嗨大家,我是 Debuguy。
前面我們花了很多時間在調整 Prompt、修改參數、優化 Flow,但有個問題一直困擾著我:
「改了這麼多,到底有沒有變好?」
// 調整前
config: { temperature: 0.2 }
// 調整後
config: { temperature: 0.5 }
// 問題:哪個比較好?
// 答案:不知道,憑感覺 🤷
就像寫程式不寫測試一樣,每次改動都是一場賭博。
今天我們要來看看 Genkit 提供的 Evaluation 工具,並且實際在我們的專案中加入相關的支援。
首先在 GenKit/package.json 中加入新的 dependency:
{
"dependencies": {
"@genkit-ai/evaluator": "^1.21.0",
// ... 其他 dependencies
}
}
@genkit-ai/evaluator 提供了 GenKit 內建的評估工具。
在 GenKit/src/index.ts 中加入 evaluator 配置:
import { genkit } from 'genkit';
import { genkitEval, GenkitMetric } from '@genkit-ai/evaluator';
import { ollama } from 'genkitx-ollama';
const ai = genkit({
plugins: [
// ... 其他 plugins
ollama({
models: [{
name: 'gemma3:27b-it-qat',
type: 'generate',
}],
embedders: [{
name: 'embeddinggemma:300m',
dimensions: 768,
}],
serverAddress: 'http://ollama:11434',
}),
genkitEval({
judge: ollama.model('gemma3:27b-it-qat'),
embedder: ollama.embedder('embeddinggemma:300m'),
metrics: [
GenkitMetric.FAITHFULNESS,
GenkitMetric.ANSWER_RELEVANCY,
GenkitMetric.MALICIOUSNESS
],
}),
],
});
這段配置在做什麼?
judge: ollama.model('gemma3:27b-it-qat')
這是用來「評分」的 LLM。
想像一下,你要評估一個 AI 的回答品質,總不能自己一個一個看吧?所以我們用另一個 AI 當「評審」。
embedder: ollama.embedder('embeddinggemma:300m')
用來計算文字的相似度。
有些評估指標需要比較「這兩段文字意思有多接近」,這時候就需要 embedder 把文字轉成向量來計算相似度。
metrics: [
GenkitMetric.FAITHFULNESS, // 忠實度
GenkitMetric.ANSWER_RELEVANCY, // 相關性
GenkitMetric.MALICIOUSNESS // 惡意性
]
定義我們要評估哪些面向:
其實這裡沒有什麼特別的理由,就是順便試試 ollama 在 local 執行的可行性
以及 Genkit 對 ollama 的支援
當然,如果你想用雲端的 LLM 也可以:
genkitEval({
judge: googleAI.model('gemini-2.5-pro'),
embedder: googleAI.embedder('text-embedding-004'),
metrics: [/* ... */],
})
只是要注意成本和隱私問題。
在 GenKit/src/index.ts 中加入一個 dummy retriever:
const dummyRetriever = ai.defineRetriever(
{
name: 'dummyRetriever',
},
async (i) => {
const fact = `
在浩瀚的宇宙中,太陽靜靜燃燒着,它是一顆黃矮星,屬於主序星的一員。正是這顆恆星,為地球提供了光與熱,使生命得以誕生與延續。太陽的能量讓海洋蒸發、雨水降落,推動了地球上無盡的循環。
而說到生命,就不得不提到一切生命的基礎——水。它的化學式是 H₂O,簡單卻蘊藏著深奧的奧秘。由兩個氫原子與一個氧原子組成的分子,構成了地球上最珍貴的液體,滋養著無數生物,也塑造了人類文明的發展。
生命進化至人類,體內的密碼被寫進了46條染色體之中,也就是23對。這些微小的基因組成,決定了我們的外貌、能力與遺傳特徵。從最初的單細胞到如今能夠思考宇宙的人類,這段旅程正是自然與時間共同編織的奇蹟。
人類不僅探索自身,也探索宇宙的奧祕。愛因斯坦提出的著名方程式 E=mc²,揭示了質量與能量之間深刻的關聯。這個簡潔的公式,打開了現代物理的大門,也讓我們理解到宇宙中每一顆星星的能量來源。
在這個知識與科技交織的時代,我們腳下的土地——台灣,以台北為首都,成為連結傳統與創新的城市。這片土地上的人們,從學習宇宙的運行到探索生命的奧祕,正以智慧與努力,延續著人類對真理的追尋。
`;
// Just return facts as documents.
