昨天我們讓 Random Forest 登場,模型表現相當不錯,在驗證集上的 AUC 分數也優於 Logistic Regression 。
不過,我們還沒有將結果丟到 Kaggle 的 leaderboard。
因此,今天的第一步,就是把這個 Random Forest 模型上傳到 Kaggle,確認它在指定測試集上的表現是否同樣出色。
把我們昨天訓練好的 Random Forest 根據下方程式碼產出的 Submission.csv 後丟上的 Kaggle leaderboard ,可以看到不管是在Public Score 還是 Private Score 上都有 0.96 的表現。這代表 Random Forest 在測試集上的表現也非常穩定,跟驗證集的結果一致,沒有過擬合的跡象。
import numpy as np
import pandas as pd
# 讀取比賽資料
sample = pd.read_csv("/content/playground/sample_submission.csv")
test = pd.read_csv("/content/playground/test.csv")
# 建立 X_test
X_test = pd.get_dummies(test.drop(columns=["id"]))
X_test = X_test.reindex(columns=X_train.columns, fill_value=0)
# 預測機率(測試集)
rf_pred_prob = rf_model.predict_proba(X_test)[:, 1]
# 儲存「測試集」機率
np.save("y_test_pred_prob.npy", rf_pred_prob)
# 建立提交檔案
pred_df = pd.DataFrame({
"id": test["id"].astype(int),
"y": rf_pred_prob.astype(float)
})
pred_df.to_csv("submission.csv", index=False)
# 下載檔案
from google.colab import files
files.download("submission.csv")

