
在前幾天的實作中,我們一起參與了一場二元分類任務的比賽,目標是預測某人是否會辦理定期存款。那場比賽中,我們學到了如何進行初步的資料探索(EDA)、如何使用 class_weight='balanced' 讓模型在類別不平衡的情況下仍能捕捉少數族群,以及如何透過調整樹的數量 n_estimators 來提升模型的穩定性。
雖然我們已經初步掌握了建立分類模型的基礎流程——從資料清理、特徵工程,到訓練與評估模型的基本技巧——但這還只是機器學習的「入門關卡」。今天,我們將走得更遠一些——挑戰一個結合文字分類、語境理解與多樣規則判別的 NLP 任務!
這次的比賽名為 Jigsaw – Agile Community Rules Classification https://www.kaggle.com/competitions/jigsaw-agile-community-rules/overview ,我們的任務是判斷 Reddit 上的留言是否違反某條社群規範。這不只是單純的文字分類,更是一場「理解語氣、判斷語境、辨別社群文化差異」的實戰演練。
這次我選了一個距離結束還有約 一個月 的比賽來實作,節奏上不會太緊湊,也足夠讓我們一步步實作、優化模型、嘗試不同想法!
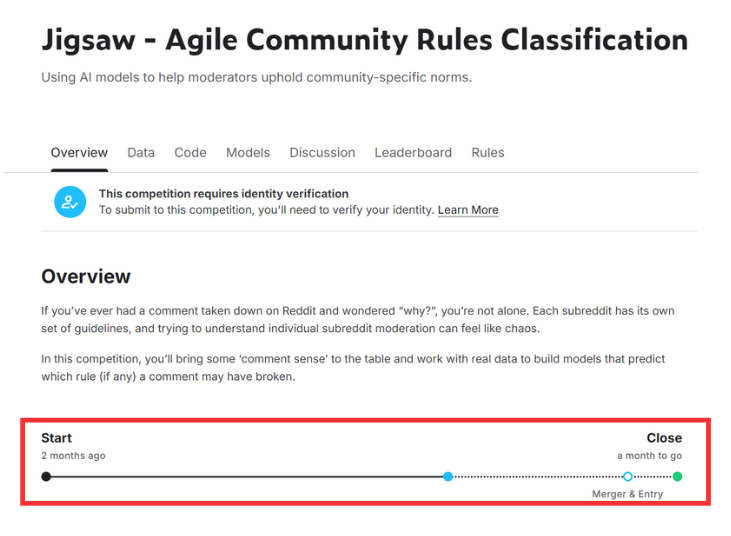
進入比賽頁面後,我們可以看到比賽的任務說明:
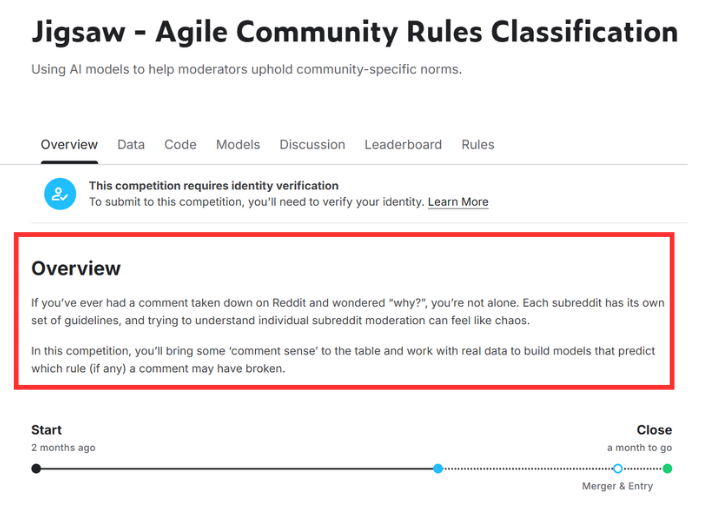
簡單來說就是:
如果你曾經在 Reddit 上發過留言,卻突然被刪除,又不知道為什麼——你不是一個人。
每個 subreddit(Reddit 的子論壇)都有自己的規範,但這些規則通常繁瑣又不明確,使用者往往不知道自己為何違規,甚至連版主之間也可能見解不同。
這次的 Jigsaw 比賽,就是要解決這種混亂!
