我們昨天已經安裝了Grafana和Prometheus,今天我們來讓LangSmith跑起來吧!
LangSmith 是由 LangChain 團隊推出的一套 LLM 應用監控與評估平台。
它能幫助開發者追蹤、觀察、評估並持續優化基於 LangChain 的 Agent 或 RAG 系統。
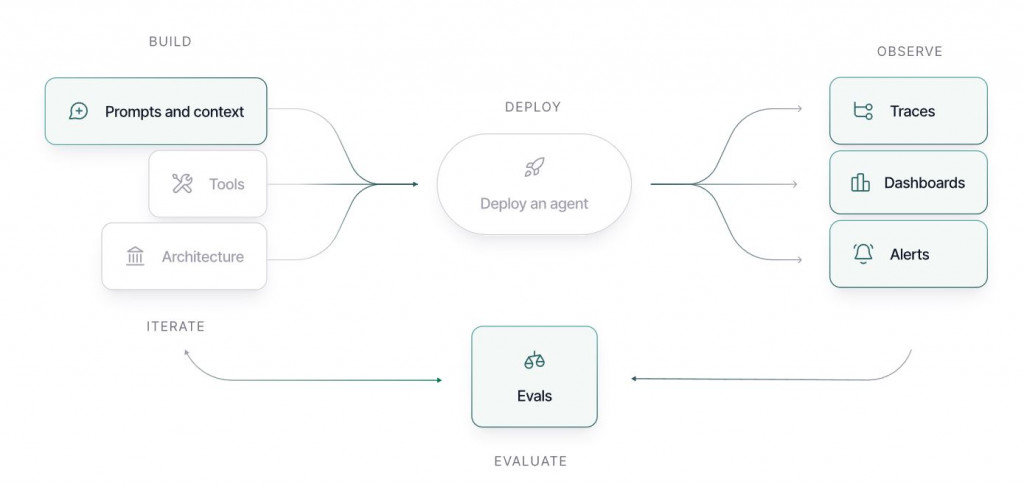
LangSmith 的典型工作流程分為四個階段:
整體循環如下圖所示:
在使用 LangSmith 進行追蹤或評估前,必須先取得 API Key,以便讓本地或雲端應用能與 LangSmith 平台連線。
以下是詳細步驟:
前往 https://smith.langchain.com 並登入帳號。
點擊左下角的 Settings(設定) 圖示。
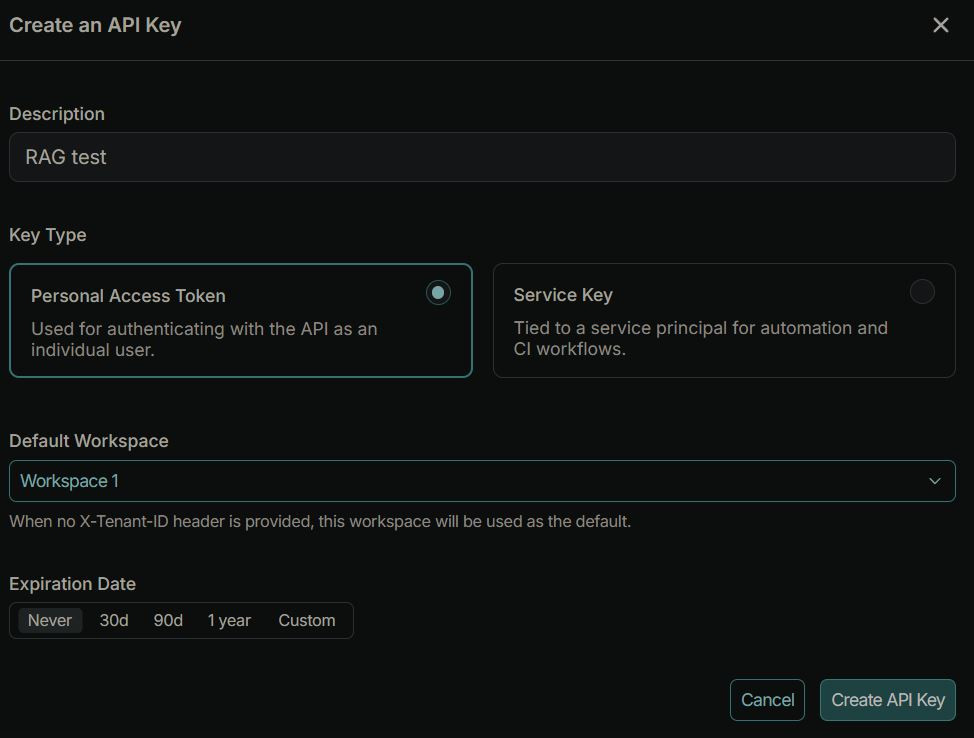
在「API Keys」區域中,點擊 + API Key。

這部份可以做一些API Key的管理,例如workspace或是到期時間(Expiration Date),筆者用來測試所以都先用默認的,決定好後點下Create API Key。
有了API Key我們就可以來測試囉! 以下用一個Python範例展示如何在本地使用 Ollama + LangSmith 來追蹤 LLM 執行過程。
pip install langsmith langchain langchain-community
ollama list
# 有執行的話下面會顯示
NAME ID SIZE MODIFIED
cwchang/llama-3-taiwan-8b-instruct:latest 3f0396cc71cc 5.7 GB 4 days ago
import os
from langchain_community.llms import Ollama
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
# 設置 LangSmith
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
# 注意替換成你的API key
os.environ["LANGCHAIN_API_KEY"] = "Your_LangSmith_API_Key"
# 這邊"LANGCHAIN_PROJECT"名稱會顯示在你的langSmith上
os.environ["LANGCHAIN_PROJECT"] = "ollama-local-project"
# 使用本地 Ollama(使用你選擇的模型名稱)
llm = Ollama(model="cwchang/llama-3-taiwan-8b-instruct:latest", base_url="http://localhost:11434")
