前言
昨天我們完成了邏輯迴歸模型的建立,並試著用它預測單筆資料。今天,我們將深入探索模型內部,主要目標有三個:
一、分析特徵權重(Feature Coefficient)
為什麼要看特徵權重?
邏輯迴歸會對每個特徵計算一個「權重(coefficient)」,數字正負表示特徵對預測結果的影響方向:
這樣做的目的:
程式碼範例與說明
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
# 建立模型,設定最大迭代次數為500
# max_iter=500 是為了確保模型能收斂,避免迭代不足導致警告
model = LogisticRegression(max_iter=500)
# 用訓練資料訓練模型
# fit() 會自動調整每個特徵的權重,使模型能夠盡量正確預測 y_train
model.fit(X_train, y_train)
# 取得模型學到的權重
coefficients = model.coef_[0]
# 生成特徵名稱,如果使用 NumPy 陣列沒有 columns 屬性
feature_names = [f"Feature {i}" for i in range(X_train.shape[1])]
# 列出每個特徵與其權重
for name, coef in zip(feature_names, coefficients):
print(f"{name}: {coef:.3f}")
程式碼解釋
可視化特徵權重
plt.figure(figsize=(8,5))
plt.bar(feature_names, coefficients)
plt.xlabel("特徵")
plt.ylabel("權重")
plt.title("邏輯迴歸特徵權重")
plt.xticks(rotation=45)
plt.show()
解釋:
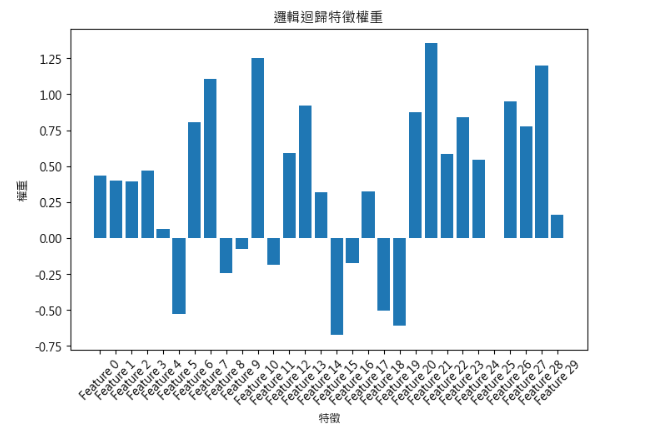
二、混淆矩陣(Confusion Matrix)與分類評估指標
正例(Positive)與負例(Negative?
在分類問題中,我們通常會把目標分成兩類:
1.正例(Positive, P)
代表我們關注的目標事件發生
例子:
2.負例(Negative, N)
代表目標事件未發生
例子:
為什麼要區分正負例?
數學例子
假設我們要預測腫瘤是否為惡性(正例 = 惡性,負例 = 良性),測試資料有 10 筆: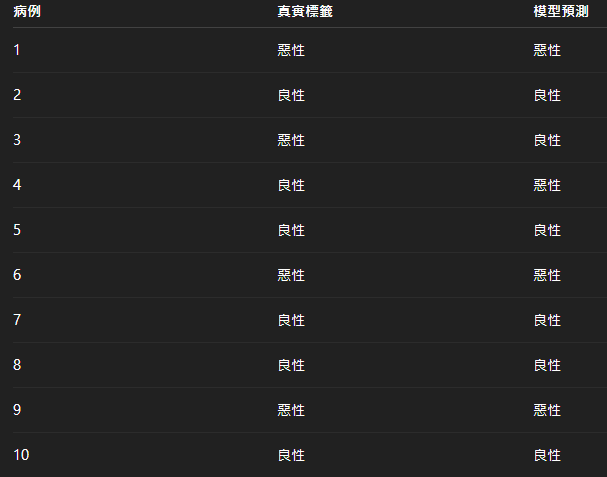
常用分類評估指標公式
準確率(Accuracy)
衡量模型整體預測正確的比例:Accuracy=(TP+TN)/(TP+TN+FP+FN)
精確率(Precision)
衡量模型預測為正例的樣本中,有多少是真正的正例:Precision=𝑇𝑃/(𝑇𝑃+𝐹𝑃)
召回率(Recall / Sensitivity)
衡量所有正例中,有多少被模型正確預測:Recall=𝑇𝑃/(𝑇𝑃+𝐹𝑁)
F1 分數(F1 Score)
精確率與召回率的調和平均,綜合考量模型的正例預測能力:F1 Score=2×Precision×Recall/(Precision+Recall)
程式碼範例
from sklearn.metrics import accuracy_score, confusion_matrix, ConfusionMatrixDisplay
from sklearn.metrics import precision_score, recall_score, f1_score
# 使用模型預測測試集
y_pred = model.predict(X_test)
# 計算整體準確率
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.3f}")
# 混淆矩陣
cm = confusion_matrix(y_test, y_pred)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=[0,1])
disp.plot(cmap=plt.cm.Blues)
plt.show()
# 計算其他指標
precision = precision_score(y_test, y_pred) # 精確率
recall = recall_score(y_test, y_pred) # 召回率
f1 = f1_score(y_test, y_pred) # F1 分數
print(f"Precision: {precision:.3f}")
print(f"Recall: {recall:.3f}")
print(f"F1 Score: {f1:.3f}")
程式碼解釋
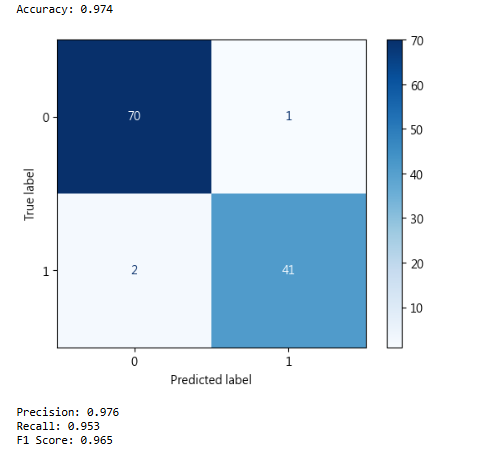
小結
今天,我們完成了邏輯迴歸模型的深入分析:

