嗨大家,我是 Debuguy。
昨天我們成功讓 ChatBot 擁有了 MCP 工具,從純聊天變成能實際解決問題的行動派。但今天要來解決一個很實際的使用者體驗問題:當 LLM 在思考時,使用者完全不知道它在幹嘛!
想像這個情況:
👤 Debuguy:
@bot幫我查一下今天台北有沒有下雨(30 秒過去了...)
👤 Debuguy: 欸...是不是壞了?
(又過了 10 秒)
🤖 Bot:
@Debuguy根據中央氣象署的資料,台北今天...
「%$#@!我以為程式掛了!」
這就是典型的黑盒子等待體驗。當 LLM 需要使用 MCP 工具時,整個流程可能包含:
每個步驟都可能需要幾秒到幾十秒,但用戶完全看不到任何進度指示。
「這就像在餐廳點餐後,服務員消失了 30 分鐘,完全不知道廚房在做什麼一樣...」
當 LLM 在執行複雜任務時:
更糟糕的是,如果真的出了問題,我們也不知道 LLM 卡在哪一步,除錯變得超級困難。
讓我們先看看 prompts/chatbot.prompt:
config:
temperature: 0.2
topP: 0.95
topK: 30
thinkingConfig:
thinkingBudget: -1 # 啟用動態思考長度
includeThoughts: true # 包含思考過程!
這個 thinkingConfig 是關鍵!它讓 Gemini 把內心獨白也輸出出來,我們就能看到 LLM 是怎麼思考的。
thinkingBudget?前面的幾天我們都沒有特別講到這個設定,趁著這次講到 includeThought 一起來了解一下。
根據 Google 的官方文件,thinkingBudget 參數決定模型在生成回應時使用多少思考 token。設定為 -1 會啟用動態思考,意味著模型會根據請求的複雜度自動調整預算。
對於不同的模型,預設行為也不同:
thinkingBudget: 0 # 關閉思考功能
thinkingBudget: 1024 # 固定使用 1024 個思考 tokens
thinkingBudget: -1 # 動態思考:讓模型自己決定需要多少思考
為什麼選擇動態思考?
重要提醒: 思考 token 是計費的!定價是輸出 token 和思考 token 的總和。不過對於除錯和使用者體驗改善來說,這個成本是值得的。
Day 8 的版本(沒有串流):
app.event('app_mention', async ({ event, say, client }) => {
const messages = await formatMessages(event, client);
const response = await runFlow({
url: 'http://127.0.0.1:3400/chatFlow',
input: { messages }
});
await say({ text: response, thread_ts: event.thread_ts || event.ts });
});
這個版本用戶只能乾等,直到最終結果出現。
const chatFlow = LLM.defineFlow({
// ... schema 省略
},
- async ({ messages }) => {
+ async ({ messages }, { sendChunk }) => {
const { newMessages, history } = organizeMessages(messages);
const tools = await host.getActiveTools(LLM);
const resources = await host.getActiveResources(LLM);
- return (await LLM.prompt('chatbot')({
+ const { stream, response } = LLM.prompt('chatbot').stream({
botUserId: process.env['SLACK_BOT_USER_ID']!,
prompt: newMessages,
}, {
messages: history,
tools,
resources,
toolChoice: 'auto',
- })).text;
+ });
+
+ for await (const chunk of stream) {
+ for (const content of chunk.content) {
+ if (content.reasoning) {
+ sendChunk(chunk.reasoning);
+ }
+ }
+ }
+
+ return (await response).text;
}
);
關鍵改動:
sendChunk 參數:GenKit 提供的串流回調函數.stream() 方法:從直接調用改成串流模式content.reasoning 思考過程 app.event('app_mention', async ({ event, say, client }) => {
+ const { ts: reasoningMessageTs } = await client.chat.postMessage({
+ channel: event.channel,
+ thread_ts: event.thread_ts || event.ts,
+ text: `Thinking...`,
+ });
+
const messages = await formatMessages(event, client);
- const response = await runFlow({
+ const result = streamFlow({
url: 'http://127.0.0.1:3400/chatFlow',
input: { messages }
});
+ let accumulatedReasoning = '';
+
+ for await (const chunk of result.stream) {
+ accumulatedReasoning += chunk;
+ try {
+ await client.chat.update({
+ channel: event.channel,
+ text: slackifyMarkdown(accumulatedReasoning),
+ ts: reasoningMessageTs!
