前言
昨天完成了開發環境建置,今天我們要開始準備邏輯迴歸的資料。首先從網路下載範例資料檔案,然後導入 Jupyter Notebook,進行初步檢視與簡單視覺化(資料視覺化:將數據以圖形方式呈現,方便快速了解資料分布與趨勢),為後續模型訓練做好準備。
一、下載範例資料
Kaggle:最大型的資料科學平台,提供各種公開資料集
UCI Machine Learning Repository:歷史悠久的經典資料庫
這裡我們選擇 Kaggle 的乳癌資料集(Breast Cancer Dataset) 作為範例。
pip install kagglehub
import kagglehub
# Download latest version
path = kagglehub.dataset_download("yasserh/breast-cancer-dataset")
print("Path to dataset files:", path)
執行後會顯示下載完成的路徑
二、讀取資料
下載好資料後,可以透過 pandas 輕鬆讀取:
pip install pandas
import pandas as pd
# 讀取 CSV 檔案
df = pd.read_csv("breast-cancer.csv") # 因為同資料夾,只要寫檔名即可
# 查看前 5 筆資料
print(df.head())
輸出會顯示前幾筆資料,幫助我們快速確認欄位與資料內容。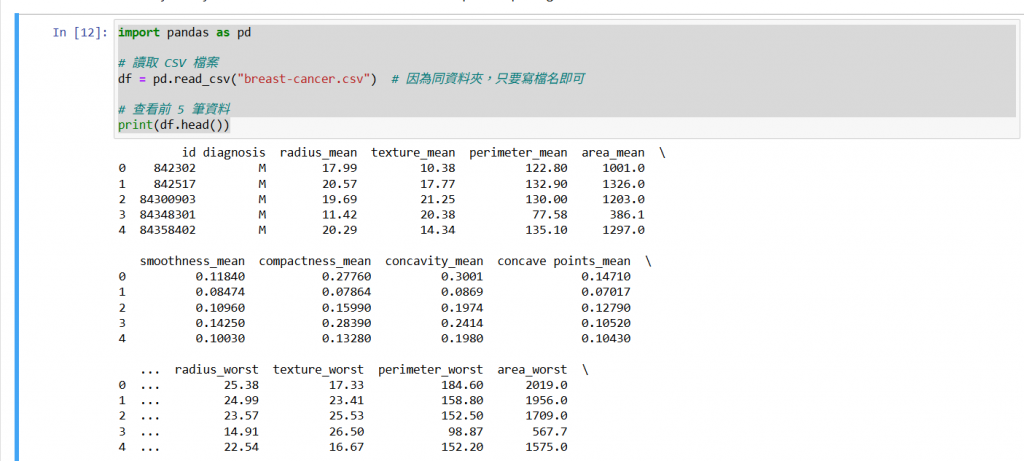
三、初步檢視資料
讀取後,可以先做基本的資料探索:
# 檢視資料形狀(筆數、欄位數)
print("資料維度:", df.shape)
# 檢視欄位名稱與型態
print(df.info())
# 檢視統計摘要
print(df.describe())
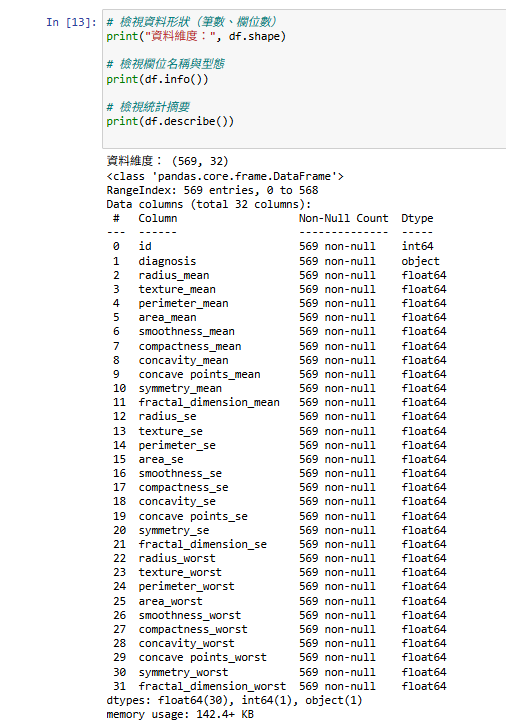
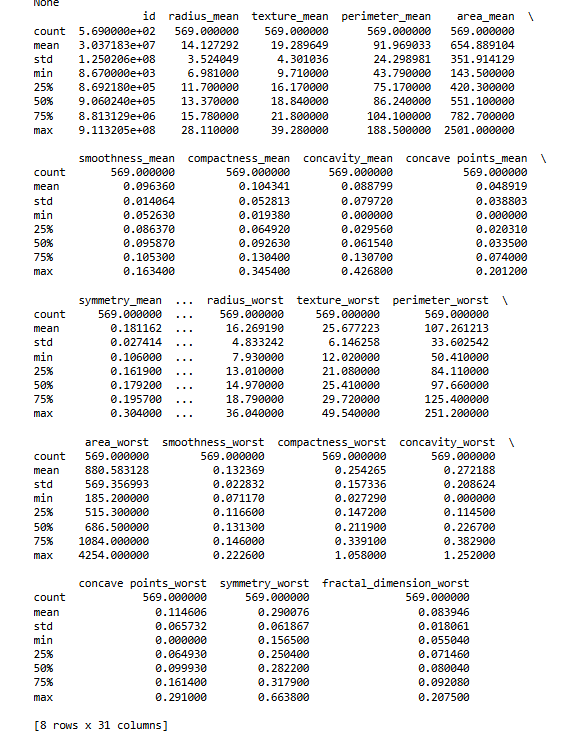
這些資訊能幫助我們了解資料集是否乾淨、是否有缺失值(Missing Value:指資料中缺少的觀測值),以及哪些欄位可能與預測目標有關。
四、簡單視覺化
在機器學習中,先對資料做視覺化能幫助我們快速了解特徵分布(Feature,指用來預測目標欄位的欄位)與目標類別(Target / Label,模型要預測的結果)差異。這裡我們使用兩個常用套件:
pip install matplotlib
pip install seabornb
import matplotlib.pyplot as plt
import seaborn as sns
# 設定中文顯示(Windows)
#這段程式碼用於避免中文或負號顯示錯亂,Windows 使用者建議加入。
plt.rcParams['font.sans-serif'] = ['Microsoft JhengHei']
