
目標先講清楚:
Drew Breunig怎麼做到將一大串的system prompt使用DSPy去結構化,提高system prompt維護性
在 Day 10 提到:「長而清楚的結構化提示」雖然能提高表現,但Drew Breunig提到這樣的長字串可讀性、可維護性、跨模型可攜性都很糟。
Drew Breunig 分析了 OpenAI SWE-Bench 的 prompt 組成: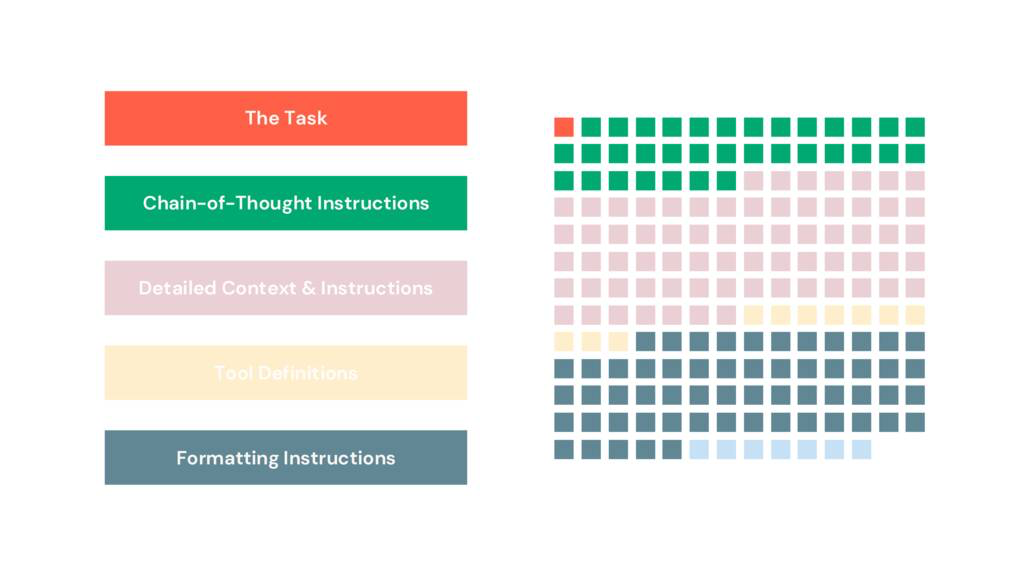
並示範用 DSPy 把「字串中的結構與規則」抽回程式模組管理。核心思路是:
理念:DSPY提供許多Module(挖空的Prompt template),使用者只需要專注在輸入、輸出的結構跟「描述」處理邏輯
place_one 與 place_two 是否同一地點,並給出信心等級。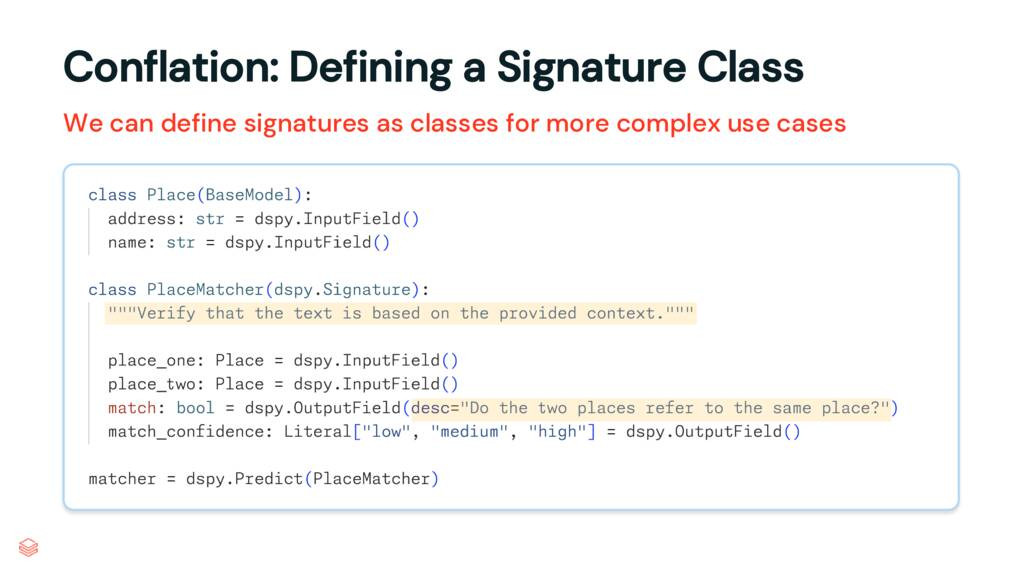
PlaceMatcher(dspy.Signature)
dspy. Predict (PlaceMatcher)
DSPy組的Prompt,由 Signature + Module 組出,執行過程中不會顯示
可以使用
adapter.format(signature, demos, inputs)查看
Your input fields are:
1. `place_one` (Place): {...JSON schema...}
2. `place_two` (Place): {...JSON schema...}
Your output fields are:
1. `match` (bool): Do the two places refer to the same place?