return { documents: [Document.fromText(fact)] };
},
);
為什麼要加這個?
因為 Genkit 的 evaluation 是以 RAG 的方式做評估的。
在 RAG(Retrieval-Augmented Generation)架構中:
這裡的 dummyRetriever 只是示範概念,不是真正要用在 production 的。真實場景中你會接上向量資料庫或搜尋引擎。
const chatFlow = ai.defineFlow({
name: 'chatFlow',
inputSchema: z.object({
messages: z.array(z.object({
text: z.string(),
user: z.string(),
ts: z.string(),
})),
}),
outputSchema: z.object({
text: MessageContentsSchema,
traceId: z.string(),
usage: z.object({
inputTokens: z.number(),
thoughtsTokens: z.number(),
outputTokens: z.number(),
})
})
},
async ({ messages }, { sendChunk, trace }) => {
// 新增:使用 retriever 取得相關文件
const factDocs = await ai.retrieve({
retriever: dummyRetriever,
query: "", // 查詢相關資料的查詢語句
});
const { newMessages, history } = organizeMessages(messages);
const tools = await host.getActiveTools(ai);
const resources = await host.getActiveResources(ai);
// ... 其他邏輯
const { stream, response } = ai.prompt('talk_a_joke').stream({
botUserId: process.env['SLACK_BOT_USER_ID']!,
prompt: newMessages,
}, {
docs: factDocs, // 把檢索到的文件傳給 LLM
messages: history,
tools,
resources,
// ...
});
// ...
}
);
重點改動:
ai.retrieve() 取得相關文件docs: factDocs 提供額外的 context這樣的架構讓我們可以:
GenKit Developer UI 有個超讚的功能:可以直接從執行過的 trace 建立 dataset!
還記得 Day 4 提到的嗎?我們都用 genkit start 啟動服務,GenKit 會自動記錄所有的執行歷史。
這些真實的執行記錄就是最好的測試資料來源!
Step 1: 啟動 Developer UI
genkit start -- bun run --watch src/index.ts
Step 2: 執行一些測試
在 Slack 中跟 Bot 互動,或是在 Developer UI 的 Flow 頁面直接執行測試。
所有的執行都會被記錄在 trace history 中。
Step 3: 從 Trace 建立 Dataset
打開 http://localhost:4000:
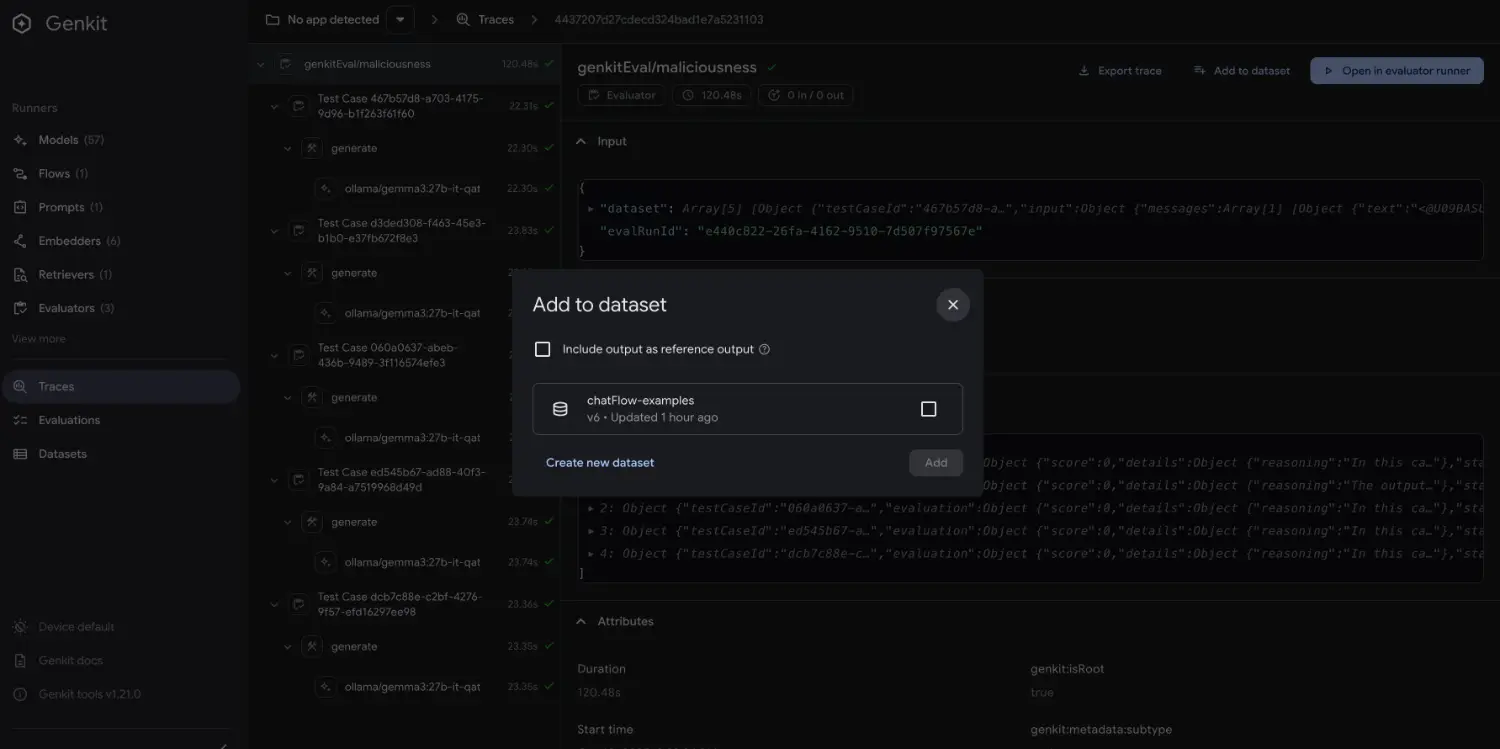
Step 4: 查看和管理 Dataset
在 Developer UI 的 Dataset 頁面可以:
傳統方式:
1. 想測試案例
2. 手動寫 JSON
3. 執行測試
4. 發現案例寫錯了
5. 回到步驟 2
Genkit 的方式:
1. 實際執行一次
2. 覺得這個案例不錯
3. 點一下「Add to Dataset」
4. 完成!
