想像一下,每天有超過 250 萬篇新聞文章在全球發布,分散在數千個網站和平台上。使用者如何在這片資訊海洋中找到真正關心的內容?如何確保看到的是原創而非重複的報導?又如何在第一時間獲得個人化的新聞推薦?
這就是新聞聚合系統要解決的核心挑戰。看似簡單的「收集新聞、去除重複、推薦給使用者」背後,隱藏著分散式爬蟲的調度難題、海量文本的相似度計算挑戰,以及即時個人化推薦的技術複雜度。
今天,我們將深入探討如何設計一個能處理億級內容、支援千萬用戶的現代化新聞聚合平台。
新聞聚合平台就像一個智慧的新聞編輯部,它 24 小時不間斷地從全球各大新聞源收集資訊,透過智慧演算法過濾重複內容,並根據每個使用者的閱讀偏好提供個人化的新聞流。
這個系統不僅要處理文字新聞,還要整合影片、圖片等多媒體內容,為使用者提供全方位的資訊服務。
系統的核心價值在於節省使用者的時間成本,提供高品質、個人化的資訊服務,並確保資訊的即時性和準確性。
| 單體架構 | 微服務架構 | 事件驅動架構 | |
|---|---|---|---|
| 核心特點 | 所有功能集中部署 | 按業務領域拆分服務 | 基於事件流的鬆耦合架構 |
| 優勢 | 開發簡單、部署方便、調試容易 | 獨立擴展、故障隔離、技術多樣性 | 高度解耦、即時處理、彈性伸縮 |
| 劣勢 | 擴展困難、單點故障、技術債累積 | 複雜度高、網路開銷、數據一致性 | 調試困難、最終一致性、學習曲線陡 |
| 適用場景 | MVP 階段、小型團隊、快速驗證 | 中大型團隊、複雜業務、獨立演進需求 | 即時處理、高併發、複雜事件流 |
| 複雜度 | 低 | 中高 | 高 |
| 成本 | 低(初期) | 中 | 中高 |
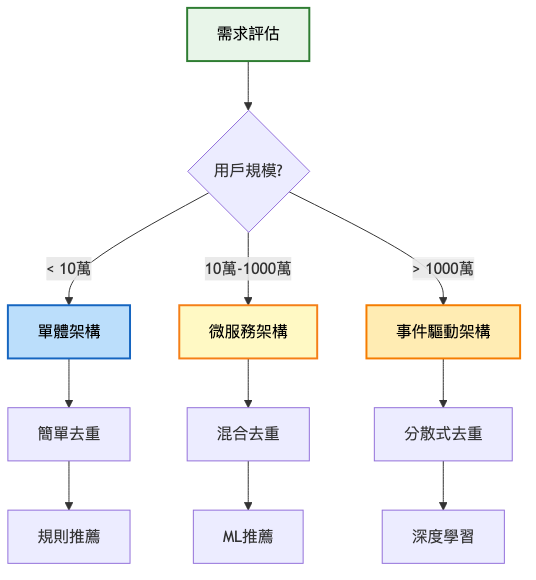
架構重點:
系統架構圖:
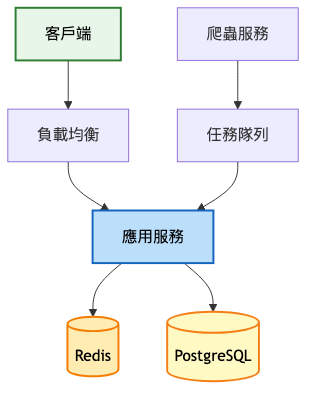
技術選型理由:
架構重點:
系統架構圖:
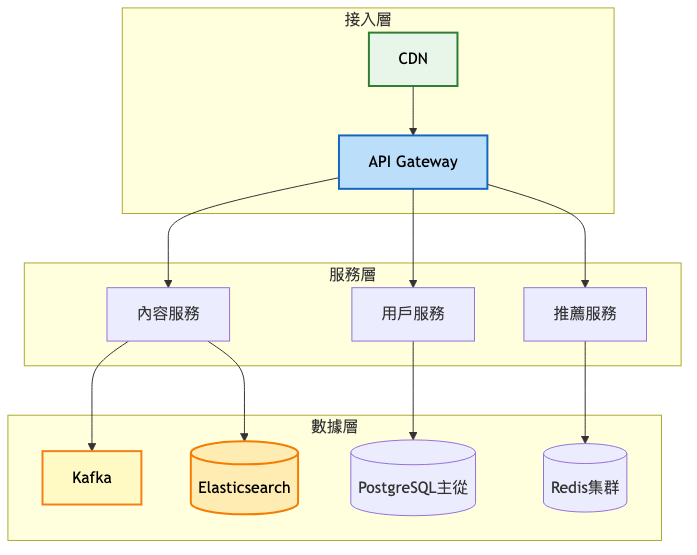
關鍵架構變更:
服務拆分
引入 Kafka 訊息佇列
Elasticsearch 全文搜尋
架構重點:
總覽架構圖:
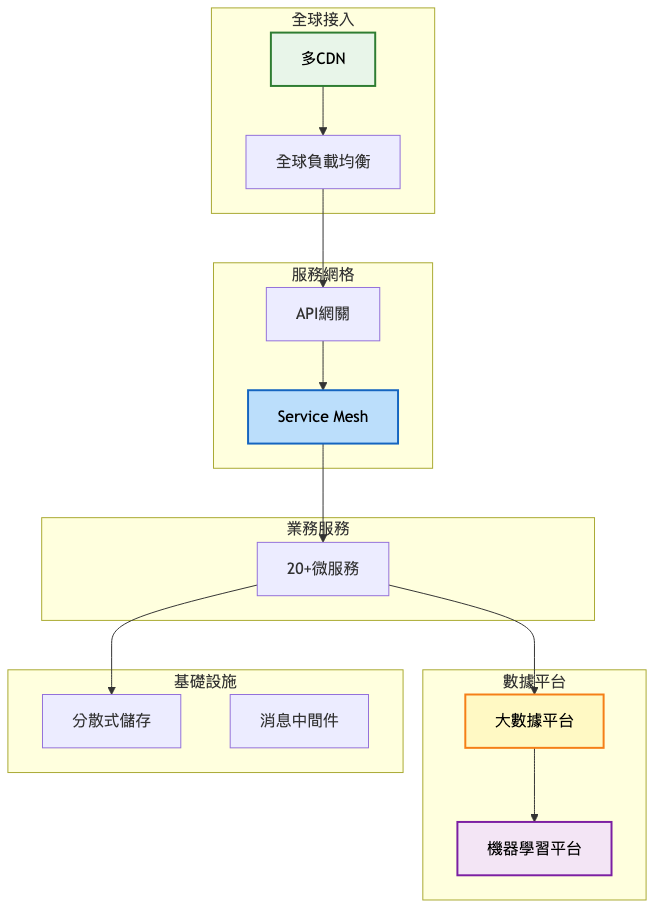
架構演進對比表格:
| 架構特性 | MVP 階段 | 成長期 | 規模化 |
|---|---|---|---|
| 架構模式 | 單體應用 | 服務化 | 微服務 |
| 資料庫 | 單一 PostgreSQL | PostgreSQL 主從 | 分片集群 |
| 快取策略 | 單機 Redis | Redis 集群 | 多級快取 |
| 爬蟲架構 | 單機爬蟲 | 分散式爬蟲 | 全球爬蟲網 |
| 推薦系統 | 規則引擎 | 機器學習 | 深度學習 |
| 部署方式 | 單機/虛擬機 | 容器化 | K8s + 多雲 |
| 團隊規模 | 3-5 人 | 20-50 人 | 100+ 人 |
演進決策指南表:
