昨天我們已經將 GQA 分步驟實作完了,目前大部分 LLM 都是走這種架構,所以了解一下。
參考文章 & 圖片來源
https://www.cnblogs.com/rossiXYZ/p/18800825
https://zhuanlan.zhihu.com/p/18565423596
https://arxiv.org/pdf/2407.06204
https://arxiv.org/pdf/2503.07137
稀疏性: 只使用整個系統的某些特定部分來執行運算。這意味著並非所有參數都會在處理每個輸入時被啟動或使用,而是根據輸入的特定特徵或需求,只有部分相關參數集合被呼叫和運行。
那 FFN 相比 attention 有高度的稀疏性,主要是因為激活函數會導致大部分的激活值都是 0,底下來自於論文的數據,就知道 LLM 稀疏的比例其實蠻高的。

圖片來源: https://arxiv.org/pdf/2406.05955
不過想想也合理,假設問你一個簡單的問題,你就使用腦袋全部神經元要回答,那可能過沒多久就用腦過度燒壞了。
核心觀念: 術業有專攻
早在 1991 就有 MoE 的相關研究 Adaptive Mixtures of Local Experts,當中的架構圖包含三個部分:
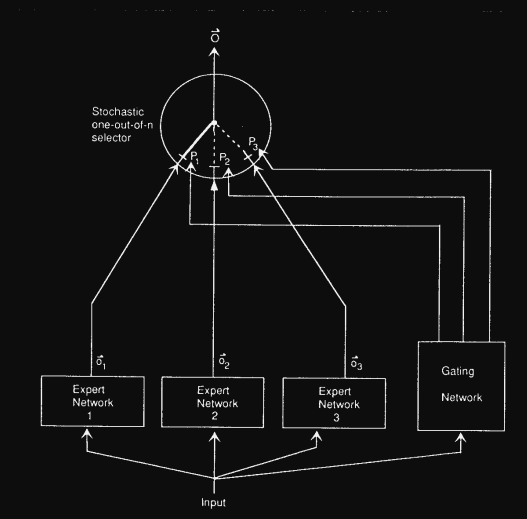
可以想像 MoE 就像公司要辦活動,分成不同專業的小組(experts),而 gating 就是領導者,會根據需求(輸入)決定派哪幾組來執行。這樣不需要每次所有人都出動,但又能確保找到最合適的人來處理任務。
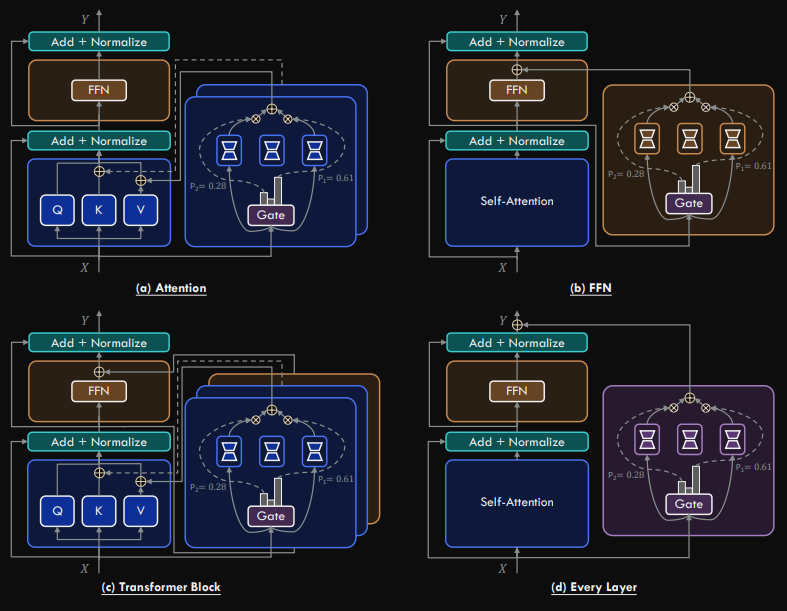
MoE(Mixture of Experts)理論上可以應用在 Transformer 的不同位置,例如 Attention 層、FFN 層、整個 Block,甚至是每一層。不過,目前主流做法大多集中在 FFN 層。原因在於:
