目標先講清楚:
我要把接下來的 Agent 開發路線與工作流寫清楚,並回答一個常見問題:既然 LLM 有長上下文(long context),為什麼還要拆成多個 Agent?
長上下文≠萬能。實務上,上下文失效(context fail) 會讓單一超大 Agent 變得脆弱,常見四種症狀是:
另一方面,最新的多代理系統實務也印證:把任務拆成「多個協作的專注代理」,各自有清楚的工具、提示與探索路徑,會比單一巨無霸更穩、更好排錯。Anthropic 在其 Multi-Agent Research 的工程文章裡,詳細談到如何用「一個規劃代理 + 多個並行子代理」來做檢索與調查,以及在協調、評估與可靠性上的工程教訓。 (Anthropic)
參考「Agentic Design Patterns / Prompt Chaining」等資源,我把第一章常用的提示與流程設計要點蒐整成五步: (Agentic Design Patterns)
這套「分而治之 + 中間態可驗證」的做法,正是多代理工作流得以可測試、可維運的基礎;與 Anthropic 的多代理實戰脈絡相呼應。 (Anthropic)
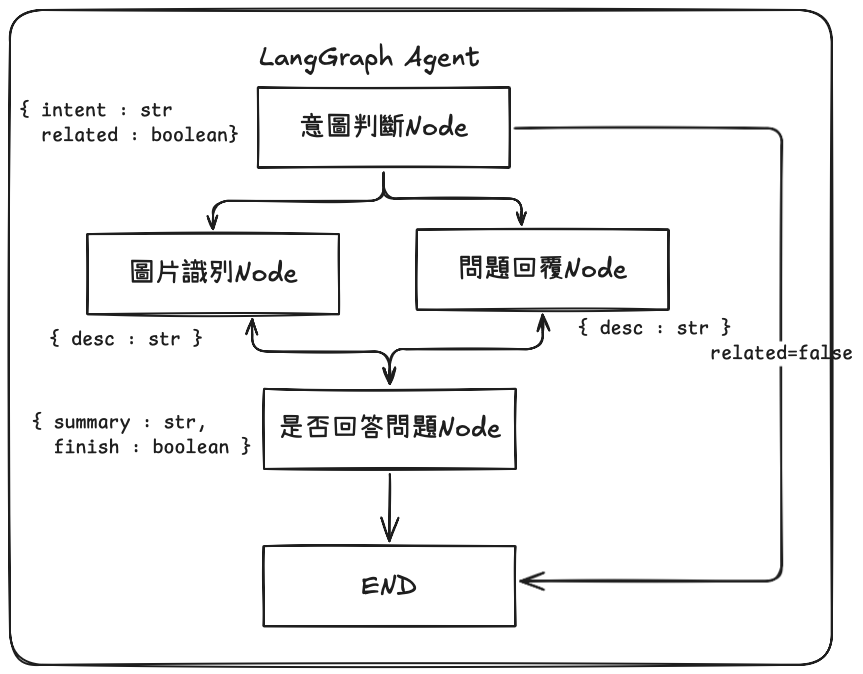
先上流程,再逐步加工具與記憶;每個子代理只處理一件事,輸出必為結構化。
這種 「監督者 + 專注子代理」 的拓樸,和產業實務的 Orchestrator–Worker 多代理設計一致,能隔離責任、清楚觀測、方便回滾。 (Anthropic)
實際在開發過程中,也會依照測試結果對workflow進行調整.
接下來會介紹常用到的結構化輸出常使用的方式