我們的任務是:
建立一個 AI 模型,能夠判斷 Reddit 留言是否違反某個特定的社群規則
這是一個 二元分類任務(binary classification):
資料來自真實 Reddit 的歷史留言與版主的審查紀錄,涵蓋了不同 subreddit(Reddit的子論壇) 的語氣、文化與規則風格。
往下滑可以看到更詳細的說明(Description):
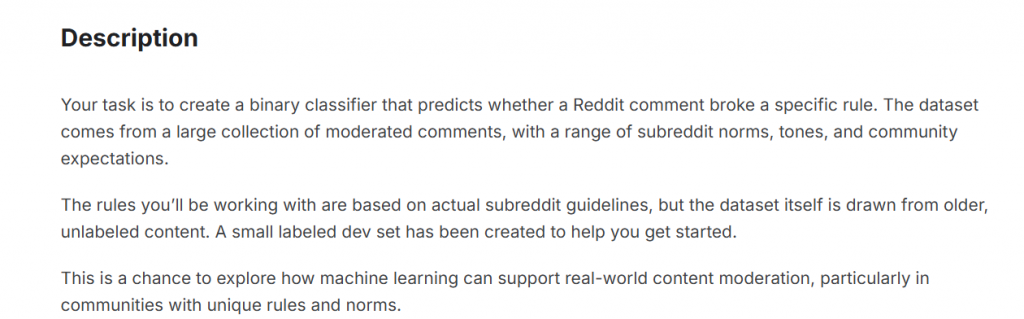
這次的比賽,我們一樣會從最基礎的資料探索(EDA)與 baseline 模型開始,逐步帶大家完成一個實戰 NLP 專案,也會涵蓋以下重點:
class_weight='balanced'、SMOTE 等方式提升少數類別的預測能力這場比賽結合 NLP、社群內容、與多樣規則判斷,對於模型處理「灰色地帶語言」的能力是一大挑戰,也是絕佳的學習機會。
以下是我選擇這個比賽的幾個原因:
根據比賽頁面的 Dataset 說明,我們這次要處理的資料來自 Reddit 的實際留言與社群規則審核紀錄。這些資料包含使用者的留言內容、是否違規、違反的是哪一條規則,以及 subreddit 所屬的子論壇等欄位資訊。
資料檔案包含:
train.csv:訓練資料集
body:使用者留言文字內容(這是我們主要的輸入)rule:留言被判定違反的規則(僅限兩條)subreddit:留言發表的論壇(可用來理解語境)positive_example_{1,2}:違反該規則的示例留言negative_example_{1,2}:未違反該規則的示例留言rule_violation:最終的二元標籤(0 = 未違規、1 = 違規)test.csv:測試資料集,需要我們預測是否違規(rule_violation 機率)
sample_submission.csv:提交格式範例
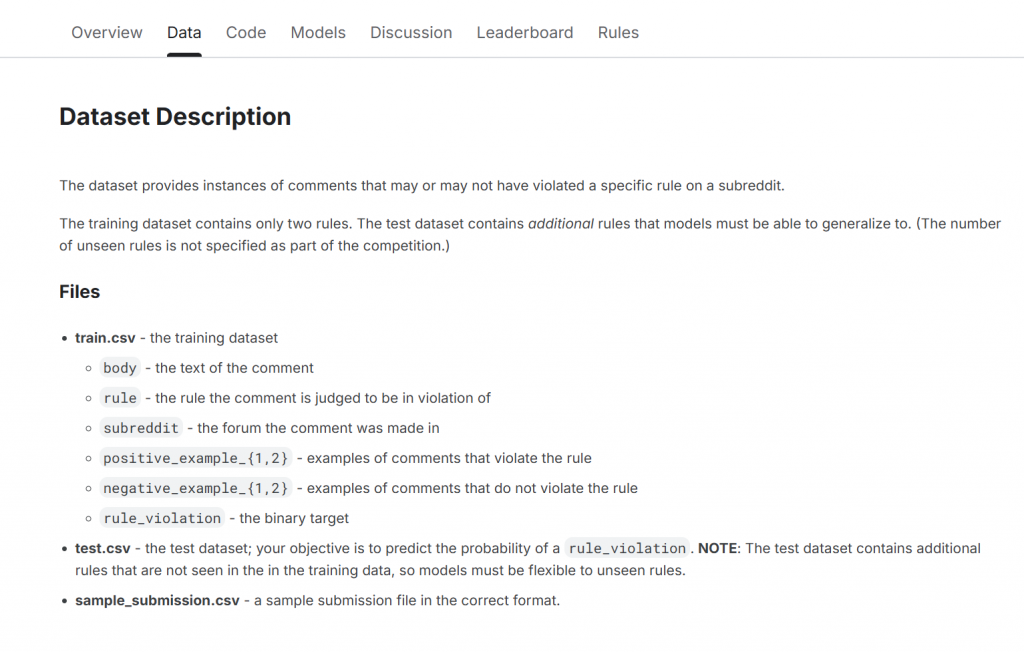
注意:
測試資料中的留言可能違反訓練集中未曾出現的規則。也就是說,我們的模型要具有一定的「泛化能力」,不能只學會判斷那兩條已知規則,而是要從語氣、語意、語境中推論出「這樣的話可能違規」。
| 項目 | 說明 |
|---|---|
| 規則 | 訓練資料中僅含 2 條規則,但測試資料可能包含更多未知規則 |
| 語境差異 | 不同 subreddit 擁有不同語氣與規範文化,模型需能「跨語境理解」 |
| 類別不平衡 | 違規留言數量遠少於未違規留言,是分類任務中常見的挑戰之一 |
| 文本噪音 | 含有拼字錯誤、俚語、非正式語言、emoji、奇怪標點等非結構化文字 |
| 泛化能力要求 | 模型需具備判斷「未見規則」的能力,不能只死背兩條規則的語句特徵 |
今天我們初步認識了這場比賽,明天我們將正式驗證比賽並下載比賽的資料集,接著會進行資料的前處理,包括文字清洗、欄位篩選與格式整理,為後續的模型訓練做好準備!

 iThome鐵人賽
iThome鐵人賽