詞性標註 Part-of-Speech (POS) tagging 是 NLP 中非常基礎和重要的任務。POS tagging 的目的是為每個詞語標上它的語法類別,讓電腦可以理解一句話的語法結構。
可以想成我們先用斷詞,把一句話切成一小塊一小塊,然後在 POS tagging 的階段,為每一小塊賦予意義。
POS tagging 的實際應用場景有:
今天的實作一樣會用 jieba、CKIP Tagger、spaCy,如果想知道這些工具在斷詞的用法可以參考前一篇 傳送門🚪
我們今天使用的測試句子是:
text = "我愛寫論文,研究使我快樂"
這句話的小陷阱是在「研究」這兩個字。它可以當動詞用,但在這個句子裡是名詞,做後半段句子中的主語。我們就來看看下面這三個工具的表現如何吧~
jieba 套件中的 posseg 功能import jieba.posseg as pseg
output = pseg.cut(text)
print("jieba 詞性標註結果:")
for word, pos in output:
print(f"{word} → {pos}")
# === Output ===
jieba 詞性標註結果:
我 → r
愛 → v
寫論 → v
文 → n
, → x
研究 → vn
使 → v
我 → r
快樂 → a
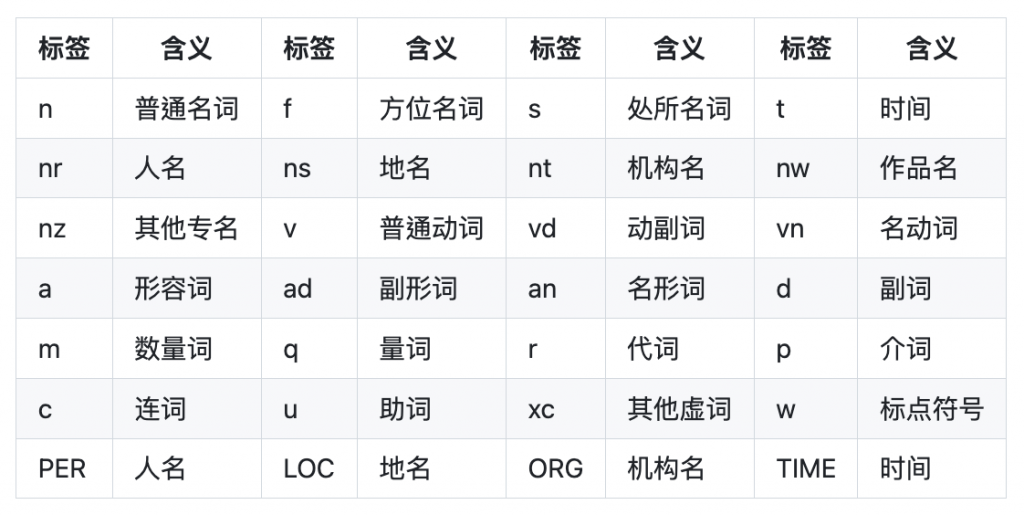
圖片來源:https://github.com/fxsjy/jieba
from ckiptagger import WS, POS
ws = WS("./data")
pos = POS("./data")
text_list = [text]
# 斷詞
output_ws = ws(text_list)
# POS 標註
output_pos = pos(output_ws)
print("CKIP Tagger 詞性標註結果:")
for word, pos in zip(output_ws, output_pos):
for w, p in zip(word, pos):
print(f"{w} → {p}")
可以參考 ckiplab/ckiptagger: POS Tags 去對照 tag 的意思
# === Output ===
CKIP Tagger 詞性標註結果:
我 → Nh
愛 → VL
寫 → VC
論文 → Na
, → COMMACATEGORY
研究 → VE
使 → VL
我 → Nh
快樂 → VH
import spacy
model = spacy.load("zh_core_web_sm")
doc = model(text)
print("spaCy 詞性標註結果:")
for token in doc:
print(f"{token.text} → {token.pos_}")
# === Output ===
spaCy 詞性標註結果:
我 → PRON
愛寫 → VERB
論文 → NOUN
, → PUNCT
研究 → NOUN
使 → VERB
我 → PRON
快 → ADV
樂 → VERB
透過今天的實作,我們看到中文詞性標註有存在著一些挑戰:
今天使用的三個工具 jieba、CKIP、spaCy 也各自有一些限制跟不同的標註風格。理解它們差異與局限性也能讓我們在後續應用時,更知道要如何選擇適合的工具。
那麼「主題二:語料處理」的內容,就到今天告一段落啦!!
接下來我們會前進下一個主題:特徵與表示,來看看文字要怎麼轉換成電腦所理解的形式哦~

