask 一樣,每個 github 實作起來都不太一樣,那我為了對應 pesudo code ,所以程式寫的長一些但比較易讀,不過沒有優化只是提供學習而已。
今天先到這裡囉~


 iThome鐵人賽
iThome鐵人賽