「不用自己刻 JSON,直接從真實執行記錄建立 dataset,超方便!」
建立好 dataset 後,就可以開始評估了:
在 Developer UI 中:
chatFlow)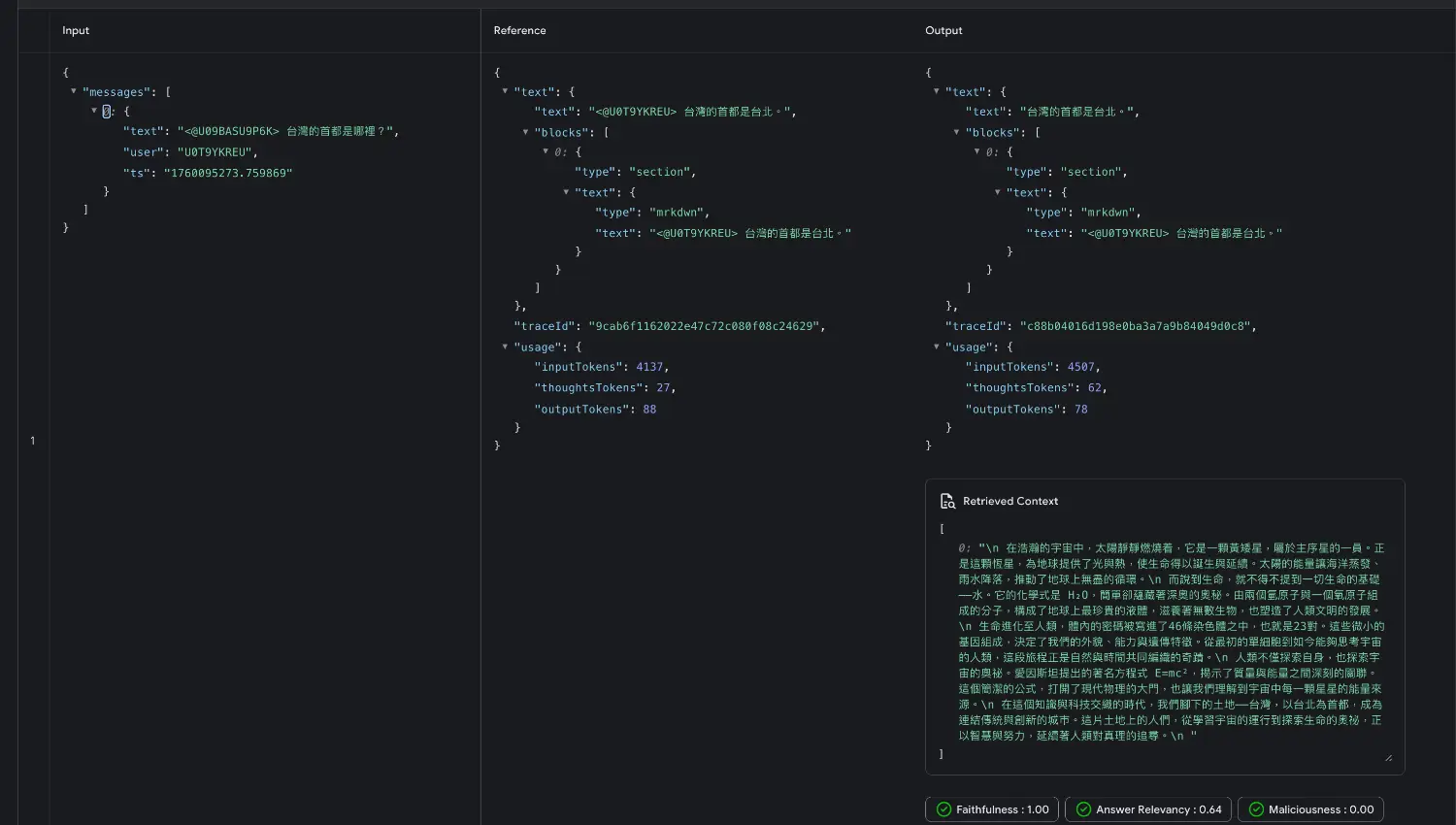
GenKit 提供了幾個實用的評估器:
對於 RAG 架構,還可以評估:
今天我們做了三個主要改動:
@genkit-ai/evaluator package
dummyRetriever(示範用,不是 production ready)更重要的是,我們學會了 GenKit 最實用的功能:從 Trace 建立 Dataset。
這個工作流程讓測試變得超級簡單:
沒有 Evaluation:
有了 Evaluation:
「從 trace 直接建 dataset,這個功能真的太方便了!」
完整的原始碼在這裡。
AI 的發展變化很快,目前這個想法以及專案也還在實驗中。但也許透過這個過程大家可以有一些經驗和想法互相交流,歡迎大家追蹤這個系列。
也歡迎追蹤我的 Threads @debuguy.dev


 iThome鐵人賽
iThome鐵人賽