昨天的最後一段測試,今天我們試著把所有功能串接起來,並使用Streamlit作呈現!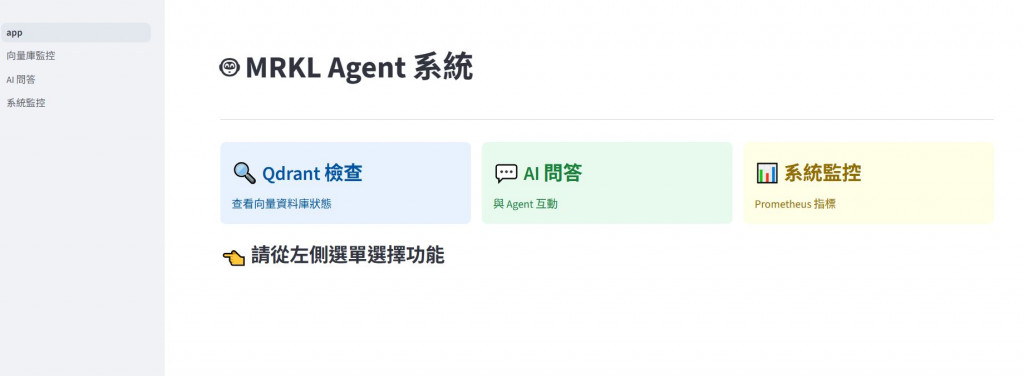
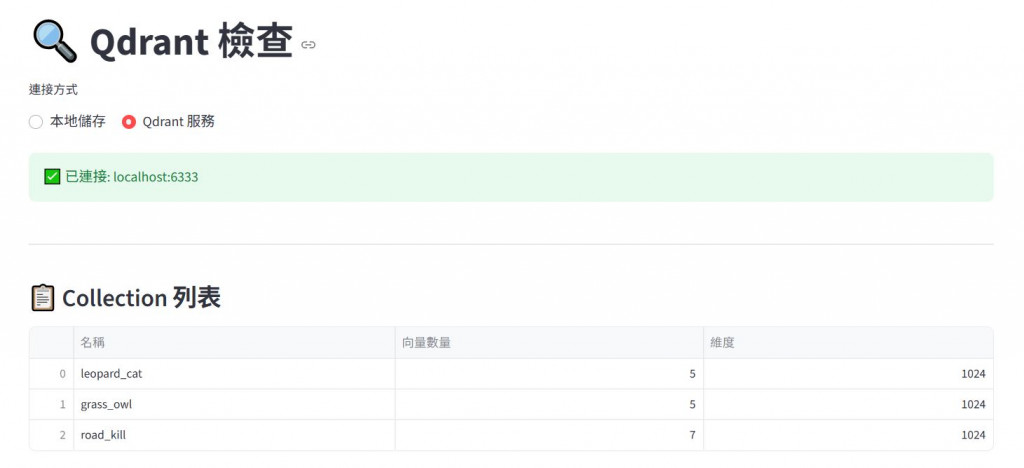
Agentic RAG系統,最重要的知識就存放在向量資料庫中,我們這次的選型是使用Qdrant,相關選擇方式可以參考文章Day 5: 向量資料庫很重要嗎?可以怎麼挑呢?以及Day 16:向量資料庫進階分析: Qdrant,我們做出一個可以簡單檢查的頁面:
在Agent這段我們有兩個議題,一個是地端的LLM。因為運算資源的關係,我們不一定有足夠的資源運行大模型,但筆者實測,其實輕量的模型也能做到一定程度的推理,搭配Agent flow後,可以解決更複雜的問題!
而也因為實務上我們確實會遇到複雜的問題,要讓模型能夠思考後做更好的決策,甚至有調用工具的能力,將RAG和Agent flow結合在一起成為Agentic RAG就是一種解決方案!相關資訊可以參考先前的Day 17: 大家都在Agent,那你知道什麼是Agentic RAG嗎?。
在這裡我們選用MRKL這個Agent flow,並把和Qdrant調用資料的Retrieval功能包裝成tools給Agent調用,相關資料則可以參考Day 19: AI Agent為何如此神奇? 一起來認識MRKL (唸Miracle)當遇到不同問題時,模型會調用不同資料來源。(我們只做了簡單的問題來示意,讀者可以思考這樣的功能在實務上能解決那些問題)
我們透過Prometheus搭配Grafana做系統的監控,透過在運行的腳本內加入metrics來計算我們關注的資訊,並存取在Prometheus裡,我們可以透過Grafana或是在Streamlit的頁面上做簡單的顯示,如下示範: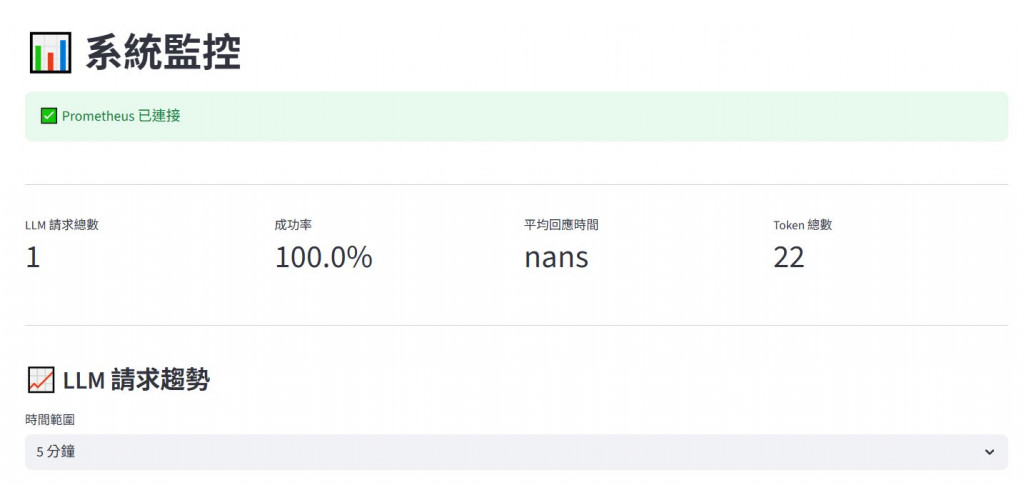
這些功能看似簡單,串接在一起其實也有很多的細節,雖然筆者先前在其他系統已完成整個流程,但自己要在地端重新複線,又再次踩了一整路的坑。
有限的運算資源,地端各套系統之間的串接衝突,Qdrant啟動的方式,其實都有些細節,筆者也在這次,多學習了一些系統與監控的知識,受益良多。
經過了30天,原先信誓旦旦要把一系統做起來,最後卻是匆匆忙忙擠出了一個還有些串接問題的版本,深深覺得一開始太小看鐵人賽,雖然一路和AI搭配操作,卻常常不小心把100行的程式變成500行,跟著Claude把bug越修越大隻,看來自己要和AI協作還是有一些功力要訓練(笑。
而一路上最感謝的還是組員 Shirley和Harper一起努力,剛好在開賽的途中遇到家庭變故,還好有兩位夥伴打氣支持,雖然不如自己原先預期,但還是順利完成了整個系列。
也感謝撥空閱讀的前輩們,這次系列其實結構有些亂跳,也有些地方內容尚不完整,如果有興趣的文章還請不吝指教,相關的程式碼,後續筆者還會陸續補上加入,期待自己下次能準備得更齊全,也能再次挑戰鐵人賽!


 iThome鐵人賽
iThome鐵人賽