我們先來看一下 deepseek-V3 的架構圖,用此來了解 MoE 我覺得蠻適合的。
這裡會分成幾個部分:
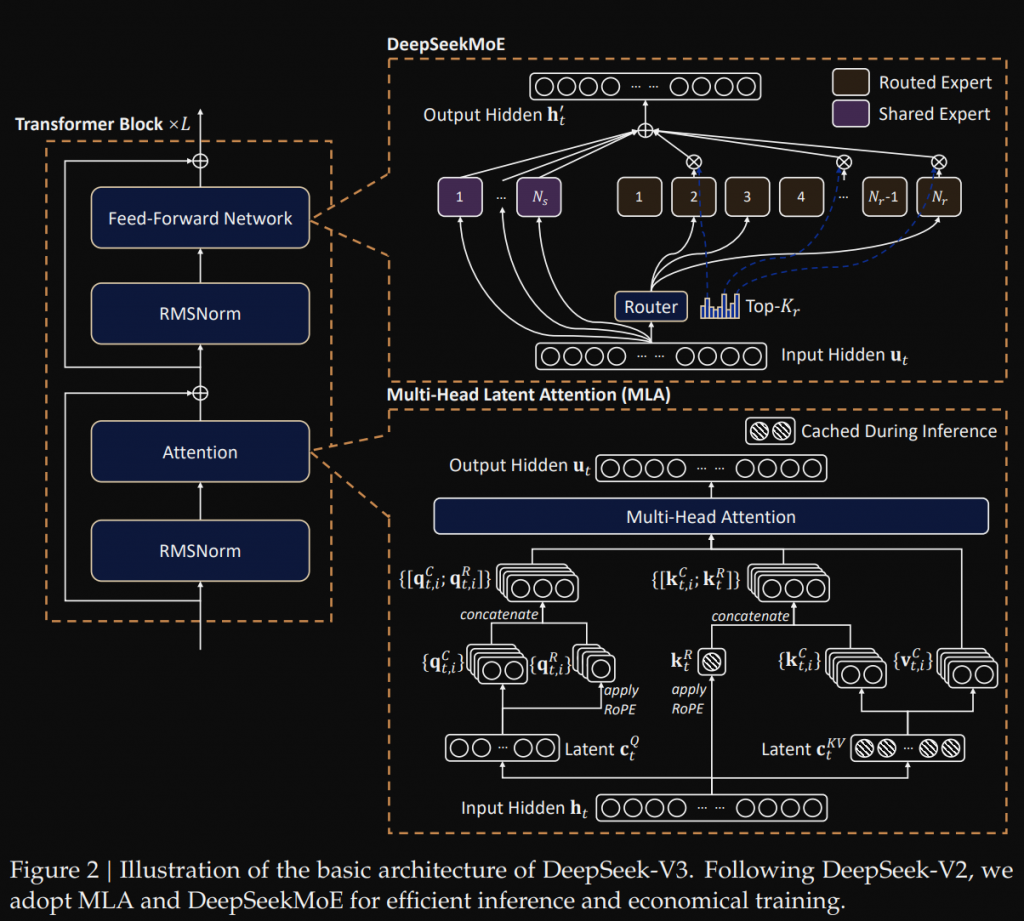
某些模型有 shared expert,有些單純只有 routed expert,我自己是這樣理解的,基本的語意訊息儲存在 shared expert 當中,然後搭配 routed expert 做更複雜的任務,不管是哪一個基本上都是由 FFN 所組成。
以下是整理幾個 MoE 的模型,他們當中的設定
論文統計:
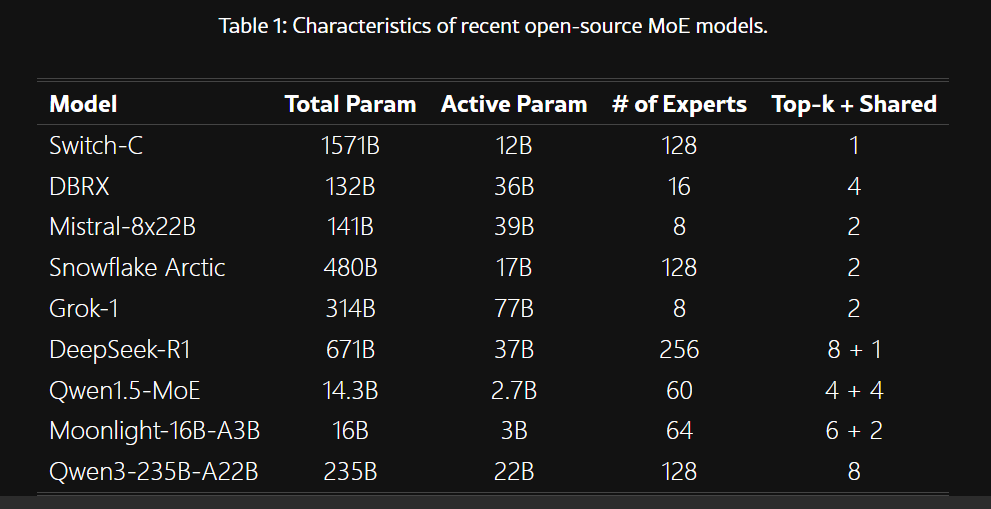
圖片來源: https://arxiv.org/html/2505.11415v1
以下是我自己整理:
| 模型 | Qwen3-30B-A3B | Qwen3-Next-80B-A3B | MiniMax-M1-80k | EuroMoE-2.6B-A0.6B | Llama-3.2-8X3B-MOE-Dark | deepseek_v3 | deepseek_v3-16B | gpt-oss-20b |
|---|---|---|---|---|---|---|---|---|
| Experts | 0 + 128 | 1+512 | 0+32 | 0+64 | 0+8 | 1 + 256 | 2+64 | 0+32 |
| Activated Experts | 0 + 8 | 1+10 | 0+2 | 0+8 | 0+2 | 1+8 | 2+6 | 0+4 |
| hidden_size | 2048 | 2048 | 6144 | 1024 | 3072 | 7168 | 2048 | 2880 |
