
今天我們進入資料清理與特徵工程,針對數值與類別欄位做合適的轉換,讓模型能更好地學習。
在機器學習中,如果不同數值欄位的尺度差異過大,會影響模型收斂速度甚至表現,因此我們通常會先做標準化(Standardization),讓每個欄位的平均值變成 0、標準差變成 1。
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
# 各自抓數值欄
num_cols_train = train.select_dtypes(include=["number"]).columns.tolist()
num_cols_test = test.select_dtypes(include=["number"]).columns.tolist()
missing_in_test = [c for c in num_cols_train if c not in test.columns]
print("只在 train 出現的數值欄:", missing_in_test)
# 只保留 train & test 共同擁有的數值欄
common_num_cols = sorted(set(num_cols_train) & set(num_cols_test))
# 標準化
train[common_num_cols] = scaler.fit_transform(train[common_num_cols])
test[common_num_cols] = scaler.transform(test[common_num_cols])
fit_transform(train[num_cols]) 代表的是兩個步驟:fit():去「學習」訓練資料的平均值、標準差(像這樣的統計量),transform():把訓練(train)資料「轉換」成標準化後的版本(Z-score 標準化)。這個步驟只會在訓練資料上做,因為你不能偷看測試資料。
transform(test[num_cols])則是指使用訓練集(train)建立好的統一規則(平均數與標準差)來轉換測試集(test),確保測試資料與訓練資料在同一個標準下。不可以對測試集再使用 fit(),否則就導致資料外洩(data leakage),造成模型已經知道標準答案,進一步造成評估不準確!
執行完成後,我們可以看到 rule_violation 這個欄位只出現在 train,沒有出現在 test,這正是我們預期的結果。因為 rule_violation 就是這次的目標變數 y,它代表要預測的答案,不應該作為模型的輸入特徵。接下來在後面進行編碼與特徵工程時,都會將它排除。
類別型欄位必須轉換為數值形式,否則大多數機器學習模型無法直接處理文字特徵。先前我們曾示範過 One-Hot Encoding,今天將會進一步引入 Frequency Encoding 與 Target Encoding,並比較三種方法對資料維度與模型表現的影響,評估哪種編碼策略最適合目前的任務。
將每個類別展開為獨立的 0/1 欄位
import pandas as pd
# 1. 先丟掉目標欄位 rule_violation
train_no_target = train.drop(columns=["rule_violation"])
# 2. 找出類別欄位
cat_cols = train.select_dtypes(include=["object","category","bool"]).columns.tolist()
print("類別欄位:", cat_cols)
# 3. 對類別欄位做 One-Hot Encoding
train_oh = pd.get_dummies(train_no_target, columns=cat_cols)
# 4. 檢查結果
print("原始欄位數:", train_no_target.shape[1])
print("One-Hot 後欄位數:", train_oh.shape[1])
display(train_oh.head())

將每個類別替換為其在資料中出現的頻率,保留類別出現的比例,能降低維度。
import pandas as pd
# 1. 先丟掉目標欄位 rule_violation
train_no_target = train.drop(columns=["rule_violation"])
# 2. 找出類別欄位
cat_cols = train.select_dtypes(include=["object","category","bool"]).columns.tolist()
print("類別欄位:", cat_cols)
# 3. 對每個類別欄位做 Frequency Encoding
train_fe = train_no_target.copy()
for col in cat_cols:
freq_map = train_fe[col].value_counts(normalize=True) # normalize=True → 轉換成比例(0~1)
train_fe[col] = train_fe[col].map(freq_map)
# 4. 檢查結果
print("類別欄位數:", len(cat_cols))
display(train_fe[cat_cols].head())
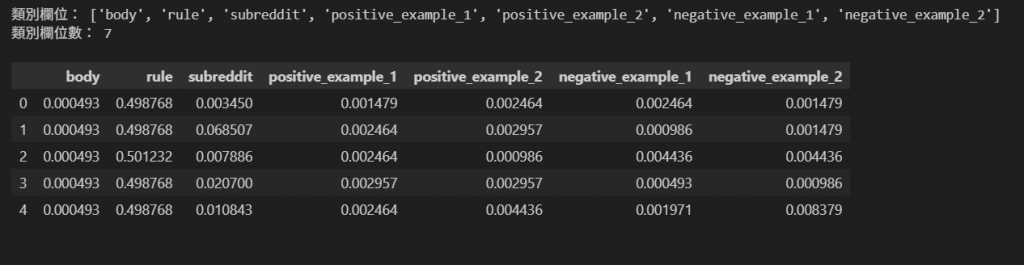
利用目標變數(target variable)的資訊,將類別特徵轉換成數值。
將每個類別值替換為該類別對應的目標變數平均值或加權統計量,以捕捉類別與預測目標之間的關聯。
import pandas as pd
# 1. 先丟掉目標欄位 rule_violation
train_no_target = train.drop(columns=["rule_violation"])
# 2. 找出類別欄位
cat_cols = train.select_dtypes(include=["object","category","bool"]).columns.tolist()
print("類別欄位:", cat_cols)
# 3. 對每個類別欄位做 Frequency Encoding
train_fe = train_no_target.copy()
for col in cat_cols:
freq_map = train_fe[col].value_counts(normalize=True) # normalize=True → 轉換成比例(0~1)
train_fe[col] = train_fe[col].map(freq_map)
# 4. 檢查結果
print("類別欄位數:", len(cat_cols))
display(train_fe[cat_cols].head())

| 編碼方式 | 優點 | 缺點 |
|---|---|---|
| One-Hot | 簡單直觀 | 高維度、訓練時間長 |
| Frequency | 降低維度、計算快 | 無法捕捉與目標的關聯 |
| Target Encoding | 捕捉類別與目標的關係、提升模型性能 | 容易過擬合、需交叉驗證 |
今天我們完成了:
完成這兩步之後,資料已經變成適合輸入機器學習模型的數字矩陣,明天我就會先建立一個簡單的 baseline model,確保資料處理正確,並取得一個基準分數。後續我就可以持續進行特徵篩選與相關性分析,找出最有用的特徵,減少雜訊,讓模型訓練更有效率!

 iThome鐵人賽
iThome鐵人賽