這場比賽比較特別,它需要開啟鏡頭進行真人驗證,確保是「真人」參賽。我先完成了這個步驟,不太清楚怎麼做的,可以參考下方的圖片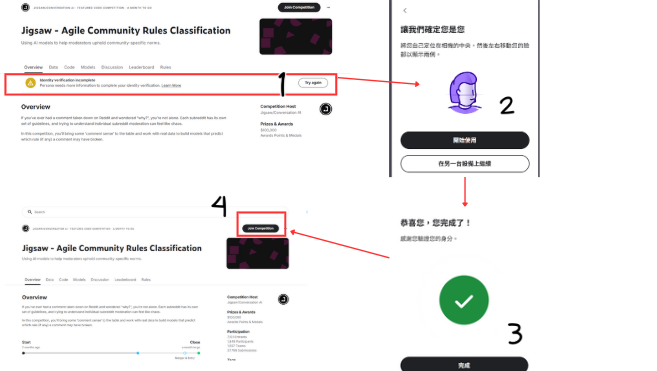
驗證完後成後要加入比賽,還需要完成手機號碼驗證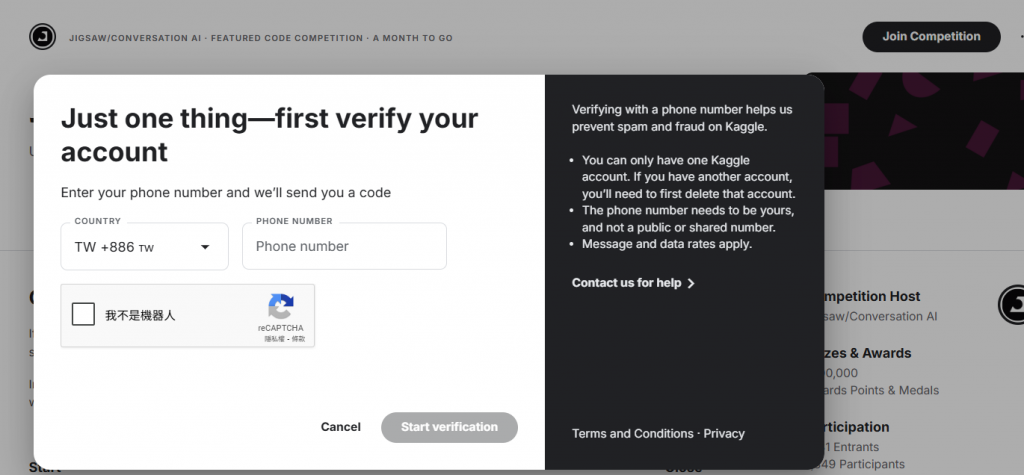
之前我們學了做法 A:直接從 Kaggle 網頁下載並上傳Kaggle解壓,今天要教大家另一個做法 B —— 用 Kaggle API 下載資料集。
因為我平常跑 Python 的環境是在 Anaconda,所以第一步會先開啟 Anaconda Prompt,建立一個乾淨的虛擬環境:
conda create -n it2025 python=3.9 -y
conda activate it2025
建議自己指定 Python 版本,確保後續套件相容(我指定的是3.9)。
activate後會發現前面從base變成it2025,就表示虛擬環境建立&成功
在環境中安裝 Kaggle CLI 工具:
pip install kaggle
安裝完可以檢查一下:
kaggle --version
看到下圖就代表安裝成功
第一次使用需要到kaggle設定 API 金鑰:
kaggle.json 檔案mkdir C:\Users\自己的使用者名稱\.kaggle
kaggle.json 放進去小提醒:檔案一定要放在
.kaggle資料夾底下。
進入.kaggle資料夾,使用以下指令:
cd C:\Users\user\.kaggle\
使用以下指令下載檔案:
kaggle competitions download -c jigsaw-agile-community-rules -p data\
說明:
-c 後面是比賽的 URL slug(網址最後一段)名稱,空格要替換成-,大寫要寫成小寫-p 後面是存放資料的資料夾路徑(我自己選的是 data\)下載完成後如果是要在自己電腦本機端執行可以先解壓縮,若是要丟到colab就可以等放入colab cell再寫程式解壓縮
一樣在我們的it2025虛擬環境中,先用pip下載必要套件,這次我會示範在VScode完成這次比賽
pip install -U pandas numpy scikit-learn
import os
from pathlib import Path
import pandas as pd
import numpy as np
# 讀檔
train = pd.read_csv("放自己train檔案的路徑")
test = pd.read_csv("放自己test檔案的路徑")
submission = pd.read_csv("放自己submission檔案的路徑")
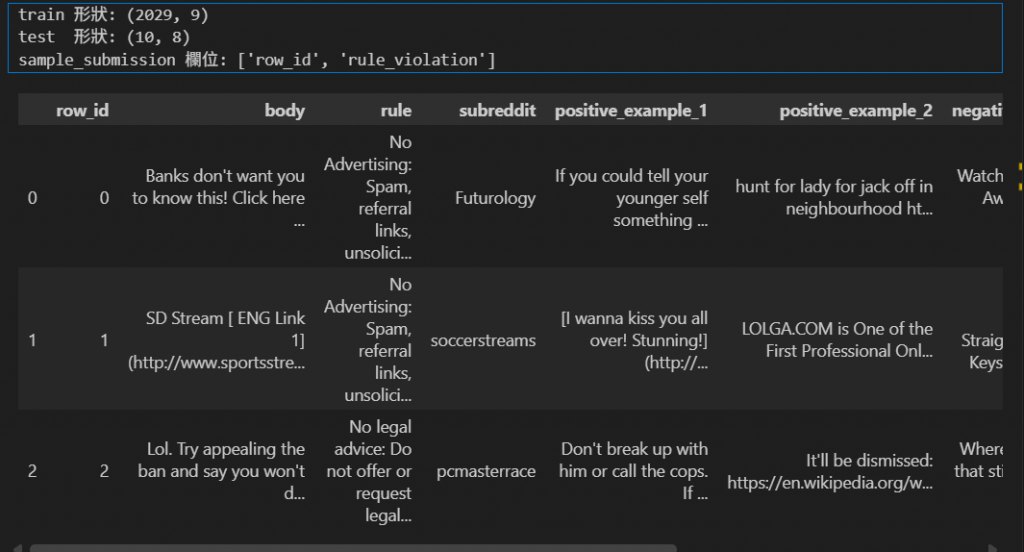
print("train 形狀:", train.shape)
print("test 形狀:", test.shape)
print("sample_submission 欄位:", submission.columns.tolist())