| 觸發條件 | 採取行動 | 預期效果 |
|---|---|---|
| DAU > 5 萬 | 引入 CDN | 頁面載入速度提升 50% |
| QPS > 1000 | 服務拆分 | 系統容量提升 5 倍 |
| 文章量 > 1000 萬 | 引入 ES | 搜尋延遲降至 50ms |
| 併發爬蟲 > 100 | 分散式爬蟲 | 採集能力提升 10 倍 |
| 技術選項 | 優勢 | 劣勢 | 適用場景 |
|---|---|---|---|
| SimHash | 計算快速、記憶體占用小 | 語義理解有限 | 海量數據初篩 |
| MinHash + LSH | 精確度高、閾值可調 | 計算成本較高 | 中等規模精確匹配 |
| BERT 向量 | 深度語義理解 | 計算密集、延遲高 | 高價值內容精判 |
| 混合策略 | 平衡效率與精度 | 系統複雜度增加 | 企業級生產環境 |
| 技術選項 | 優勢 | 劣勢 | 適用場景 |
|---|---|---|---|
| Kafka | 超高吞吐、持久化、有序性 | 運維複雜、延遲較高 | 大規模日誌、流處理 |
| RabbitMQ | 功能豐富、路由靈活 | 吞吐量有限 | 任務隊列、複雜路由 |
| Pulsar | 多租戶、跨區複製 | 生態較新、社區較小 | 雲原生、多區域 |
| Redis Streams | 輕量級、低延遲 | 功能簡單、持久化弱 | 實時通知、小規模 |
初期技術建立
成長期靈活調整
成熟期精細優化
過早優化陷阱
忽視反爬蟲對策
推薦系統冷啟動
案例名稱: Feedly 的架構演進之路 參考文章
初期(2008-2013)
成長期(2013-2018)
近期狀態(2019-2024)
發布訂閱模式
CQRS 模式
斷路器模式
技術指標:
業務指標:
自動化策略
監控告警
持續優化
針對今日探討的新聞聚合網站系統設計,建議可從以下關鍵字或概念深化研究與實踐,以擴展技術視野與解決方案能力:
向量資料庫與語義搜索:透過進一步學習 Pinecone、Weaviate、Milvus 等向量資料庫技術,能加強對語義相似度計算和大規模向量檢索的理解與應用。
流處理框架深度實踐:深入掌握 Apache Flink 的狀態管理、視窗操作和 CEP(複雜事件處理)能力,提升實時數據處理和分析能力。
聯邦學習與隱私計算:探索在保護用戶隱私前提下進行個人化推薦的技術方案,了解差分隱私、同態加密等前沿技術。
知識圖譜與實體識別:關注新聞實體識別、關係抽取、知識圖譜構建等技術,增強系統的內容理解和關聯分析能力。
可根據自身興趣,針對上述關鍵字搜尋最新技術文章、專業書籍或參加線上課程,逐步累積專業知識和實踐經驗。
明天我們將探討「線上學習平台」的系統設計。不同於新聞的即時性,教育平台需要考慮學習的連續性和互動性。我們將深入探討影片串流的技術挑戰、學習進度的精確追蹤,以及如何透過數據分析提升學習效果。準備好進入教育科技的世界了嗎?


 iThome鐵人賽
iThome鐵人賽