prompt = PromptTemplate(
input_variables=["question"],
template="請回答:{question}"
)
chain = LLMChain(llm=llm, prompt=prompt)
response = chain.run("什麼是機器學習?")
python LangSmith_test.py
前往LangSmith Dashboard
LangSmith Dashboard
登入後就會在TracingProject裡面看到新增的專案ollama-local-project
點擊專案名稱,即可於Traces處監控剛剛的測試結果
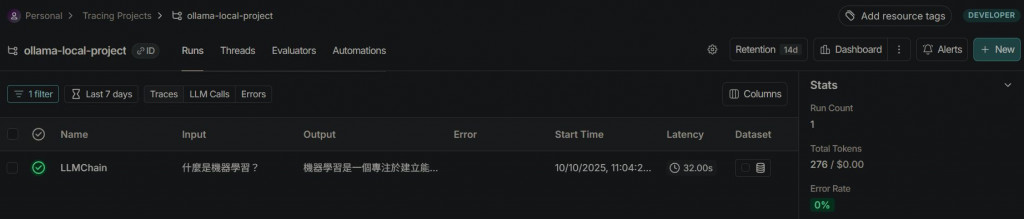
可以清楚看到幾個重要的指標: input, output, Error,Latency, Tokens, First Token,下面我們用個表格做簡單說明:
| 指標名稱 | 說明 | 代表意義 | 常見用途 |
|---|---|---|---|
| Input | 模型接收到的輸入內容(Prompt、上下文、Tool Input 等) | 顯示模型在該次呼叫中接收到的原始資料,方便檢查 prompt 是否正確傳入。 | 驗證 prompt 格式與內容正確性 |
| Output | 模型回傳的輸出結果 | 展示模型生成的回覆內容或執行結果。 | 評估生成品質、確認輸出是否合理 |
| Error | 執行過程中出現的錯誤訊息 | 若執行成功則為空,若模型、API 或工具調用出錯則會顯示錯誤資訊。 | 偵錯、監控穩定性、建立 Alert 通知 |
| Latency | 從呼叫開始到回傳完整結果所耗時間(毫秒/秒) | 反映整體反應速度,包括網路延遲與模型推理時間。 | 優化效能、監測系統延遲 |
| Tokens | 該次執行所使用的 token 數量(含輸入與輸出) | 可幫助估算成本與理解模型的輸入/輸出長度。 | 成本分析、Prompt 壓縮、效能調整 |
| First Token | 模型產生第一個 token 所需時間 | 衡量模型開始輸出的延遲時間,越短代表回應啟動越快。 | 優化使用者體驗、測試模型反應速度 |
到了這邊您就可以監控LLM的運行狀況囉!
細心的讀者可能已經注意到,LangSmith 其實不是完全地端的方案。沒錯,目前只有企業版 (Enterprise) 才能支援自建部署,而一般開發者使用的仍是雲端 SaaS 模式。
因此,對於我們這次要打造的「全地端 LLM 監控系統」,LangSmith 雖然概念完善、介面漂亮,但並不完全符合需求。不過,透過了解它的設計思路,我們也能掌握監控架構該具備的要素。接下來,我們會聚焦在 Grafana + Prometheus 的實作上,打造真正離線可用的監控解決方案。


 iThome鐵人賽
iThome鐵人賽