2. `match_confidence` (Literal['low', 'medium', 'high'])
All interactions will be structured in the following way...
[[ ## place_one ## ]]
{place_one}
[[ ## place_two ## ]]
{place_two}
[[ ## match ## ]]
{match}
[[ ## match_confidence ## ]]
{match_confidence}
[[ ## completed ## ]]
In adhering to this structure, your objective is:
Verify that the text is based on the provided context.
使用者訊息
[[ ## place_one ## ]]
{"address": "123 Main St", "name": "Coffee Shop"}
[[ ## place_two ## ]]
{"address": "123 Main Street", "name": "Coffee Shop"}
Respond with the corresponding output fields...
模型回覆(經 JSONAdapter 解析)
{
"match": true,
"match_confidence": "high"
}
重點:Signature 明確定義欄位與任務;Module 保證訊息骨架與輸出格式一致。從此不再手改 700 行字串,而是用程式宣告與型別來治理。
理念:
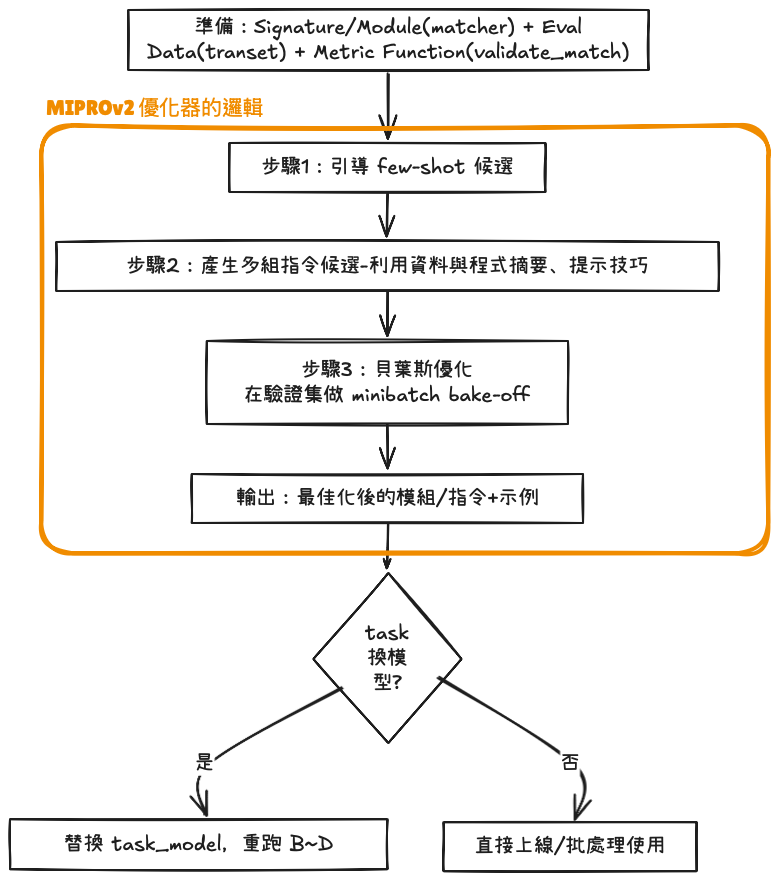

prompt_model:產生指令候選(寫 prompt 的「作者」)task_model:執行任務與優化(實際跑任務的「選手」)# example output
artifact = {
"signature": "PlaceMatcher",
"instruction": """
Given two records representing places or businesses—each with at least a name and address—analyze...
(這裡是一大段經過優化的指令文字,約數百 tokens)
""",
"few_shot_examples": [
{
"inputs": {
"place_one": {"name": "Peachtree Café", "address": "123 Peachtree St NE, Atlanta"},
"place_two": {"name": "Peach Tree Coffee & Cafe", "address": "125 Peachtree Street NE, Atlanta"}
},
"gold_output": {"match": True, "match_confidence": "medium"}
},
{
"inputs": { ... },
"gold_output": { ... }
}
],
"settings": {
"task_model": "gpt-4o-mini@2025-xx-xx",
"prompt_model": "gpt-4o@2025-xx-xx",
"search/trials": 48,
"metric": "F1_place_match"
}
}
# 假設框架提供 save/load(名稱依版本)
dspy.save(matcher_opt, "place_matcher_opt.json")
# 之後可:
matcher_opt = dspy.load("place_matcher_opt.json")
實務上你會把
matcher_opt(優化後模組)直接上線使用。當新模型出現時,只需替換task_model,再跑一次三步驟優化,自動產出對新模型最合適的指令+示例。
agents的context包含很多的資料,因此,針對「LangChain 1.0」推出的新概念:Agent Middleware(代理中介層)- 目標是解決傳統 agent 抽象在進入生產環境時「無法精細控制 context engineering」的痛點,感到好奇.