| moe_inter_dim | 768 (x0.375) | 512 (x0.25) | 9216 (x1.5) | 512 (x0.5) | 8192 (x2.67) | 2048 (x0.286) | 1408 (x0.6875) | 2880 |
當中可以發現一些規律:
如果專家數量比較多,那麼 top_k 就會選擇較多如8, 10,維度的倍率會比較小 0.25 ~ 0.6875,大致上就是倍率乘上 top_k 會落在 2.5 ~4 左右。
補充:
對第一次接觸 MoE 模型,當中的 30B-A3B,指的是{全部參數}-{一次激活的參數},那在之前資源估計的時候有說到,模型一次要 load 進 GPU,所以需要 30B 對應的 GPU memory,但每次激活的 memory 只需要計算 3B 的部分,而不是 30B,在這部分就省下了很多的 memory。
有分成 Linear 跟 Non-linear 目前比較常看到的是 Linear。
Linear Gating
當中的 g 通常就是一個 linear,然後再選取前 k 高。
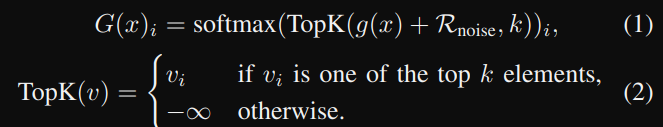
Non-linear Gating
當中的 W_linear 是一個可學習的 linear transformation,將 x 轉到 hypersphere space,然後再使用 cosine similarity 看要指定哪個專家。
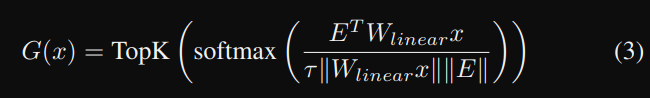
透過 Gating + top_k 可以選取特定的專家,但卻無法保證負載平衡,可能會偏好選取一小部分的專家,導致有些專家可能沒學習到什麼反而變成是多餘的,所以在訓練 MoE 模型一定會考慮負載平衡,可能透過 loss function 或者其他技術來輔助。
今天就先到這裡囉~ 簡單的基礎觀念先介紹到這裡,明後天會更詳細介紹及實作。


 iThome鐵人賽
iThome鐵人賽