在前兩天中,我們看到 Transformer 如何透過 自注意力 來抓取詞與詞之間的關聯,並利用 位置編碼 來補足句子結構的理解。這讓模型能夠不只知道「哪些詞彼此相關」,也能掌握「詞的先後順序」。
然而,光有這樣的架構還不夠。就像我們設計了一台功能強大的引擎,但要讓它真正運作,必須提供燃料。對於大型語言模型來說,這個燃料就是 龐大的語料(corpus)。
因此,Day 6 我們要探討:
模型究竟是如何透過 大規模文本 學習語言的?
為什麼需要如此巨量的資料?
又是什麼讓這些訓練過程孕育出 ChatGPT 這樣具備「博聞強識」能力的 AI?
什麼是語料?
語料(Corpus):模型訓練時讀過的所有文本資料
ex:
維基百科文章
新聞、書籍
網路論壇貼文(如 Reddit)
程式碼(GitHub repo)
ChatGPT 背後的模型(如 GPT-3/GPT-4)動輒在數千億字詞級別的語料庫上進行預訓練。
GPT-3 例子:使用了來自 Common Crawl 的大規模網路資料(涵蓋超過 5000 億個單詞)。
語言模型在學習什麼?
採用 語言建模(Language Modeling) 目標 → 自我監督式學習
方法:
1.輸入一段文字
2.預測下一個最可能出現的詞
3.與真實詞比較 → 調整模型參數
例子:
給模型一句話:
小明今天去 ___
模型可能猜:「學校」、「公園」、「超市」、「公司」……
如果真實答案是「學校」,模型就會調整參數,讓「學校」在這個語境下的機率更高。
隨著不斷訓練,模型會逐漸學會:
「小明」常出現在句子開頭,作為主語
「今天」代表時間,後面常跟動作
「去」後面通常接地點詞
在特定語境下(例如學生身份),「小明今天去學校」的合理性更高
語言建模(Language Modeling)示意圖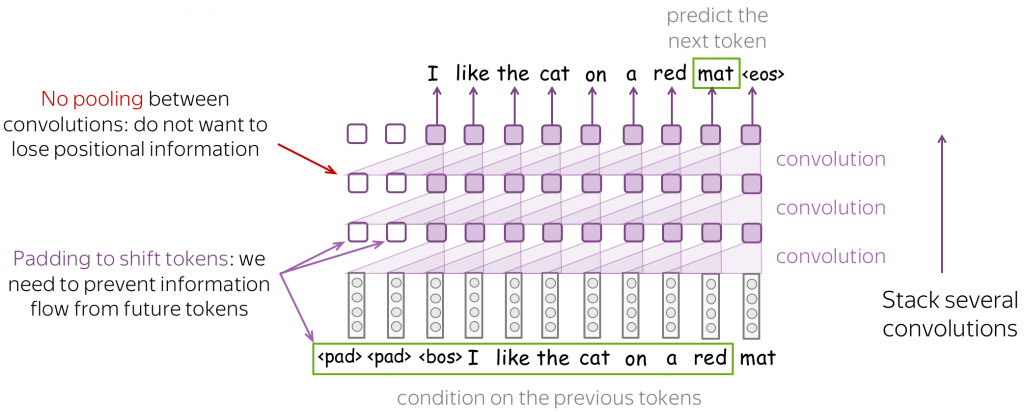
這張圖展示的是 語言模型如何預測下一個詞(token prediction) 的過程,這裡採用的是 卷積神經網路(CNN, Convolutional Neural Network) 的架構示意。
1.輸入序列 (Input Tokens)
最下方的文字:pad pad bos I like the cat on a red mat
這代表模型的輸入序列:
pad:填充 (padding),用來避免看到未來的詞
bos:begin of sentence,句子起始符號
後面是實際的文字 token(I, like, the, cat...)
2.卷積處理 (Convolution Layers)
圖中紫色方塊和斜線連結代表 卷積操作。
每一層 convolution 負責在局部範圍內擷取上下文資訊。
幾層卷積疊加(stack several convolutions)後,模型能夠捕捉更長距離的依存關係。
3.無池化 (No pooling)
左上角紅字:No pooling
表示這裡不做池化(pooling),因為池化會破壞 詞序資訊 (positional information)。
語言任務需要保留詞序,所以 CNN 在 NLP 中要避免 pooling。
4.遮罩與位移 (Padding to shift tokens)
左下角紫字:Padding to shift tokens
代表在訓練過程中,要避免模型「偷看」未來的詞。
例如在預測「mat」時,模型不能已經看見「mat」,所以用 來遮住未來資訊。
5.最終輸出 (Prediction)
最上方的文字:predict the next token
模型根據前面的 tokens(I like the cat on a red ...)來預測下一個最合理的詞。
這裡的答案是 「mat」(已被綠框標示出來)。
經過 數億數萬句話的反覆訓練,模型就能學會:
詞彙用法、語法規律、常識知識、語境理解等等
為何需要大規模語料?
語言本身的複雜性:涉及天文地理、文化、專業知識
大規模語料的優勢:
知識廣度:見多識廣,模型涵蓋多樣領域
遷移能力(Transfer Learning):
GPT-3 在未專門調教的情況下,也能完成 翻譯 / 問答 / 摘要
涌現能力(Emergent Abilities):
隨著模型和數據規模增加,出現小模型不具備的新技能
例如:理解笑話、多步推理、基本邏輯推演
訓練挑戰
資料規模巨大:數千億詞,需強大運算資源
高品質資料的重要性:不只數量,還要去除低品質或有害資料
計算成本高:需要數百張 GPU/TPU 並行訓練,花費數百萬美元
結語
大規模語料訓練 = 強大語言模型的基石
模型透過 下一詞預測 吸收人類語言的精華 → 具備生成連貫語句與廣泛知識的能力
雖然資料量不是唯一因素,但沒有前所未有的語料規模,就不會有 ChatGPT 這種 博聞強識 的模型出現。
下一步:我們將深入探討 ChatGPT 模型的演進歷程。


 iThome鐵人賽
iThome鐵人賽