在我們開始實作 RAG 系統之前,首先要先安裝好相關套件,尤其是我們的第一步是處理 知識文件的任務,許多PDF處理工具需要用到OCR相關技術,會有一些比較特別的步驟要先準備。
筆者提供目前使用到之套件與相關版本:
# PDF處理核心套件
pymupdf==1.25.5
img2table==1.4.1
pytesseract==0.3.13
pillow==11.2.1
opencv-contrib-python==4.11.0.86
# 數據處理
numpy==1.26.4
pandas==2.2.3
# 向量化
torch==2.6.0
transformers==4.51.3
sentence-transformers==4.1.0
flagembedding==1.3.4
huggingface-hub==0.31.1
# LangChain
langchain-community==0.3.23
langchain-core==0.3.59
langchain-huggingface==0.2.0
# 向量資料庫
qdrant-client==1.14.3
chromadb==1.1.0
# 其他必要工具
python-dotenv==1.1.0
pydantic==2.11.4
tqdm==4.67.1
# UI
streamlit==1.28.1
若 PDF 是掃描影像或內含影像表格,需要用 OCR 才能擷取文字。Tesseract 是常見的免費 OCR 引擎,但必須注意語言包(traineddata)的安裝,預設是只有英文,要處理繁中是一定要自己處理的。
macOS (Homebrew)
brew install tesseract
Ubuntu / Debian
sudo apt-get update
sudo apt-get install tesseract-ocr
Windows
請從 Tesseract 官方 repo 或 release 下載安裝檔,並記得把安裝目錄加入系統 PATH(例如 C:\Program Files\Tesseract-OCR)。
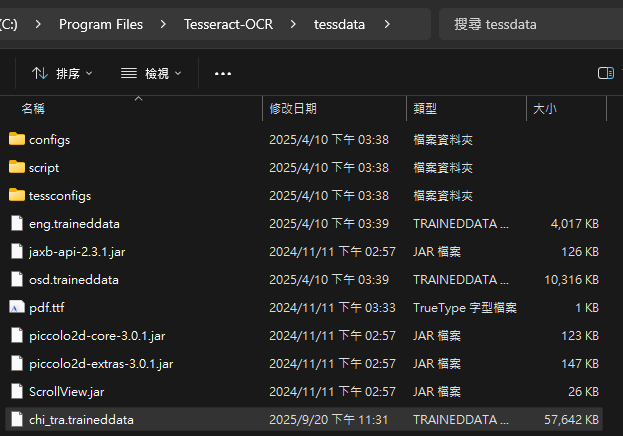
繁體中文 chi_tra.traineddata 需額外下載並放到 tessdata 資料夾。
下載位置(官方 repo):
https://github.com/tesseract-ocr/tessdata
把 chi_tra.traineddata 放到 Tesseract 的 tessdata 資料夾,例如:
/usr/share/tesseract-ocr/4.00/tessdata/ 或 /usr/share/tessdata/
C:\Program Files\Tesseract-OCR\tessdata\
完成後,可以用下列指令確認已安裝的語言列表:
tesseract --list-langs

如果你想在 Python 裡確認
import pytesseract
print(pytesseract.get_languages(config=''))
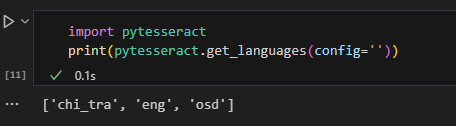
tesseract --list-langs 能看到 chi_tra。TESSDATA_PREFIX 環境變數或把 tessdata 資料夾放在安裝路徑下。今天要完成的前置工作:
chi_tra 已安裝。PyMuPDF、img2table、pandas、pytesseract、pdf2image。tesseract --list-langs 可以看到 eng 與 chi_tra。下一篇我們會把這些工具實際串起來:逐頁檢測表格 → 過濾表格文字 → 儲存純文字與表格(結構化),並把結果整理成適合存入向量資料庫(Chroma)的 documents 格式,然後就快速用ChromaDB+OpenAI+Streamlit來完成簡單的POC吧!


 iThome鐵人賽
iThome鐵人賽