
目標先講清楚:
在AI系統開發完成後,Creating a LLM-as-a-Judge That Drives Business Results依照跟30+公司合作的經驗,分享如何建立Judge Agent,自動化來評估大規模的互動數據
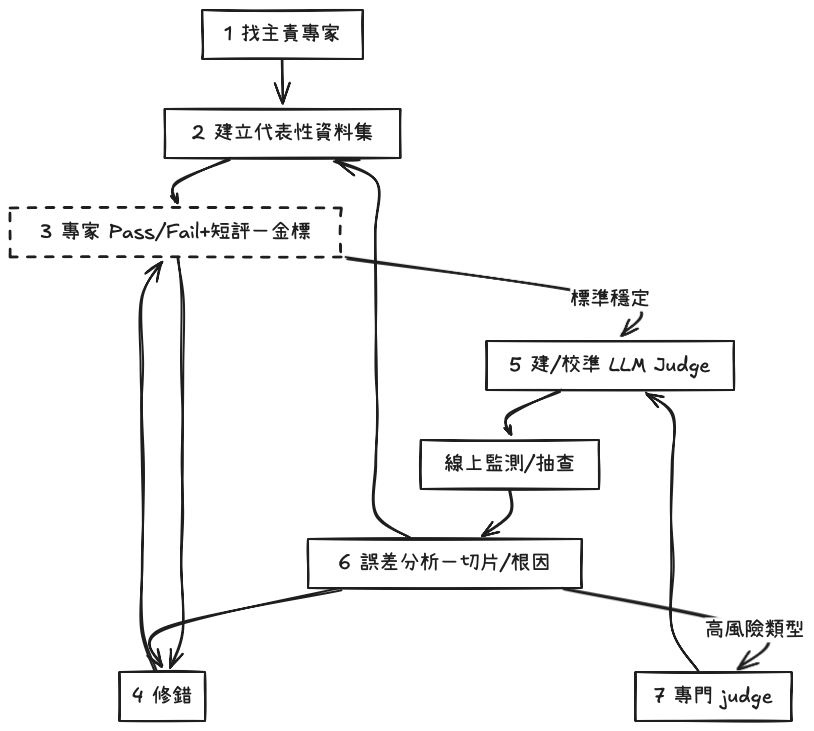
找主責領域專家
一個能「定義 pass/fail」的人,條件:領域專業知識、能代表目標使用者
建立代表性資料集
| 功能 | 情境 | 人設 | System prompt | 隱含假設 |
|---|---|---|---|---|
| 訂單追蹤 | 提供了無效資料 | 挫折的客戶 | 以不耐、急躁的短句要求查詢訂單 #1234567890 的狀態,並暗示曾有不佳經驗。 | 系統中不存在此訂單號。 |
這個步驟完成,可得:測試情境、測試輸入資料集
| 使用者與 AI 互動 | 判斷 | 短評 |
|---|---|---|
| User:「我需要取消下週的機票預訂。」AI:「已為你取消下週的機票,確認信已寄出。」 | 通過(Pass) | AI 成功完成主要目標(取消並寄出確認)。但在執行前應先再次確認,以避免誤取消;加入確認步驟可提升使用者安全。 |
這個步驟完成,可得:專家標注的測試資料集
這個步驟完成,可得:功能正常、通過測試情境的系統
{{guidelines}}(把條款濃縮成 grading notes,讓 LLM judge 知道該抓哪些關鍵特徵)。<nlq> / <query> / <critique>)。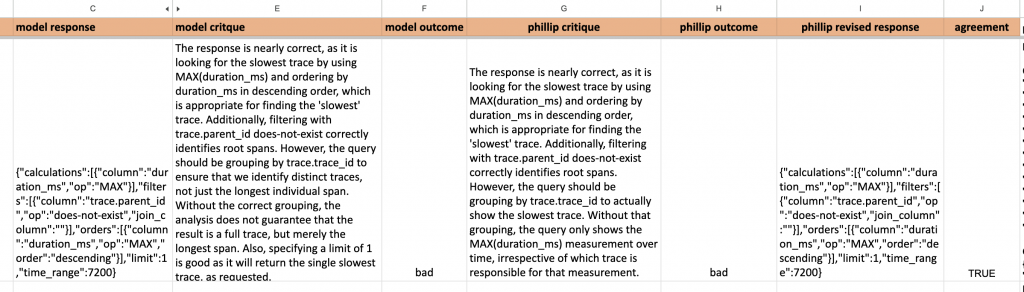
You are a Honeycomb query evaluator with advanced capabilities to judge if a query is good or not. You understand the nuances of the Honeycomb query language, including what is likely to be most useful from an analytics perspective.
Here is information about the Honeycomb query language: {{query_language_info}}
Here are some guidelines for evaluating queries: {{guidelines}}
Example evaluations:
<examples>
<example-1>
<nlq>show me traces where ip is 10.0.2.90</nlq>
<query>
{
"breakdowns": ["trace.trace_id"],
"calculations": [{"op": "COUNT"}],
"filters": [{"column": "net.host.ip", "op": "=", "value": "10.0.2.90"}]
}
</query>
<critique>
{
"critique": "The query correctly filters for traces with an IP address of 10.0.2.90 and counts the occurrences of those traces, grouped by trace.trace_id. The response is good as it meets the requirement of showing traces from a specific IP address without additional complexities.",
"outcome": "good"
}
</critique>
</example-1>
<example-2>
<nlq>show me slowest trace</nlq>
<query>
{
"calculations": [{"column": "duration_ms", "op": "MAX"}],
"orders": [{"column": "duration_ms", "op": "MAX", "order": "descending"}],
"limit": 1
}
</query>
<critique>
{
"critique": "While the query attempts to find the slowest trace using MAX(duration_ms) and ordering correctly, it fails to group by trace.trace_id. Without this grouping, the query only shows the MAX(duration_ms) measurement over time, not the actual slowest trace.",
"outcome": "bad"
}
</critique>
</example-2>
<example-3>
<nlq>count window-hash where window-hash exists per hour</nlq>
<query>
{
"breakdowns": ["window-hash"],
"calculations": [{"op": "COUNT"}],
"filters": [{"column": "window-hash", "op": "exists"}],
"time_range": 3600
}
</query>
<critique>
{
"critique": "While the query correctly counts window-hash occurrences, the time_range of 3600 seconds (1 hour) is insufficient for per-hour analysis. When we say 'per hour', we need a time_range of at least 36000 seconds to show meaningful hourly patterns.",
"outcome": "bad"
}
</critique>
</example-3>
</examples>
For the following query, first write a detailed critique explaining your reasoning, then provide a pass/fail judgment in the same format as above.
<nlq>{{user_input}}</nlq>
<query>
{{generated_query}}
</query>
<critique>
這個步驟完成,可得:可自動評分的 judge prompt。
| 根因 | 次數 | 百分比 |
|---|---|---|
| 缺少使用者教育 | 8 | 40% |
| 驗證/存取問題 | 6 | 30% |
| 情境(脈絡)處理不佳 | 4 | 20% |
| 錯誤訊息不足 | 2 | 10% |
實務上依照以上步驟建立Judge Agent,用在產品上線後的monitoring,成本真的很高
可以:
那針對POC的專案,可以怎麼規劃簡單的Evaluate case呢?會介紹langsmith的agent eval案例
1.Creating a LLM-as-a-Judge That Drives Business Results
2.Enhancing LLM-as-a-Judge with Grading Notes
3.An LLM-as-Judge Won't Save The Product—Fixing Your Process Will