+ });
+ } catch (reasoningError) {
+ console.error('Error updating reasoning:', reasoningError);
+ }
+ }
+
+ const response = await result.output;
await say({ text: response, thread_ts: event.thread_ts || event.ts });
});
重要變化:
runFlow → streamFlow:從等待結果到接收串流slackifyMarkdown 的細節處理注意看會發現程式碼中用了 slackifyMarkdown 這個套件,這是因為 LLM 的思考過程常常包含 markdown 格式,但 Slack 的 markdown 語法有點不一樣。這個套件幫我們把標準 markdown 轉成 Slack 可以正確顯示的格式。
沒有套用前
套用之後

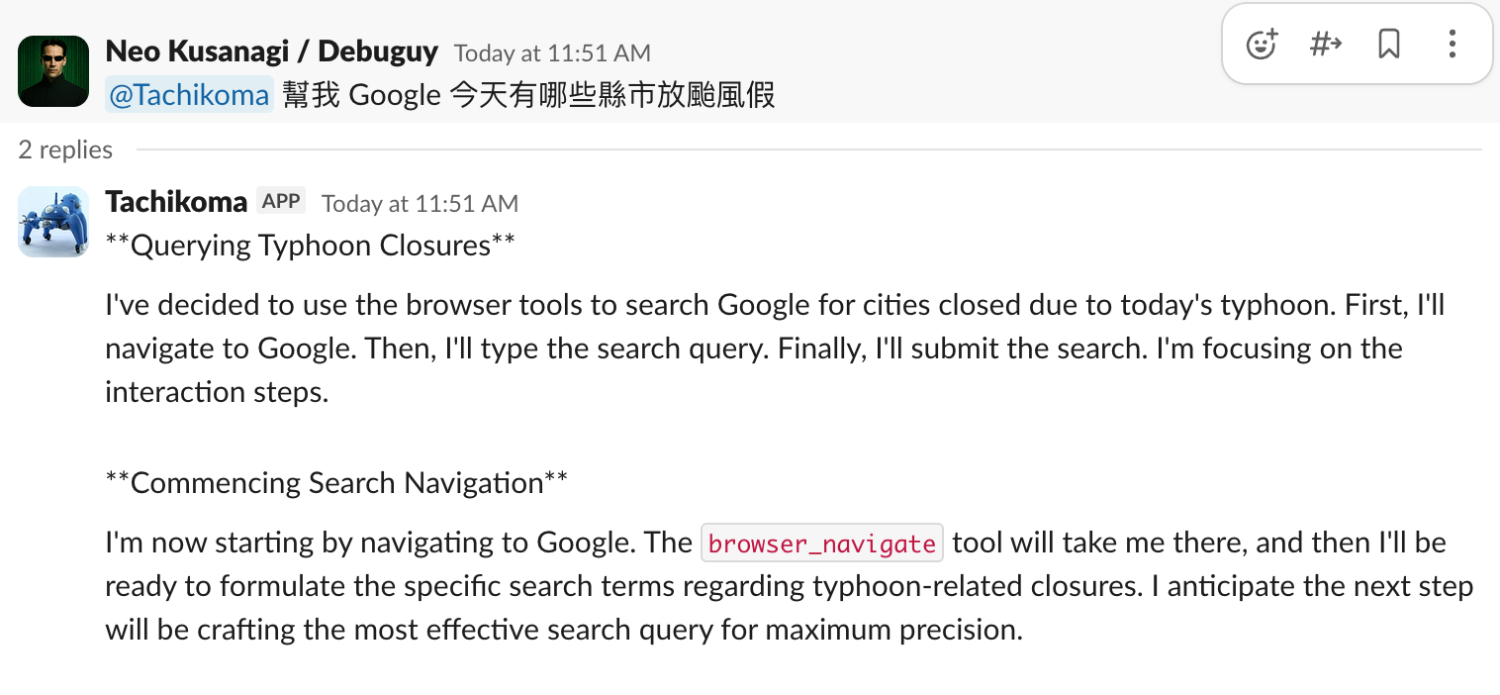
👤 Debuguy: @bot 幫我查颱風假
(漫長的等待...)
🤖 Bot: 根據人事總處網站...
使用者體驗:😰 焦慮的等待
👤 Debuguy: @bot 幫我查颱風假
🤖 Bot (思考中):
用戶想查詢颱風假資訊。我需要使用 playwright 工具來查詢人事行政總處的網站...
讓我搜尋相關的颱風假公告...
我找到了最新的颱風假資訊,讓我整理一下...
🤖 Bot (最終回覆):
@Debuguy 根據人事行政總處網站的最新資訊...
使用者體驗:😊 LLM 觀察家
體驗提升立見:
娛樂價值
同事們開始覺得看 LLM 思考很有趣:
👤 Leo: 哈哈哈,Bot 剛剛說「讓我仔細想想」,好像真的在思考欸
👤 Amy: 它剛剛還說「這個問題有點複雜」,感覺很有人性
prompt 學習
看到 LLM 的思考過程後,大家開始學會:
👤 Amy: 原來 Bot 會先分析我的問題,再決定要用什麼工具,怪不得需要時間
👤 Leo: 我學會問更具體的問題了,這樣 Bot 理解更快
即時除錯能力
當 LLM 給出奇怪回答時,直接看思考過程就知道問題出在哪:
🤔 LLM 思考:使用者問天氣...我需要用工具查詢...咦?我怎麼會想要呼叫購物工具?
「原來是 MCP 工具的 description 寫得有問題!」
Prompt 調教效率提升
今天我們成功實現了思考過程透明化,這不只是技術升級,更是使用者體驗的革命:
技術架構升級:
includeThoughts
.stream() 和 sendChunk
streamFlow + chat.update 的組合slackifyMarkdown 處理顯示格式使用者體驗提升:
開發體驗提升:
透明度不只是技術特性,更是建立信任的關鍵
當使用者能看到 LLM 的工作過程時,整個互動體驗從「黑盒子的不安等待」轉變成「玻璃屋的有趣觀察」。
這個改動看似簡單,但背後牽涉到:
「有時候 LLM 的思考過程比最終答案還有趣!」
明天我們要來處理另一個在準備落地前需要關注的問題:成本。當被上級問「LLM 解決一個問題需要花多少錢?」時,我們需要有明確的數據來回答。Token 計算、成本追蹤,這些都是 LLM 產品不可避免的課題。
完整的Day 9 原始碼在這裡,體驗一下透明的 LLM 思考過程吧!
LLM 的發展變化很快,目前這個想法以及專案也還在實驗中。但也許透過這個過程大家可以有一些經驗和想法互相交流,歡迎大家追蹤這個系列。
也歡迎追蹤我的 Threads @debuguy.dev


 iThome鐵人賽
iThome鐵人賽