
目標先講清楚:
- 針對 Day 26 Hamel提供AI服務評估的方法論,這邊改使用LangSmith實現
- 但就算有以下的工具,驗證案例跟資料收集還是需要人工
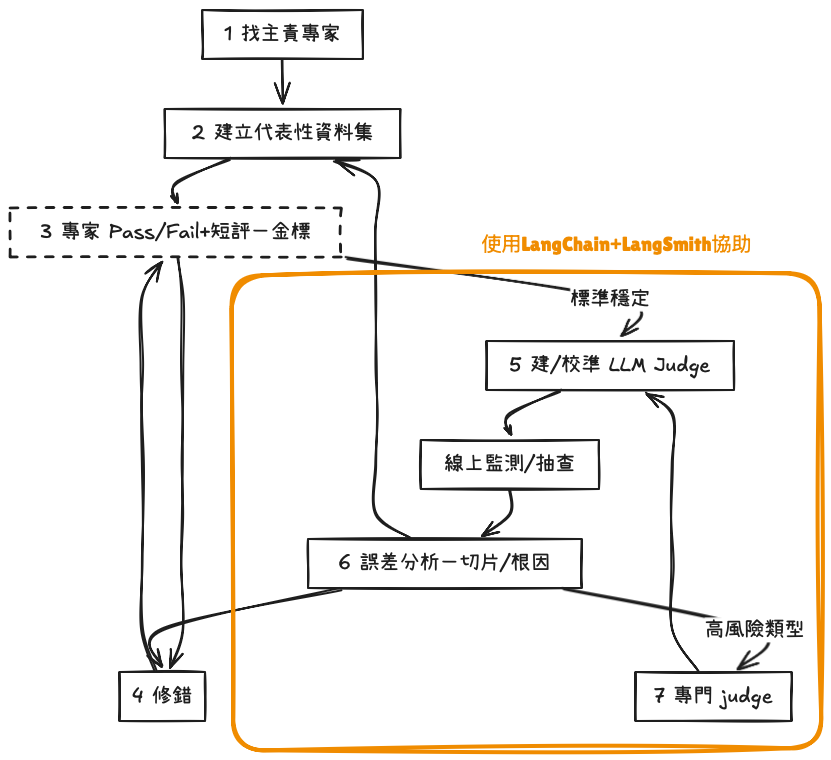
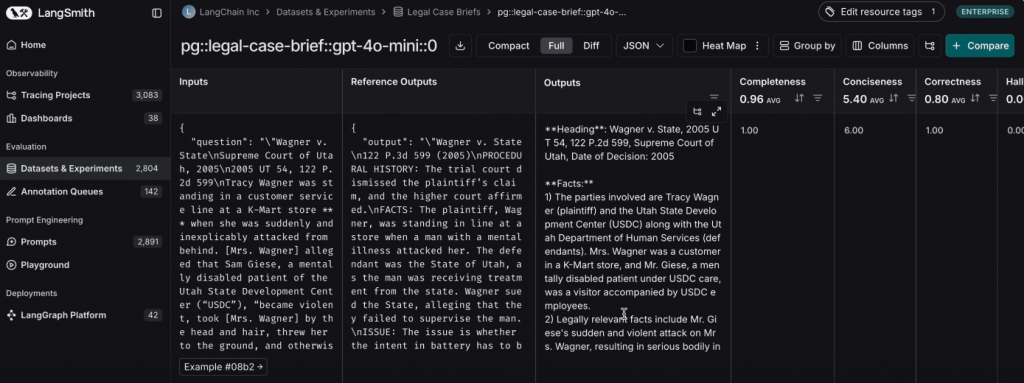
當你已有測試案例與資料、希望快速對 Agent(或任意 LLM 應用)做系統化評估時,LangSmith 提供了開箱即用的 UI 與可觀測能力,能把「資料集 → 批次執行 → 評估器 → 指標與報表 → 追蹤回寫」串成一條龍。
實務上可結合LangChain開源框架(如
openevals、evals-agent),把評估邏輯維持在程式碼層。
可以達成:
重點
為什麼要看「軌跡」
AgentEvals提供的評估方式
1:軌跡匹配(Trajectory Match)- create_trajectory_match_evaluator
| 模式 | 匹配標準 | 適用情境 |
|---|---|---|
| Strict | 工具集合+順序均需完全相同 | 嚴格 SOP(如先查政策再動作) |
| Unorder | 工具集合相同,順序不拘 | 動作彼此獨立,順序不影響 |
| Superset | 實際輸出是參考的超集 | 允許額外調用,但關鍵工具必須出現 |
| Subset | 實際輸出是參考的子集 | 強調效率,避免多餘工具 |
2:LLM-as-Judge - create_trajectory_llm_as_judge
最後再把結果傳回langSmith
為什麼需要多輪模擬
模擬所需要素
create_multiturn_simulator,以 Persona 提示(例:不滿、要求退款的顧客)模擬使用者的回覆。create_llm_as_judge)。最後再把結果傳回langSmith
目的
操作步驟
回到context的部分,透過Drew Breunig 在 Databricks 大會分享DSPy的用法,評估DSPy可以怎麼用在system prompt
1.langchain-ai - openevals
2.langChain-Evaluation
3.Improve LLM-as-judge evaluators using human feedback
4.How to evaluate agent trajectories with AgentEvals
5.Simulating & Evaluating Multi turn Conversations
6.No Code LangSmith Evaluations