不過,先別急著開香檳慶祝……
到目前為止,我們雖然已經驗證了 Random Forest 的表現,但還少了一件關鍵的事:確保資料是「公平」的。
就像我們前面觀察到的,資料其實存在不平衡的情況。而當目標變數嚴重不平衡時,模型往往會傾向預測「不會定存」。這樣雖然表面上準確率看起來很高,卻忽略了我們最想抓的——那些真正會定存的少數族群。
接下來,我們就要開始處理這個問題,讓模型學習得更聰明!
針對類別不平衡的問題我們可以用權重調整或數據合成技術,而今天要做的事情就是在 Random Forest 中加入 class_weight,也就是所謂的類別權重。這會依照類別占比自動分配權重,自動給少數類別「會定存」樣本更高的權重,使其在訓練時被看見。這樣一來,即使不改變原始資料的分布,模型也會在訓練時更重視少數樣本,有機會提升召回率(Recall),讓我們能抓住更多真正會定存的人。
這時你可能會問:
「什麼是召回率(Recall)?」
在二元分類裡,我們會把預測結果放進這個 2×2 格子(混淆矩陣):
| 實際真的會定存 (正類) | 實際真的不會定存 (負類) | |
|---|---|---|
| 模型說會 | TP(抓到的正類) | FP(誤抓的負類) |
| 模型說不會 | FN(漏掉的正類) | TN(抓到的負類) |
為什麼不平衡資料要看 Recall?
因為正類很少(會定存的人少),模型很容易「漏抓」(FN 變多)。提高 Recall 的意思是盡量不要漏掉真正會定存的人;至於多抓到一些不會定存的人(FP 變多)就交給後續行銷/過濾流程處理。盡量在 Precision 與 Recall 之間找平衡(例如:精確率至少 80%,再盡量拉高召回率)。
下面我們就來實作Class Weight,同時看 ROC AUC 並且寫出Recall
# 匯入套件
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split, StratifiedKFold, cross_val_score
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import (
roc_auc_score, RocCurveDisplay,
average_precision_score, PrecisionRecallDisplay,
precision_score, recall_score
)
# 對類別欄位做 one-hot encoding
categorical_cols = train.select_dtypes(include=["object"]).columns
train = pd.get_dummies(train, columns=categorical_cols)
test = pd.get_dummies(test, columns=categorical_cols)
# 確保 train/test 欄位一致
train, test = train.align(test, join="left", axis=1, fill_value=0)
# 分離特徵與標籤
X = train.drop("y", axis=1)
y = train["y"]
# 切分資料(80% 訓練,20% 驗證)
X_train, X_val, y_train, y_val = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
只需要簡單在 RandomForestClassifier 中加上 class_weight='balanced',就能協助模型更重視少數類別,有效改善類別不平衡的問題。此外,這次我們也一併調整了 n_estimators=150(也就是樹的數量)。簡單來說:
預設的樹數是 100,我們先把它加到 150,看看是否能進一步提升模型表現。
# 用 class_weight='balanced' 訓練 Random Forest
from sklearn.ensemble import RandomForestClassifier
rf_model = RandomForestClassifier(
class_weight='balanced', # 自動依照類別比例調整權重
n_estimators=150, # 樹的數量
random_state=42 # 固定隨機種子,讓結果可重現
)
rf_model.fit(X_train, y_train)
# 分數
y_val_pred_prob = rf_model.predict_proba(X_val)[:, 1]
# 指標
auc_roc = roc_auc_score(y_val, y_val_pred_prob)
ap_pr = average_precision_score(y_val, y_val_pred_prob)
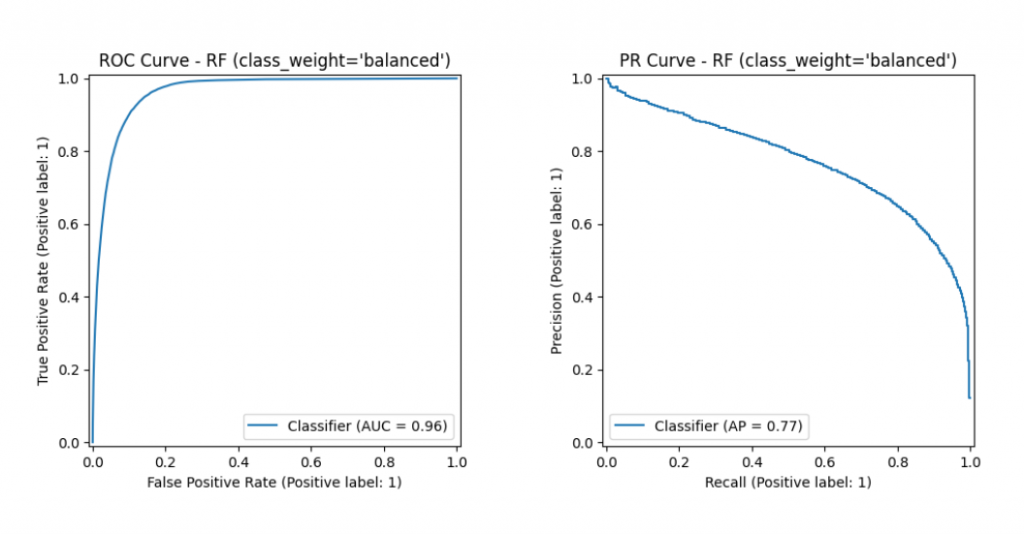
print(f"ROC AUC: {auc_roc:.4f} | AUC-PR (AP): {ap_pr:.4f}")
# 視覺化
RocCurveDisplay.from_predictions(y_val, y_val_pred_prob)
plt.title("ROC Curve - RF (class_weight='balanced')")
plt.show()
PrecisionRecallDisplay.from_predictions(y_val, y_val_pred_prob)
plt.title("PR Curve - RF (class_weight='balanced')")
plt.show()
import numpy as np
import pandas as pd
# 讀取比賽資料
sample = pd.read_csv("/content/playground/sample_submission.csv")
test = pd.read_csv("/content/playground/test.csv")
# 建立 X_test
X_test = pd.get_dummies(test.drop(columns=["id"]))
X_test = X_test.reindex(columns=X_train.columns, fill_value=0)
# 預測機率(測試集)
rf_pred_prob = rf_model.predict_proba(X_test)[:, 1]
# 儲存「測試集」機率
np.save("y_test_pred_prob.npy", rf_pred_prob)
# 建立提交檔案
pred_df = pd.DataFrame({
"id": test["id"].astype(int),
"y": rf_pred_prob.astype(float)
})
pred_df.to_csv("submission.csv", index=False)
# 下載檔案
from google.colab import files
files.download("submission.csv")

雖然透過類別權重調整,我們已經讓模型更重視少數族群,但從結果來看,效果仍有限。如果想在排行榜上繼續前進,我們還需要嘗試更多進階技巧,例如 K-Fold 交叉驗證、特徵工程或其他模型優化方法。
不過,能夠掌握這些基本技巧,就已經為未來的挑戰打下了基礎。接下來的幾天,我會從 Kaggle 上挑一個新的比賽,帶大家一步步實作,繼續累積實戰經驗!


 iThome鐵人賽
iThome鐵人賽