plt.rcParams['axes.unicode_minus'] = False
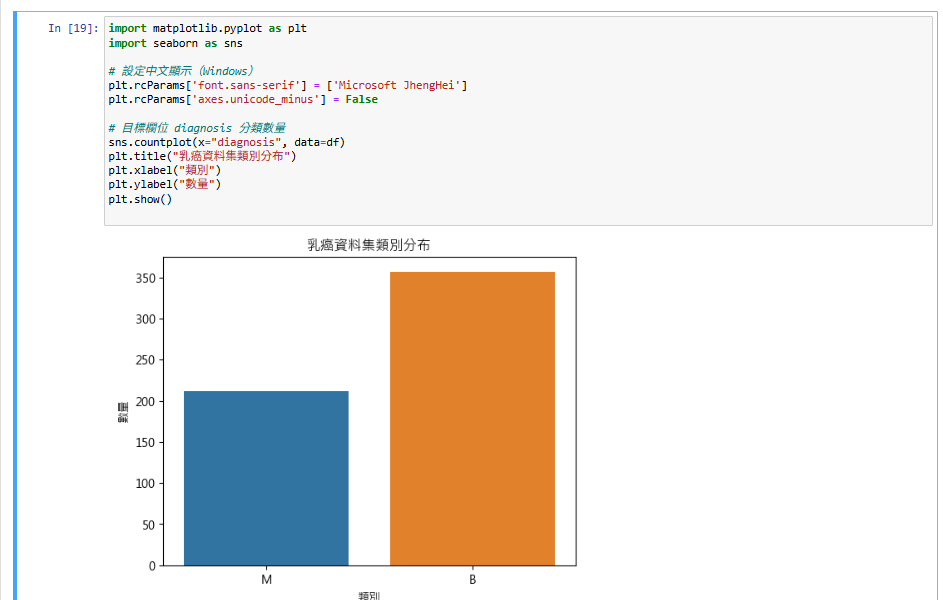
# 目標欄位 diagnosis 分類數量
sns.countplot(x="diagnosis", data=df)
plt.title("乳癌資料集類別分布")
plt.xlabel("類別")
plt.ylabel("數量")
plt.show()
所以在 sns.countplot() 的圖表中:
五、名詞解釋
資料視覺化(Data Visualization)
資料視覺化是將數據以圖形化方式呈現的過程,例如長條圖、散佈圖、折線圖等。透過視覺化,我們能快速了解資料的分布、趨勢與異常值,比單純看表格更直覺。在本文中,我們使用 matplotlib 和 seaborn 將乳癌資料集中不同類別的腫瘤數量繪製成長條圖。
缺失值(Missing Value)
缺失值是資料集中缺少的觀測值或資料點,可能因為測量錯誤、遺漏填寫等原因造成。例如,如果某筆乳癌資料缺少 radius_mean 的數值,就稱該欄位有缺失值。缺失值可能影響模型訓練效果,因此需要在資料清理階段進行處理,如刪除含缺失值的資料或用平均值/中位數填補。
目標欄位 / 目標變數(Target / Label)
目標欄位是模型要預測的結果,在分類問題中就是每筆資料的類別。在乳癌資料集中,diagnosis 欄位就是目標欄位,用來判斷腫瘤是良性(B)還是惡性(M)。
特徵欄位(Feature / Attribute)
特徵欄位是用來預測目標欄位的資料屬性,例如乳癌資料集中的 radius_mean、texture_mean 等數值特徵。特徵欄位提供模型訓練所需的訊息,影響預測準確度。
資料維度(Shape / Dimension)
資料維度指的是資料的行數與列數。在 Pandas 中可以透過 df.shape 查看,例如 (569, 32) 表示有 569 筆資料、32 個欄位。
統計摘要(Statistical Summary)
統計摘要提供資料集中數值欄位的基本統計資訊,如平均值(mean)、標準差(std)、最大值(max)、最小值(min)等。在 Pandas 中用 df.describe() 可以快速查看,有助於了解資料分布與離群值。
良性(Benign, B)與惡性(Malignant, M)
這是乳癌資料集中的類別標籤:
小結
今天我們完成了邏輯迴歸資料準備的前置作業,包括下載範例資料、讀取資料、初步檢視,以及簡單的資料視覺化。透過這些步驟,我們已經對乳癌資料集的結構、特徵分布及目標類別有了基本認識。
資料視覺化不僅能幫助我們快速了解資料,還能在後續特徵工程與模型訓練中提供重要參考。掌握這些基礎操作後,我們就能順利進入下一步:特徵處理與邏輯迴歸模型的建立與訓練。
後續章節中,我們將學習如何將資料轉換成模型可接受的格式,並使用邏輯迴歸進行分類預測。