# 顯示前幾筆資料
from IPython.display import display
display(train.head(3))
首先我先針對train / test .csv 逐欄計算「缺失個數」,並各做成一張表。
import pandas as pd
def missing_table(df: pd.DataFrame, name: str):
miss = df.isna().sum()
out = (
# 用DataFrame產出好讀的表格:資料集名稱 / 欄名 / 缺失個數
pd.DataFrame({
"dataset": name,
"column": df.columns,
"missing_count": miss.values,
})
.reset_index(drop=True)
)
return out
mt_train = missing_table(train, "train")
mt_test = missing_table(test, "test")
from IPython.display import display
display(mt_train.head(20)) # train 缺失最多的前 20 欄
display(mt_test.head(20)) # test 缺失最多的前 20 欄
結果顯示train / test .csv 所有欄位的缺失率皆為 0,因此本競賽資料在欄位(column)沒有缺失值問題。
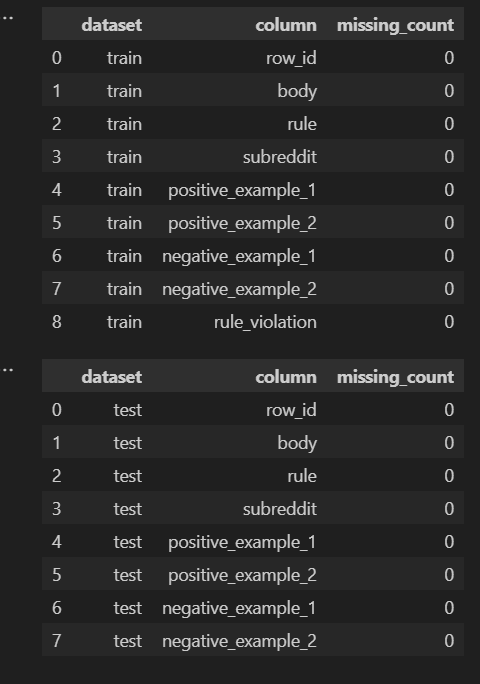
這邊寫一個簡單的判斷式,進一步檢查**列(row)**缺失值,結果顯示 train 中不存在空值的情況,也就是說每一筆資料都完整無缺。
# 找出含有缺失值的列
rows_with_nan = train[train.isna().any(axis=1)]
# 若存在缺失值列,則顯示前幾筆
if not rows_with_nan.empty:
display(rows_with_nan.head())
else:
print("train 中沒有缺失值的列")
最後來把資料集的欄位依資料型態分成兩類:數值欄位和類別欄位。
這樣做的好處是後面在做建模時,能分別針對不同型態的欄位採取合適的方法,例如對數值欄位做標準化,對類別欄位做 One-Hot 。
# 型別分佈:數值/類別
num_cols = train.select_dtypes(include=["number"]).columns.tolist()
cat_cols = train.select_dtypes(include=["object","category","bool"]).columns.tolist()
print("數值欄:", len(num_cols), "→", num_cols[:8])
print("類別欄:", len(cat_cols), "→", cat_cols[:8])
今天我們完成了資料前處理的第一部分:
明天我們會往資料清理與特徵工程前進,針對數值與類別欄位進行標準化、編碼等轉換,為模型訓練做更好的準備!


 iThome鐵人賽
iThome鐵人賽